python爬虫设计实验
python爬虫设计实验
- 一、 任务描述
- 二、 任务目标
- 三、 任务环境
- 四、 任务分析
- 五、 任务实施
-
- 步骤1、爬取准备
- 步骤2、编写爬虫
- 步骤3、程序运行
未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计3415字,阅读大概需要3分钟
一、 任务描述
本实验任务主要基于ubuntu完成python对网页的爬取,完成对所需数据的采集。
通过完成本实验任务,要求学生掌握python语言对网页数据的采集技能,为以后从事数据采集工程师奠定基础。
二、 任务目标
完成实验实例,python语言爬取小说名字和小说介绍。
三、 任务环境
Ubuntu、Python2.7.12、Tomcat
四、 任务分析
打开获取数据的页面,进行对数据检索分析,找到要获取的数据,构建爬取思路。
通过urllib2对页面进行请求,通过BeautifulSoup对请求的页面进行解析。
对解析完的数据进行选取,获取重要数据。
♥ 知识链接
urllib2模块
通过Python urllib2模块 BeautifulSoup来实现一个简单的爬虫;urllib2模块用来请求网址,用BeautifulSoup来解析页面获取信息;通过Python输出我们需要的内容。
五、 任务实施
步骤1、爬取准备
点击桌图标【Xfce Terminal】或者鼠标右键点击【Open Terminal Here】打开终端
【cd /simple/tomcat/bin/】进入Tomcat目录下,执行【./startup.sh】开启Tomcat;如图1所示:
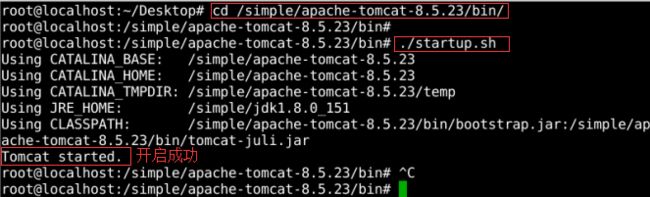
图1 开启Tomcat
打开火狐浏览器【 http://localhost: 8080/test/xiaoshuo.html 】验证Tomcat是不启动成功,这也是我们要爬取的网页;如图2所示:
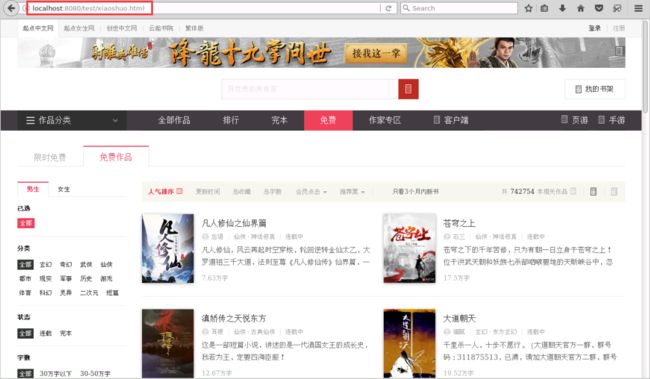
图2 验证Tomcat
步骤2、编写爬虫
再打开一个终端(鼠标右键打开终端,会默认在桌面目录,点击图标Xfce ,路径会默认在根目录下),【cd /】进入根目录;执行命令【vim PyDemo.py】创建py文件,导包和定义url如图3所示:
1. #!/usr/bin/env python
2. #-*- coding:utf-8 -*-
3. import urllib2
4. from bs4 import BeautifulSoup
5. #爬取的URl
6. url = "http://localhost:8080/test/xiaoshuo.html"

图3 获取url
打开火狐浏览器按【F12】,找UserAgent;如图4所示:
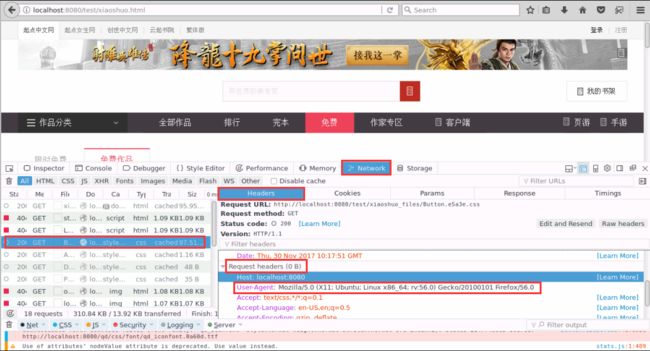
图4 提取UserAgent
在代码中输入头部,代码如下;如图5所示:
1. #!/usr/bin/env python
2. #-*- coding:utf-8 -*-
3. import urllib2
4. from bs4 import BeautifulSoup
5. #爬取的URl
6. url = "http://localhost:8080/test/xiaoshuo.html"
7.
