Pytorch实现RNN,LSTM和GRU超详细代码参数解析
本文针对使用pytorch实现RNN,LSTM和GRU对应参数的详细解析,相信通过阅读此文章,能够让你对循环神经网络有一个很清楚的认识。也希望你能耐心看完,相信会对你有很大的帮助。大佬直接跳过。这篇文章分析的会特别基础。
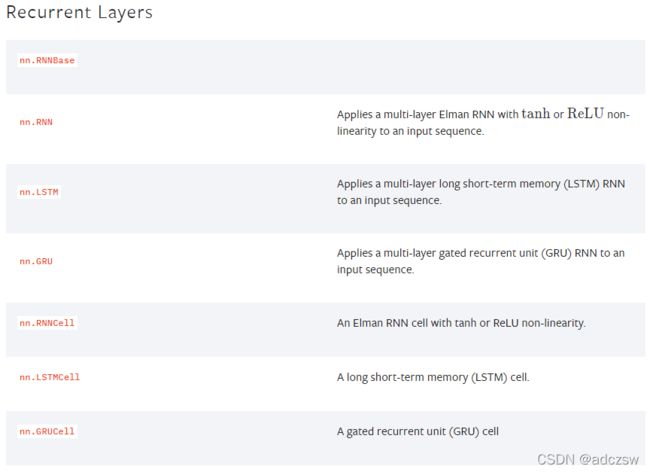
Pytorch官网提供的循环脑神经网络总共7个函数,nn.RNN、nn.LSTM、nn.GRU可以实现多层的循环神经网络,而nn.RNNCell、nn.LSTMCell、nn.GRUCell只提供一个网络层。
官网:LSTM — PyTorch 1.10.0 documentation
7个函数如下图所示:
- Import torch.nn as nn
- rnn = nn.LSTM(10, 20, 2)
- input = torch.randn(5, 3, 10)
- h0 = torch.randn(2, 3, 20)
- c0 = torch.randn(2, 3, 20)
- output, (hn, cn) = rnn(input, (h0, c0))
上面的是官网提供的一个LSTM的示例,我们通过这个去解析他的参数。
第一步:构造一个网络结构:
构造一个两层的循环神经网络层:lstm = nn.LSTM(10, 20, 2)。下面图a和图b分别展示了一层和两层的网络结构。
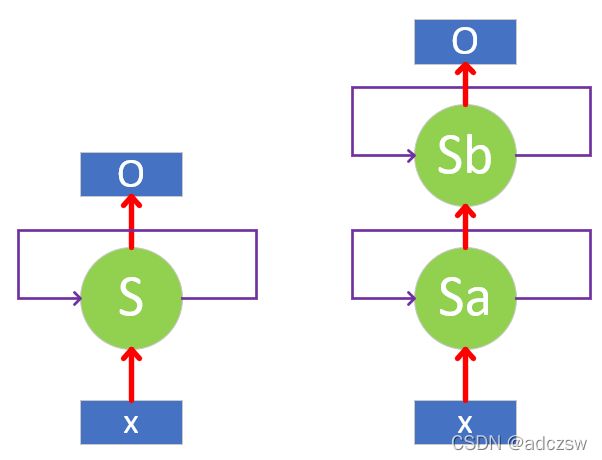
图a 图b
图a:一层网络,指得是只有一个隐藏层;S就是隐藏层。
图b:两层网络,有两个隐藏层,将第一个隐藏层直接输入作为第二个隐藏层的输入。Sa和Sb两个隐藏层。
像上面的例子,指制定了3个参数如下,这也是必须指定的3个重要参数。

上图是官网对nn.LSTM()中参数的介绍,还有其他参数,只是这里没有列出来。这包含3个参数。
Input_size:10:输入模型的向量的维度,也就是图1中的x的维度,也就是一般深度学习中的one-hot对应的embedding的维度,这里的10表示x的维度是10.
