实时工业大数据产品实践——上汽集团数据湖
【IT168 专稿】本文根据侯松老师在2018年5月12日【第九届中国数据库技术大会】现场演讲内容整理而成。
讲师简介:

侯松,上汽集团资深大数据架构师、Oracle ACE、PMP、北美寿险管理师,《高并发Oracle数据库系统的架构与设计》作者,ACOUG社区、PG社区核心成员。现就职于上海汽车集团股份有限公司,负责大数据中心数据服务、智能引擎、实时计算平台的研发,产品化及推广。所负责的上汽数据湖产品,已在上汽集团旗下多家企业实施,用以车联网应用的落地。微信公众号:madaiba,个人网站: http://www.housong.net
摘要:
立足于汽车制造与服务为代表的制造行业,服务于车联网与工业大数据相融合的应用场景,采用开源软件架构,自研发实时大数据集成平台。降低企业使用大数据技术的成本,为数据分析师、业务分析师提供更高效易用的工具,加速数据应用的建设和推广,并提供全字段金融等级3DES加密,自动无感知的密钥更新,防止密钥泄露。单元格级别权限控制和数据脱敏访问。
正文:
对于技术人而言,没有任何一项技术可以解决所有问题。很多时候,我们做数据库和大数据产品要以落地为目的,因此在整个过程中,我们需要分清楚want和need是什么。我今天给大家分享的主题就是我与整个团队从无到有打造上汽数据湖的故事。
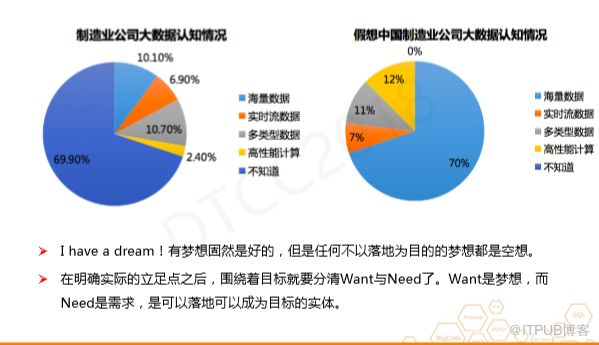
上图左边所示为某外国咨询公司对制造行业大数据认知状况的调研,70%的用户表示并不知道大数据的概念。如上右图是我假想的中国制造业公司对大数据的认知情况,但在互联网企业,几乎所有用户对于大数据都有一定认知,专业人士可能还会说到多类型、高性能计算等关键词。
在上汽数据湖的实践过程中,我们总结了整个过程的痛点所在,这不一定适合所有行业,但在工业制造行业应该还是比较适合。第一个挑战是数据集成,因为上汽旗下有多个汽车品牌,因此我们遇到的最大问题就是企业壁垒,当然这不仅仅是技术上的问题。
第二个挑战是数据质量。以前在金融行业时,我们很少关心数据质量,因为金融领域的数据质量比较高。但是,制造业的数据质量比较凌乱,甚至可以说是一个很差的状态。
第三个挑战是技术成本。很多行业都习惯于依赖供应商的力量快速打造一个平台,但这样做势必会牺牲企业技术和人才沉淀的机会,久而久之会形成人才缺失。经过两年的努力,上汽终于弥补了人才和技术层面的缺失。
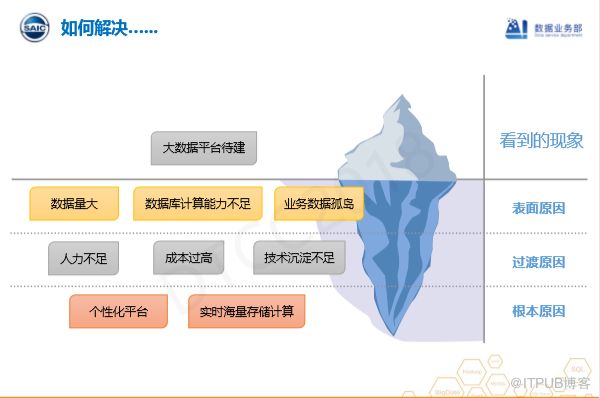
经过整个团队成员的头脑风暴,我们设计了一个冰山模型,主要目的在于设计一个用于处理实时海量数据计算平台,关键在于加入了数据加密,也就是数据权限管理等功能。因为如果要打破企业壁垒,一定要保证数据安全,因此需要通过多租户技术实现用户数据隔离。但是,依靠传统的Hadoop等技术无法实现该功能,唯一能提供的就是kerberos安全认证,这对于用户数据存储意义不大。
