Hbase(二)进阶
Hbase(二)进阶
-
-
- 一.Hbase分区
-
- 1.预分区
- 2.row_key设计
- 二.Phoenix
-
- 1.简介
- 2.Phoenix安装
- 3.Shell
- 4.表的映射
- 5.符号数值问题
- 7.Phoenix的Java API
- 8.二级索引
-
- 8.1 全局二级索引
- 8.2 本地二级索引
- 三.Hbase整合Hive
-
- Hive建立表,Hbase也建立
- Hbase已经有表,Hive关联
-
一.Hbase分区
1.预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能
预分区的常用方法
1.手动设定预分区
hbase> create 'ns:tbl','cf',SPLITS => ['1000','2000','3000','4000']
表tbl1有5个region,再添加新的列族,也是5个region

2.生成16进制序列预分区
create 'ns:tbl','cf',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
3.按照文件中设置的规则预分区
创建splits.txt文件内容如下:
1000
2000
3000
4000
然后执行:
create 'ns:tbl','cf',SPLITS_FILE => 'splits.txt'
4.使用JavaAPI创建预分区

2.row_key设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个一个预分区的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜
rowkey常用的设计方案
1.生成随机数、hash、散列值
原本rowKey为1001的,SHA1后变成:dd01903921ea24941c26a48f2cec24e0bb0e8cc7
原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd
原本rowKey为5001的,SHA1后变成:7b61dec07e02c188790670af43e717f0f46e8913
在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的rowKey来Hash后作为每个分区的临界值
2.字符串反转
20170524000001转成10000042507102
20170524000002转成20000042507102
这样也可以在一定程度上散列逐步put进来的数据
3.字符串拼接
20170524000001_a12e
20170524000001_93i7
二.Phoenix
1.简介

Phoenix是HBase的开源SQL皮肤。可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据
Phoenix特点
1)容易集成:如Spark,Hive,Pig,Flume和Map Reduce
2)操作简单:DML命令以及通过DDL命令创建和操作表和版本化增量更改
3)支持HBase二级索引创建
Phoenix架构
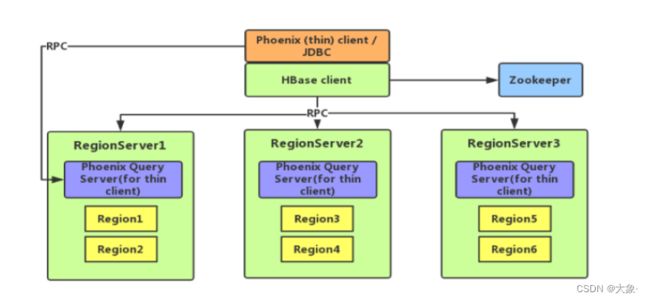
如图,是thin client,也就是客户端是轻量级的,我们在客户端写完SQL后,需要将SQL传到一个Phoenix Query Server(需要单独启动)上来将SQL解析成Hbase的Shell语句,然后就可以操作Hbase了
当然,也有普通的client,该客户端是重量级的,也即Phoenix Query Server(不需要单独启动)是包含在客户端里面的,但是由于Phoenix Query Server不在RegionServer上,它需要与ZooKeeper通信,来获取Hbase的位置
2.Phoenix安装
解压

sudo vim /etc/profile.d/my_env.sh
#phoenix
export PHOENIX_HOME=/opt/module/phoenix-5.0.0
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
复制server包并拷贝到各个节点的hbase/lib
cd /opt/module/phoenix-5.0.0/
cp /opt/module/phoenix-5.0.0/phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase-2.0.5/lib/
xsync /opt/module/hbase-2.0.5/lib/phoenix-5.0.0-HBase-2.0-server.jar
默认情况下,在phoenix中不能直接创建schema。需要将如下的参数添加到Hbase中conf目录下的hbase-site.xml和phoenix中bin目录下的hbase-site.xml中
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
分发Hbase的文件
重启Hbase
启动Phoenix(使用重量级客户端)

3.Shell
注意:在phoenix中,schema名,表名,字段名等会自动转换为大写,若要小写,使用双引号,如"student"
1.创建schema(库) 对应Hbase中的namespace
create schema if not exists pbd;
2.删除schema
drop schema if exists "pbd";
3.创建表
use pdb选择库创建表
CREATE TABLE IF NOT EXISTS student(
id VARCHAR primary key,
name VARCHAR,
addr VARCHAR);
COLUMN_ENCODED_BYTES = NONE;
首先,必须指定primary key作为row_key