8. UserAgent = "Mozilla/5.0 (X11; Ubuntu; Linux x86 64;rv:56.0) Gecko/20100101 Firefox/56.0"
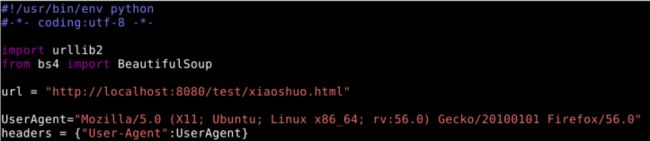
图5 编写UserAgent
开始爬取网页,代码如下;如图6所示:
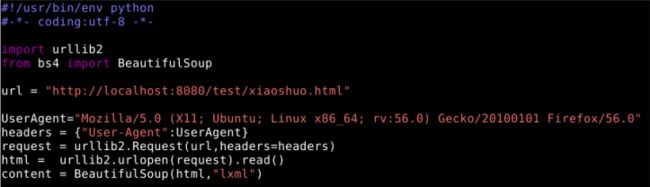
1. #!/usr/bin/env python
2. #-*- coding:utf-8 -*-
3.
4. import urllib2
5. from bs4 import BeautifulSoup
6. #爬取的URl
7. url = "http://localhost:8080/test/xiaoshuo.html"
8. #用户代理(认证我们是一个人不是一台机器去浏览网页)
9. UserAgent="Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:56.0) Gecko/20100101 Firefox/56.0"
10. headers = {"User-Agent":UserAgent}
11.
12. request = urllib2.Request(url,headers=headers)
13. html = urllib2.urlopen(request).read()
14. content = BeautifulSoup(html,"lxml")
图7 爬取页面
获取要爬取小说名字和介绍的标签;先点击红框中的箭头,选择其中一个小说名字,找到所在的标签,在点击介绍,发现他们在同一个div中,记住div信息(div class=“book-mid-info“);如图8所示:
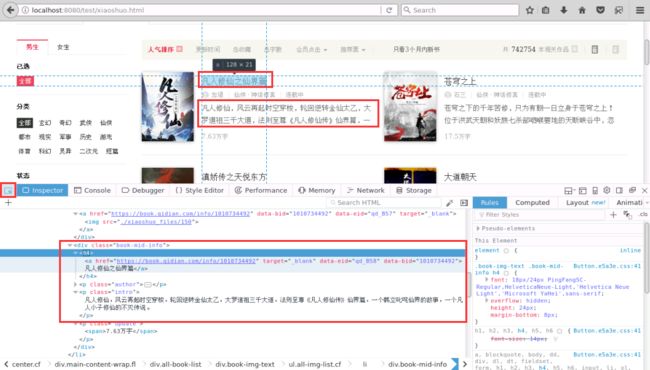
图8
在content中有页面的所有信息,但是不是我们全部想要的,爬取我们要的小说名字和介绍;
代码如下,其中标签信息是从上步骤中获取的,如图9所示:
1. #!/usr/bin/env python
2. #-*- coding:utf-8 -*-
3.
4. import urllib2
5. from bs4 import BeautifulSoup
6. #爬取的URl
7. url = "http://localhost:8080/test/xiaoshuo.html"
8. #用户代理(认证我们是一个人不是一台机器去浏览网页)
9. UserAgent="Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:56.0) Gecko/20100101 Firefox/56.0"
10. headers = {"User-Agent":UserAgent}
11.