基于上述几点,我们研发了上汽数据湖。简单来说,上汽数据湖的不同之处在于引入了多元化数据。对制造业而言,我们会有很多数据源,并且内部有各种传统关系型数据库、新型NoSQL数据库甚至是一系列Excel表格、PDF文件等,我们面临的这种多元化不仅仅是技术多元化,还有业务多元化。当数据实时接入进来以后,我们会对数据进行松耦合全量数据存储。对传统企业而言,数据耦合性非常强,领域建模的模型是存在的,并且数据在结构上具有相似性,需要数据架构师整理一套完整的数据字典。
整个过程,我们会根据规范避免将数据湖变为数据沼泽,因为数据沼泽内部存储的内容比较乱,其实没有什么价值。企业更关心的往往是数据存入数据湖之后可以创造什么价值,这也是我们做的比较多的工作。
对互联网企业而言,大数据平台可能早就处于成长期或者成熟期,但是对于上汽而言,我们从无到有建立了整个大数据平台。我们将整个过程分为四个时期:蛮荒期、萌芽期、成长期和成熟期。
简单来说,蛮荒期就是只有一个数据库或者数据仓库,进行简单的数据分析生成数据报表即可。
萌芽期,我们开始认识到HDFS和大数据平台的概念。我们自己找供应商搭建了一个大数据平台,把数据通过sqoop方式导入整个平台。
成长期,我们真正开始将数据库跑不出来或者跑得较慢的的应用放到数据平台上。
成熟期,上汽第一次开始有了数据湖的概念,把很多下游企业的数据统一接入数据湖。并且可以保证数据的可靠性、安全性以及数据安全加密、数据权限管理和多租户云服务。上汽数据湖的两大亮点为实时数据接入和计算,数据安全性和多租户管理。
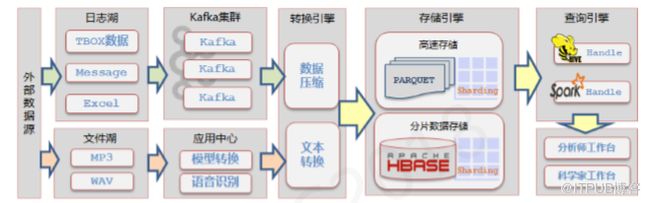
整个数据湖的实现主要分为五个步骤:一是数据接入、异构数据融合和每秒百万级数据接入。对于上汽而言,比较幸运的是Tbox的数据不像互联网用户日志数据,它还是比较规整的,数据质量相对较高。二是数据备份及容灾功能,数据快照及数据融合等;三是单位各级别统一权限管理、金融级自动化数据加密和敏感数据脱敏;四是海量数据机器学习及数据挖掘系统;五是无间断动态扩容、高压缩文件存储、标准SQL接口和灵活扩展。
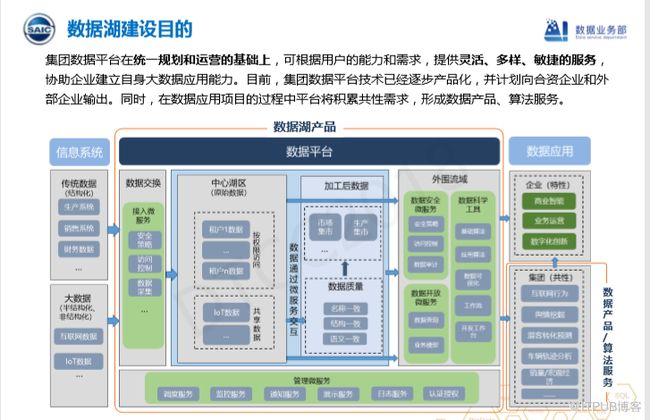
上图可以说是典型的传统制造业向互联网转型的架构,中间是数据湖产品,左边是信息系统也就是IT系统,主要存储传统关系型数据库和NoSQL数据库的数据,我们称为结构化数据库,因为这部分数据比较容易结构化。下面这部分数据大部分属于半结构化数据,比如IOT数据、工业大数据等。
数据进来之后会经过一系列微服务控制进到中心湖区,中心湖区根据不同企业按租户隔离数据,不同类型的数据按照不同的存储要求放到不同湖区。这部分数据不区分价值密度,暂时不进行任何清洗。当数据进入中间层,‘’我们开始进行数据加工,对数据质量进行干预和清洗,最终形成数据集市。对于价值密度不是很大的工业化大数据,我们可以考虑采用低廉的存储方式,但是性能可能会比较差。如果搭建集群,虽然存储能力比较强,但是CPU和内存会成为弱点。对于价值密度较高的结构化数据,我们需要对CPU和内存能力进行较强控制,因此这个地方需要做到分而治之。