由于Hbase必须有列族,phoenix自动将我们创建表的属性划分为一个列族,列族名字是数字0

COLUMN_ENCODED_BYTES = NONE; 作用是告知phoenix不要进行字段编码,没有这一行,phoenix会对字段编码,Hbase中存储的字段是我们看不懂的东西
可以指定多个列的联合作为RowKey CONSTRAINT关键字来指定
CREATE TABLE IF NOT EXISTS us_population (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
4.插入数据、修改数据
upsert into student (id, name, addr) values('1001','zhangsan','beijing');
5.查询数据
select id, name, addr from student;

可加where根据条件查询
6.删除数据
delete from student where id = '1001' ;
4.表的映射
默认情况下,直接在HBase中创建的表,通过Phoenix是查看不到的。如果要在Phoenix中操作直接在HBase中创建的表,则需要在Phoenix中进行表的映射。映射方式有两种:视图映射和表映射
方法一.视图映射(Hbase有表,但Phoenix不知道)
顾名思义就是创建一个视图
如图,我在Hbase中创建了一个表,并插入了一条数据,此时Phoenix是查看不到的

PHOENIX创建视图
create view "mydb"."tb"(
id varchar primary key ,
"info"."name" varchar ,
"info"."age" varchar ,
"info"."addr" varchar
);

drop view "xxx"; # 删除视图
就可以在PHOENIX查询了
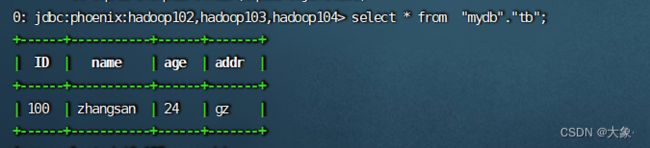
创建视图,这个视图是只读的!!删除视图,Hbase中不会删除表!
方法二.创建表(Hbase有,Phoenix不知道)
create table "emp"(
id varchar primary key ,
"info"."name" varchar ,
"info"."addr" varchar
)
COLUMN_ENCODED_BYTES = NONE;
假设没有最后一行,这样建立的表是查不到数据的,因为在Phoenix建表会对字段进行一些编码,但是Hbase并没有编码,因此两者字段是不对应的(建立视图时不会进行编码),解决办法就是建表映射表添加**COLUMN_ENCODED_BYTES = NONE;**告诉phoenix不要编码了,我建立表是什么字段,我就去Hbase中找什么字段!
删除映射表,Hbase的表也会删除!修改映射表,Hbase也会修改!注意,如果对同一张Hbase表做映射,只能二选一,要么做视图映射,要么做表映射,否则会出现同名错误!
5.符号数值问题
phoenix创建表,注意整型是Integer
create table dbnum (
id varchar primary key ,
name varchar ,
salary integer
)
COLUMN_ENCODED_BYTES = NONE;

一.phoenix存整型数据
使用phoenix插入一条数据
upsert into dbnum values('1001','zs',123456);
当时用phoenix查询

结论一:使用phoenix插入整型数据,再使用phoenix查询,整型数据时没有问题的
当使用Hbase查询,看到我们的整型数据并不是123456

结论二:使用phoenix插入整型数据,使用Hbase查询,整型数据时有问题
二.Hbase存整型
Hbase插入整型数据要用Bytes.toBytes
put 'DBNUM','1002','0:NAME','ls'
put 'DBNUM','1002','0:SALARY',Bytes.toBytes(456789) // 注意是Long类型
查询(注意要删掉1001那条数据,因为其实int格式)
scan 'DBNUM',{COLUMNS=>['0:SALARY:toLong']}