12. request = urllib2.Request(url,headers=headers)
13. html = urllib2.urlopen(request).read()
14. #爬取页面所有内容
15. content = BeautifulSoup(html,"lxml")
16. #获取div中的信息,一个div中只包含一本小说,我们要获取所有的div中信息
17. content_data = content.find_all("div", class_="book-mid-info")
18. #遍历所有div信息从中获取小说信息
19. for con in content_data:
20. name = con.find("h4")
21. #获取小说名字
22. fic_name = name.text
23. #输出小说名字且转换为utf-8 可能会出现乱码
24. print fic_name.encode("utf-8")
25. #同理获取小说介绍信息,因为在div中有多个P标记,添加它的class唯一标记查找
26. ps = con.find_all("p",class_="intro")
27. for mm in ps:
28. #输出小说介绍且转换为utf-8 可能会出现乱码 strip()去除空白行
29. print mm.text.encode("utf-8").strip()

图9 爬取小说
步骤3、程序运行
保存代码(注意代码保存目录),因系统原因为了避免乱码,我们修改终端编码为(utf-8)暂时识别中文;如图10所示:
图10 修改终端编码
通过鼠标右键打开终端【cd /】进入根目录下,执行【Python PyDemo.py】;如图11所示:
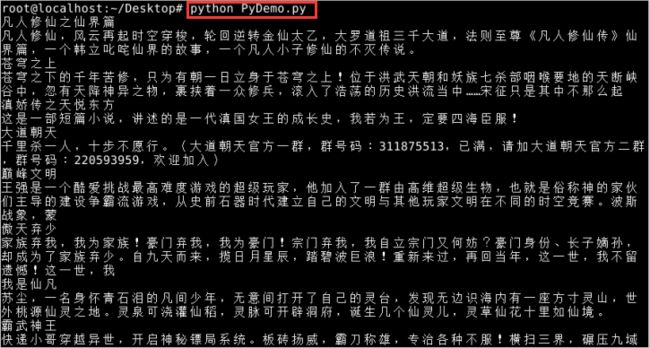
图11 运行结果
代码运行成功,我们把数据保存到txt文件中;【vim PyDemo.py】添加代码如下;如图12所示:
1. xiaoshuo = open("/simple/xiaoshuo.txt","w")
2. ……#省略的代码
3. ……#省略的代码
4. ……#省略的代码
5. xs_centent = mm.text.encode("utf-8").strip()
6. print xs_centent
7. xiaoshuo.write(fic_name+"
8. "+ xs_centent+"
9.
10. ")
11. xiaoshuo.close()
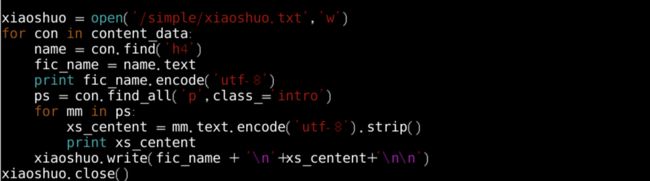
图12 编写保存代码
运行代码【python PyDemo.py】;如图13所示:

图13 代码报错
报错了,是什么问题呢?原因就是python的str默认是ascii编码,和unicode编码冲突,就会报这个标题错误;【vim PyDemo.py】在代码上面添加代码;如图14所示:
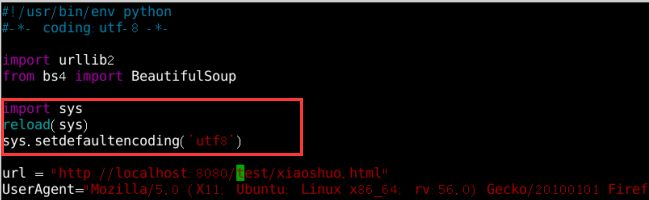
图14 修改错误
再次运行【vim PyDemo.py】(肯定成功);打开文件系统查看是否生成;如图15所示:
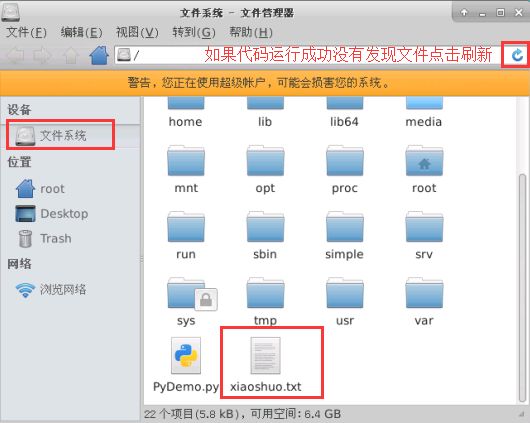
图15 爬取文件成功
♥ 温馨提示
本实验网页爬取的内容为静态网页内容,没有详细内容,想要获取更多数据,请自行在实验外实验