当数据加工之后,我们就可以把两部分数据融合,外围流域主要使用SandBox,因为传统的Hadoop集群对用户隔离以及多租户实现并不友好。因此,我们实现了计算和存储分离。搭建若干个集群作为存储层,牺牲了部分性能做多租户分离。传统关系型数据库基本就是典型的Oracle、DB2、SQL Server和MySQL四个,部分数据来源于这四大数据库。

从逻辑上区分数据湖的概念,主要分为三个方面,一是数据接入;二是中心湖区存储;三是外围流域。简单来说就是入、存、出的概念。
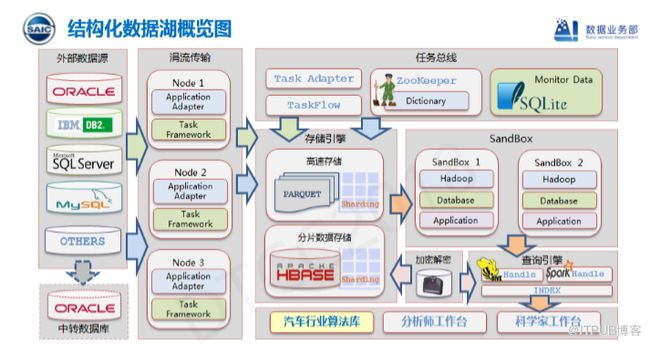
除了上述几大数据库,也有客户希望可以将Mongo接入整个大数据平台,我们设计了涓流传输区,主要用于将数据从一个数据库存储到另一个目标,传统方式主要有两个过程:一是全量,二是增量。我们先通过全量方式将历史数据传输过去,然后通过增量方式最终达到两边数据的一致。但是,涓流传输基本打破了这个概念,全量和增量并行进行。因为大数据和数据库应用是不同的,大数据在做统计分析时并不要求数据的绝对一致性,因此当数据量达到一定程度时,我可以牺牲部分一致性。
在存储引擎部分,我们最开始依靠HBase,通过Hive外部表方式访问HBase,或者通过Impala外部表方式访问。但是,这种做法的性能会变得很差,因为关系型数据库相对来说表行数比较少,这种检索还是比较有用的,但在大数据场景下并不适用。因此,我们需要针对这类场景进行定制,如果我们把它放到region Server中,性能又会受到影响,我们通过分片根据实际情况将应用切分成多个region,但这种方式的性能依旧不佳,我们决定进行更深程度的定制。
在最终方案中,我们选择使用HBase,但在其中加入数据加密功能。这部分的静态数据使用Parquet,动态数据则是自定义的文件格式,最后拼合Parquet和动态文件以支持SQL查询。最终方案的整体性能基本可以达到Spark on Parquet的程度,而且可以实现部分Kudu的功能。整个过程相对来说比较复杂,我们通过任务适配器也称为任务总线控制整个过程,我们将数据字典的信息存放在Zookeeper之中,最终通过Zookeeper维护,包括整个过程产生的多源数据,整个任务总线会生成工作流引导数据存储,模拟数据会通过嵌入式开发存放到SQLlite之中,最后的数据输出和用户应用通过SandBox实现。
在输出和查询方面,我们主要有两种方式:一是Hive,二是Spark。虽然Hive的性能一般,但是为了保留兼容性,我们最终选择将Hive留下。当然,如果追求性能,Spark依旧是最好的选择。
此外,大家可能比较关心IOT数据如何存储。除了数据湖,我们还构建了日志湖和文件湖,由于TBox数据比较规整,因此我们将其定义为日志湖。对于半结构化数据应该如何呈现呢?很多人可能会考虑使用MongoDB,当数据量不是特别大时,MongoDB是比较好用的,当数据达到一定量级,MongoDB虽然说是分布式的,但它会形成MongoDB集群,最后通过特定格式存储到数据库中,这个过程称为入库,需要保持数据的一致性,整个过程需要耗时良久且存储下来的数据量甚至大于原始数据量。因此,我们最终决定通过kafka的方式完成并预先对数据进行压缩。