结论三:Hbase插入整型数据,Hbase查没问题
使用phoenix查询
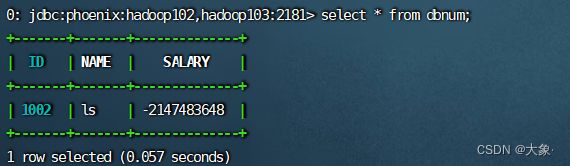
结论四:使用Hbase插入整型数据,phoenix查询有问题
为什么会这样呢?是phoenix导致的,我们存有符号的数据时,由于二进制的最高位表示符号位,0表示正数,1表示负数,但是根据字典序,0会排在1前面,也就是正数排在了负数前面,因为phoenix认为我把有符号的数正负换一下,就可以了,因此前面我们存的正数都被转成了负数
解决办法
一.尽量不要用整型类型
二.使用无符号的类型(这样无法使用负数了)
phoenix建表并插入数据
create table test1 (
id varchar primary key ,
name varchar ,
salary UNSIGNED_INT
)
COLUMN_ENCODED_BYTES = NONE;
upsert into test1 values('1001','zs',123456);
Hbase查询

三.谁存的谁查,这样就不会出问题了
7.Phoenix的Java API
thick客户端为例
<dependency>
<groupId>org.apache.phoenixgroupId>
<artifactId>phoenix-coreartifactId>
<version>5.0.0-HBase-2.0version>
<exclusions>
<exclusion>
<groupId>org.glassfishgroupId>
<artifactId>javax.elartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.glassfishgroupId>
<artifactId>javax.elartifactId>
<version>3.0.1-b06version>
dependency>
public class Thick {
Connection connection;
@Before
public void initConnection(){
try {
String url = "jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
Properties props = new Properties();
props.put("phoenix.schema.isNamespaceMappingEnabled","true");
connection = DriverManager.getConnection(url,props);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
// 查询数据 可加条件
public void select(String sql,Object[] params) {
PreparedStatement ps = null;
try {
ps = connection.prepareStatement(sql);
if(params != null && params.length > 0){
for(int i = 0;i < params.length;i++){
ps.setObject(i + 1,params[i]);
}
}
ResultSet rs = ps.executeQuery();
while(rs.next()){
System.out.println(rs.getString(1)+":" +rs.getString(2));
}
ps.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Test
public void testSelect(){
String sql = "select * from \"mydb\".\"tb\"where \"age\" > ?";
select(sql,new Object[]{"20"});
}
// 插入修改单条数据
public void insertData(String sql,Object[] params){
PreparedStatement ps = null;
try {
connection.setAutoCommit(false);
ps = connection.prepareStatement(sql);
if(params != null && params.length > 0){
for(int i = 0;i < params.length;i++){
ps.setObject(i + 1,params[i]);
}
}
ps.executeUpdate();
connection.commit();
ps.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Test
public void testInsert(){
String sql = "upsert into PDB.STUDENT (ID,NAME,ADDR) values (?,?,?)";
Object[] o = new Object[]{"101","liuy","gz"};
insertData(sql,o);
}
public void insertBatch(String sql,ArrayList[]> list){
PreparedStatement ps = null;
try {
connection.setAutoCommit(false);
ps = connection.prepareStatement(sql);
for (Object[] params : list) {
if(params != null && params.length > 0){
for(int i = 0; i < params.length;i++){
ps.setObject(i + 1,params[i]);
}
ps.addBatch();
}
}
ps.executeBatch();
connection.commit();
ps.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Test
public void testBatch(){
ArrayList[]> list = new ArrayList<>();
list.add(new Object[]{"103","liuy","gz"});
list.add(new Object[]{"104","wang","sh"});
String sql = "upsert into PDB.STUDENT (ID,NAME,ADDR) values (?,?,?)";
insertBatch(sql,list);
}
// 删除数据
public void deleteData(String sql,Object[] params){
PreparedStatement ps = null;
try {
connection.setAutoCommit(false);
ps = connection.prepareStatement(sql);
if(params != null && params.length > 0){
for(int i = 0;i < params.length;i++){
ps.setObject(i + 1,params[i]);
}
}
ps.executeUpdate();
connection.commit();
ps.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Test
public void testDelete(){
String sql = "delete from PDB.STUDENT where ID = ?";
Object[] params = new Object[]{"104"};
deleteData(sql,params);
}
@After
public void close(){
try {
connection.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
8.二级索引
一级索引就是row_key,我们查询绝大部分都是根据row_key进行查询的,所谓的二级索引,就是给除row_key之外的列建立的索引
添加如下配置到HBase的HRegionserver节点的hbase-site.xml
<property>
<name>hbase.regionserver.wal.codecname>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodecvalue>
property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.classname>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactoryvalue>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updatesdescription>
property>
<property>
<name>hbase.rpc.controllerfactory.classname>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactoryvalue>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updatesdescription>
property>
分发
8.1 全局二级索引
准备一张简单的数据表