Hidden_size:20:隐层的节点个数,也就是x经过一个矩阵变换,维度变成了20,也就是一般深度学习当中某一层的隐藏节点个数,这些都是一样的。
Num_layers:2:就是我们要的两层循环神经网络的参数。如图b所示。
第二步:初始化数据:
构造好了网络,在我们把训练集样本送入模型前,我们还有初始化一些参数。切记,循环神经网络只需要定义网络的层数和隐藏层节点个数,我们一般所看到的网络同一层进行展开后,可能有好几个节点,这是一个节点不断的循环的结果,同一层展开的节点的个数是和你的训练集一个样本的长度是有关系的,比如一句话是10个字,单个字就是一个对应的embedding,那么同一层展开就是10个节点。也就是说在同一层中网络中的参数(w,b)是公用的。这是非常重要的。
RNN,GRU和LSTM的数据输入基本是一样的。 其中RNN和GRU一模一样,只有h_0(隐藏状态)和input(训练集),而LSTM数据输入参数比前两个多了一个细胞状态,也就是c_0。
RNN和GRU的数据输入参数:
LSTM的数据输入参数:

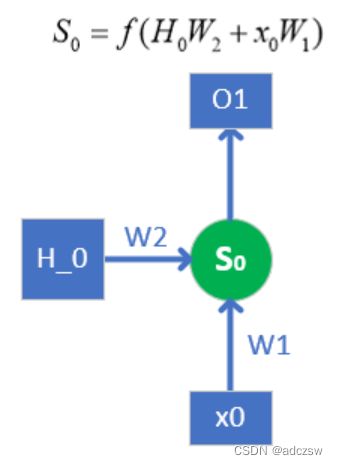
图1,单个网络结构
图1是单个网络结构,这表示的是一个普通的单层非双向RNN的结构。放在这里以方便下面的理解。
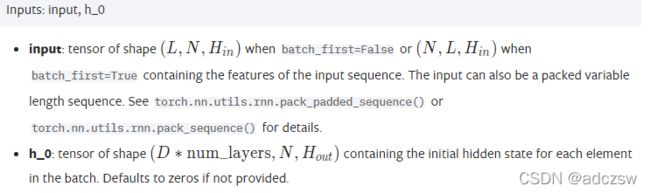
Input(L, N, Hin )是一个三阶的张量,它就是我们的训练集:
L:序列的长度,也就是我们这次训练的一个样本的长度,也就是说,L有多长,图一中单层网络就要向有展开多少次。比如图2,就是L等于5,向右展开了5次,计算5次。
N:batch_size,也就是我们一次训练的样本的个数,这个值越大,也就是同批次训练的样本越多。
Hin:输入的尺寸,也就是输入的特征向量的维度,图1中x0的维度,这个值和Input_size是同一个值。
实际x0是input中的第一个子张量,也就是L序列索引为0的张量。随着往右逐渐展开索引+1。
h_0(D*num_layers, N, Hout)是一个三阶张量:
如图1所示,要想得到S0,也就是第0个隐藏节点的值,结合图1上的公式,有两个参数需要传入,一个是h_0,另一个x0,x0是我们的训练数据是知道的,而h_0是需要初始化的。
D:表示如果是双向网络,就是2,单向网络就是1。我们知道双向网络,左侧有一个h0,右侧也需要一个h0,在此案例中,我们建立的是单向网络,所以D=1.
num_layers:表示我们的网络是多少层,和前面的nn.LSTM()中的num_layers是同一个值。因为每层网络都要初始化一个h0,在此案例中,我们是2层网络,所以这个值是2.
N:batch_size,也就是我们一次训练的样本的个数,和Input(L, N, Hin )中N保持一致,
Hout:隐层的节点数量hidden_size,因为S0会作为计算下一个S1的h0,而W2参数是在同一层的循环网络中是通用的,不变的,所以S0和S1的维度是一样的,所以W2参数的尺寸也是(Hout* Hout),S0的维度是Hout,所以h0的维度也必须是Hout。这样说,就是此处的h0与S0关系就相当于下一次循环计算时的S0与S1的关系,所以h0维度与S0维度必须一样,否则无法循环计算,h0维度就是隐藏节点个数。因为要得到S0,必须h0*W2加上x0*w1,所以w1的参数尺度就是Hin* Hout。最后再加一个激活函数。