我们知道HDFS存储默认是三份,就算手动调成两份,存储量依旧非常大,成本很高,但是整体上来说一定是最经济的解决方案,这时我们需要牺牲部分查询性能,从而实现查询过程中对zip文件的访问。我相信大家一定都听过CSV解决方案,其实这个方案就相当于把csv做成zip包,因为做zip数据统计分析并不是并发很高的事情,原始数据需要通过工作流中的个别join输出到一定格式后才可以访问。
接下来,我来介绍一下文件湖,相比于结构化数据湖和日志湖,文件湖的重要性不是那么高,文件湖同样是企业数据资产存储的一部分,同样在HBase中做,最后转换成文本存储下来。
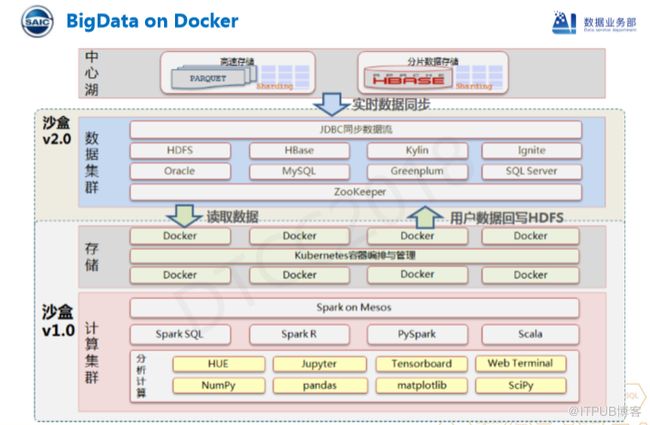
SandBox的概念不是上汽第一个提出来的,上汽也不会是最后一个使用者,SandBox在上汽主要经过了两个阶段,我们有两大集群:存储集群和计算集群。计算集群按照不同的功能通过Spark on Mesos的方式实现一些Spark SQL 、Spark R 、PY Spark 、Scala等计算,但对于数据科学家而言,他关心的可能只是用到的算法,比如Tensorflow等等。我们工作台的原形是 jupyter notebook ,它可以做一些个性化定制。存储部分,我们主要使用Kubernete管理docker,把需要存储的内容以docker image方式存放,然后通过kubernete编排、管理。针对Docker存在的数据状态问题,我们开发了用户数据回写功能,用户数据需要提供一个目录,我们用Docker映射本地目录,通过HDFS协议把它回写到HDFS,甚至会有一些第三方的HBase。
SandBox 2.0时期,我们会有一些数据库应用,我们将用户数据回写并生成报表,我们使用Kylin做聚合产品会比较快,使用Ignite跑一些Spark SQL,因为它是一个分布式内存数据库并支持Spark接口。

上图是一个性能对比,橙色为Hive(Parquet),蓝色的为Spark(Parquet),紫色部分是DataLake,这不是最新版本的性能测试,但可以看出一些差距。通过TPC-H基准查询,我选择了三个经典场景q1、q7、q13,我们可以看到就查询性能而言,DataLake的查询性能是Hive的10-20倍,与Spark(Parquet)差不多。

在实时接入方面,上图的波形变化体现了接入Oracle、MySQL、SQL Server三个数据库的实时情况。
在安全管理层面,我们的数据安全管理页面可以完成加密方式、脱敏控制、列访问权限、行查询权限的设置,可以达到单元格级别的加密。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31077337/viewspace-2200308/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31077337/viewspace-2200308/