当我们根据row_key查询时
explain select name from PDB.STUDENT where id = '101';

由于前面提到过,row_key本身就是一级索引,所以会走索引,POINT LOOKUP表示该列的取值唯一,即该列的每一行都不重复,我们可以认为此时id就是一个聚簇索引,找到了id就找到了全部的数据
创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);
我们给name创建一个索引
CREATE INDEX name_index ON PDB.STUDENT (NAME);
分析查询语句,发现是RANGE OVER,说明走了索引
explain select id from pdb.student where name = 'zs';

此时查看表,发现竟然多了一张表NAME_INDEX
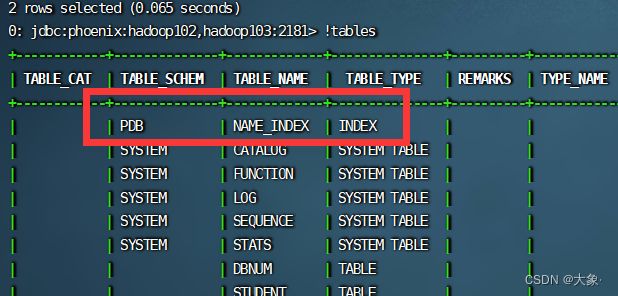
这张表的row_key就是建立索引的字段+原表的row_key,这不就是MySQL的非聚簇索引吗!!!

所谓的全局二级索引,意味着建索引会创建一张索引表。在索引表中, 将索引列与原表中的rowkey组合起来作为索引表的rowkey,当我们根据索引列时,其实是查的索引表,而不是原表!
explain select id,name,addr from pdb.student where name = 'zs';
看上面的语句,虽然name建立了索引,但是我们根据索引表只能找到索引和id,找不到addr,因此想找addr还是要全表扫描(FULL OVER)!

复合索引
先删除上面的索引
drop index name_index ON PDB.STUDENT;
我们给这张表的两个字段创建了索引,也就是一个复合索引
create index index_name_addr on PDB.STUDENT(NAME,ADDR);
可以看到建立了一张新表,并且row_key是name+addr+原表row_key组成的

explain select id,name,addr from pdb.student where name = 'zs' and addr = 'gz';

很明显走了索引
explain select id,name,addr from pdb.student where addr = 'gz';

进行了全表扫描,创建联合索引的规则是首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后对第二个字段进行排序,现在直接使用第二个字段查询,导致索引失效了,不符合最左前缀法则
explain select id,name,addr from pdb.student where addr = 'gz' and name = 'zs';

走了索引,原理和MySQL一样,因为会有优化器,所以顺序无所谓的
8.2 本地二级索引
先删除上面的二级索引
drop index INDEX_NAME_ADDR on pdb.student;
我们创建一个本地二级索引,就是在index加个local即可
create local index idx_local on pdb.student(name);
分析这条语句,竟然发现没有FULL OVER,而是RANGE OVER!
explain select id,name,addr from pdb.student where name = 'zs';

我们查看Hbase中的数据,原来本地二级索引就是把索引列+row_key放到了原表中

这样我们根据索引name,虽然只找到了name和id,但是我们不用回表了,直接在当前表定位到对应的id,索引不会是FULL OVER
三.Hbase整合Hive
在hive-site.xml中添加zookeeper的属性,如下:
<property>
<name>hive.zookeeper.quorumname>
<value>hadoop102,hadoop103,hadoop104value>
property>
<property>
<name>hive.zookeeper.client.portname>
<value>2181value>
property>
启动hive
nohup /opt/module/hive/bin/hive --service metastore &
nohup /opt/module/hive/bin/hive --service hiveserver2 &
Hive建立表,Hbase也建立
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");

不能将数据直接load进Hive所关联HBase的那张表中
在Hive中创建临时中间表,用于load文件中的数据
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
向Hive中间表中load数据
hive> load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;
通过insert命令将中间表中的数据导入到Hive关联Hbase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
Hive:
hive> select * from hive_hbase_emp_table;
HBase:
Hbase> scan 'hbase_emp_table'
Hbase已经有表,Hive关联
就是多了一个EXTERNAL字段,告知Hive它只管理表元数据的生命周期,不会影响Hbase中的数据
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");