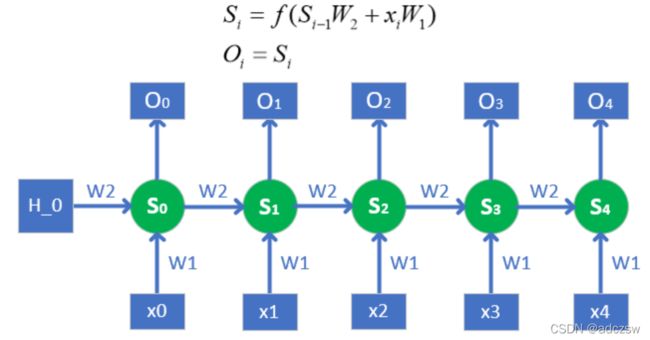
图2 单层循环网络结构
我们在图1中初始化了h0,协同x0计算得到S0,S0作为下一次的h0和x1共同计算得出S1.最后再次说一次,在同一层网络中W2参数和W1参数永远都是一样的,当然了也有偏置参数。不通的W只存咋与不通层的网络中。
第三步:进行计算
在网络构建和一些参数初始化结束之后,我们就要将数据送入模型中,官网给出的一个示例,我们看到第5行,input和h0,c0输入模型后,得到output,hn和cn。
如果是RNN和GRU模型,前向传播如下:
output, hn = rnn(input, h0)
LSTM就多了个c0和cn:
output, (hn, cn) = rnn(input, (h0, c0))
我们在图2中可以看到隐藏节点Si的值的尺寸其实【batch_size,hidden_size】这样一个二阶张量,一个方向传递给Oi,一个方向传递Si+1,但是考虑到网络如果是双向的循环网络,所以Oi的尺寸就变成了【batch_size,num_directions*hidden_size】,考虑多层网络这和双向网络,Hn就变成了【D* num_layers,batch_size, hidden_size】,在隐藏节点基础上添加了双层网络和网络层数两项。
但是最后的output和Oi的关系是,将所有的Oi组合起来就得到了output,所以output的尺寸是【L,N,D∗Hout】==【L,batch_size,num_directions*hidden_size】。所以说对于RNN来说隐藏节点的值和Oi,hn(hi)是一样的,只是加了一两个维度,将多组数据组合起来,GRU就是在隐藏节点计算完之后,将数据往Oi或者下一个hn(hi)传递时,加了个滤波的门(系数)。LSTM就是计算得到的hn和cn,hn就是Oi,hn和cn一块不变传入下一次计算。
上面说的是RNN和GRU的参数,LSTM就是在同一层的网络结构中,往同层的下一个循环节点中增加了一个c_0,也就是细胞状态,所以在初始化时,要初始化一个细胞状态就是c_0。还有一个就是在输出时,多了一个cn。我们下来看一下这两个。
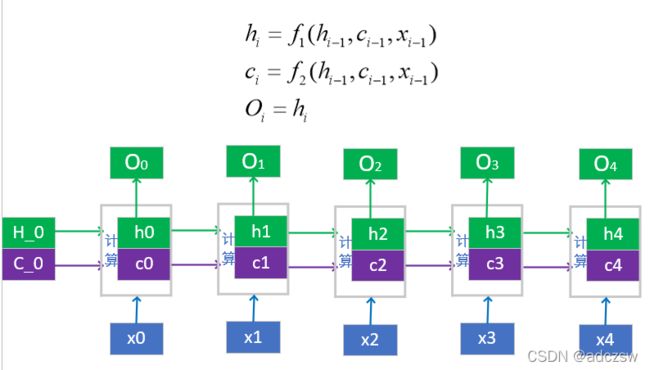
可以看到初始化的H_0与C_0和x0共同计算得到h0隐藏状态与c0细胞状态,最终输出的O0就是h0。
两层的LSTM模型如下图所示:
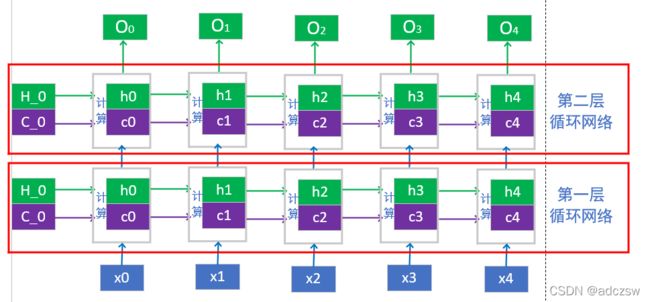
可以看到第一层网络生成的Oi作为第二层网络的Xi,传入第二层网络,这里要注意第一层的参数和第二层的参数是不一样的,包括初始化的H_0和C_0。
- h0 = torch.randn(2, 3, 20)
- c0 = torch.randn(2, 3, 20)
从这里对于初始化h0和c0就可以看到,张量的第一个参数是2,就表明对每一层LSTM的h0和c0都进行了初始化。