python爬虫---破解m3u8 加密
破解m3u8 加密
- 本文用到的核心技术:AES CBC方式解密
-
- 准备工作
- m3u8文件详解
- 破解ts加密
- 最后
- 完整代码
本文用到的核心技术:AES CBC方式解密
基于Crypto的python3 AES CBC pcks7padding 中文、英文、中英文混合加密
具体加密解密方式请自行百度或者谷歌,不做详细说明(因为实在是很麻烦~!)
准备工作
安装方式 pip install pyCrypto
m3u8文件详解
这个m3u8文件并不是一个视频,而是一个记录了视频流下载地址的文件,所以我们需要下载并打开这个文件,用文本的方式打开之后是这个样子的

这里涉及到了一些m3u8的基础,简单来说就是这个ts文件是经过加的,加密方式是method后面的值,偏移量是iv后面的值,这里加密方式比较奇葩,是第三方网站自写的加密方式,也就是文章开头提到的AES CBC方式加密的
破解ts加密
然后我们通过浏览器断点,发现实例的代码在一个JS文件里,这个文件包含了该网站绝大多数的JS代码
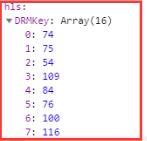
通过断点会发现一个很有用的参数 DRMKey,然后我们会发现DRMKey这个参数很奇怪,它并不是常见的一种密钥,并且通过断点得知它是这个样子的
稍微有点基础的同学可能知道,在源代码里面的是16进制的,而这里面的是十进制的,所以我们需要用到进制转换,包括后面我们还要再次转成ascii码,代码我就直接贴在这里了
def get_asc_key(key):
'''
获取密钥,把16进制字节码转换成ascii码
:param key:从网页源代码中获取的16进制字节码
:return: ascii码格式的key
'''
# 最简洁的写法
# asc_key = [chr(int(i,16)) for i in key.split(',')]
# 通俗易懂的写法
key = key.split(',')
asc_key = ''
for i in key:
i = int(i, 16) # 16进制转换成10进制
i = chr(i) # 10进制转换成ascii码
asc_key += i
return asc_key
此时我们已经找到很关键的值了 asc_key 密钥
那么现在我们所需要的2个值就已经全部找到了,asc_key和iv
不过这个iv有点特殊,是32位的,所以我们需要进行切片取前16位,16位是固定位数,必须这么取
最后
说一下我是怎么知道它是aes cbc加密的吧
逆向JS需要比较强的推测能力,既然ts文件中含有加密方式和偏移量,那么JS代码中肯定有加密的方法,因此我全局搜索的关键词就是aes decrypt ,然后发现pkcs7这种加密方式
然后查了一下pkcs7这个东西,发现它其实就是aes的一种加密方式,在已知加密方式,密钥和iv的情况下,就很好破解了,一下是完整的代码,比较简洁,爬取思路的话有一些变化,因为我发现随便打开一个视频都能获取到其他视频的标题和m3u8链接,所以我随机打开了一个免费视频的页面,并通过这个页面获取这个免费课程下所有的视频
完整代码
# coding:utf-8
import os
import re
import requests
from Crypto.Cipher import AES
from lxml import etree
class Spider():
def __init__(self):
self.asc_key = ''
def down_video(self, title, m3u8):
'''
通过m3u8文件获取ts文件
:param title:视频名称
:param m3u8: m3u8文件
:return: None
'''
ts_files = re.findall(re.compile("\n(.*?.ts)"), m3u8) # ts文件下载路径
ivs = re.findall(re.compile("IV=(.*?)\n"), m3u8) # 偏移量
for index, (ts_file, iv) in enumerate(zip(ts_files, ivs)):
ts_file = 'xxxx' + ts_file
content = requests.get(ts_file, headers=headers).content
iv = iv.replace('0x', '')[:16].encode() # 去掉前面的标志符,并切片取前16位
content = self.decrypt(content, self.asc_key, iv) # 解密视频流
open('video/%s/%s.ts' % (title, index), 'wb').write(content) # 保存视频
print('下载进度:%s/%s' % (index, len(ts_files)))
print(title, '下载成功')
def get_asc_key(self, key):
'''
获取密钥,把16进制字节码转换成ascii码
:param key:从网页源代码中获取的16进制字节码
:return: ascii码格式的key
'''
# 最简洁的写法
# asc_key = [chr(int(i,16)) for i in key.split(',')]
# 通俗易懂的写法
key = key.split(',')
asc_key = ''
for i in key:
i = int(i, 16) # 16进制转换成10进制
i = chr(i) # 10进制转换成ascii码
asc_key += i
return asc_key
def makedirs(self, path):
if not os.path.exists(path):
os.makedirs(path)
def decrypt(self, content, key, iv):
cipher = AES.new(key, AES.MODE_CBC, iv)
msg = cipher.decrypt(content)
paddingLen = msg[len(msg) - 1]
return msg[0:-paddingLen]
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.5.3738.400"
}
spider = Spider()
spider.run()