soloV2保姆级教程(含环境配置,训练自己的数据集,代码逻辑分析等。能踩得坑都踩了....)更新ing
序言
环境:ubuntu18.04 cuda11.1 显卡3050 pytorch1.9
代码链接:
GitHub - aim-uofa/AdelaiDet: AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
论文解读可参考这位博主:
SOLOv2算法解读_‘Atlas’的博客-CSDN博客_solov2D
Detectron2 操作文档
Training — detectron2 0.6 documentation
一、安装detection2
detectron2/INSTALL.md at main · facebookresearch/detectron2 · GitHub
(1)建议不要用最新的pytorch(当前最新1.10)
(2)建议cuda,cudatoolkit严格对应
否则可能会报奇怪的错误,详见3.3.1
1.1 pytorch版本(仅限 Linux)
根据自己的pytorch和cuda版本进行选择。(如果pytoch版本不对,卸载,然后一定要上官网用相应命令下载,不要直接 pip install pytorch)
我的版本是
conda install pytorch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0 cudatoolkit=11.3 -c pytorch -c conda-forge1.2 测试
执行以下代码,如果能正常输出则说明cuda可用
import torch
# 以下代码只有在PyTorch GPU版本上才会执行
import time
print(torch.__version__)
print(torch.cuda.is_available())
a = torch.randn(10000, 1000)
b = torch.randn(1000, 2000)
t0 = time.time()
c = torch.matmul(a, b)
t1 = time.time()
print(a.device, t1 - t0, c.norm(2))
device = torch.device('cuda')
a = a.to(device)
b = b.to(device)
t0 = time.time()
c = torch.matmul(a, b)
t1 = time.time()
print(a.device, t1 - t0, c.norm(2))
t0 = time.time()
c = torch.matmul(a, b)
t1 = time.time()
print(a.device, t1 - t0, c.norm(2))
PyTorch测试代码-cuda加速_luoshiyong123的博客-CSDN博客_cuda测试代码
1.3安装预建的 Detectron2(仅限 Linux)
直接在虚拟环境复制执行下面代码即可
python -m pip install detectron2 -f \
https://dl.fbaipublicfiles.com/detectron2/wheels/cu111/torch1.10/index.html1.4构建AdelaDet
git clone https://github.com/aim-uofa/AdelaiDet.git
cd AdelaiDet
python setup.py build develop如果你已经下载好,可直接执行最后一句
二、测试demo
2.1下载权重文件
wget https://cloudstor.aarnet.edu.au/plus/s/chF3VKQT4RDoEqC/download -O SOLOv2_R50_3x.pth2.2测试执行命令
python demo/demo.py \
--config-file configs/SOLOv2/R50_3x.yaml \
--input input1.jpg input2.jpg \
--opts MODEL.WEIGHTS SOLOv2_R50_3x.pth
根据自己路径进行更改,注意进入虚拟环境
2.2.1报错
ImportError: No module named cv2
终端输入
pip install opencv-python2.2.2报错
ModuleNotFoundError: No module named 'detectron2'
可能是之前安装Detectron2有bug,重新输入那段代码
python -m pip install detectron2 -f \
https://dl.fbaipublicfiles.com/detectron2/wheels/cu111/torch1.10/index.html2.2.3 报错(此报错为我在服务器上搭建时报错)
from detectron2 import _C
ImportError: /root/miniconda3/lib/python3.8/site-packages/detectron2/_C.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZNK2at10TensorBase8data_ptrIdEEPT_v
解决方法:终端输入
python3 -m pip install 'git+https://github.com/facebookresearch/detectron2.git'参考文献:
ImportError: adet/_C.cpython-37m-x86_64-linux-gnu.so: undefined symbol: _ZNK2at6Tensor6deviceEv · Issue #181 · aim-uofa/AdelaiDet · GitHub
三、训练自己的数据集
3.1 构建自己的数据集
构建好的数据集格式应该如下
coco/ annotations/ instances_{train,val}2017.json person_keypoints_{train,val}2017.json {train,val}2017/ # image files that are mentioned in the corresponding json
并将他们放到datastes文件夹中
3.2 修改配置文件并注册数据集
直接说结论:
1.文件摆放方式
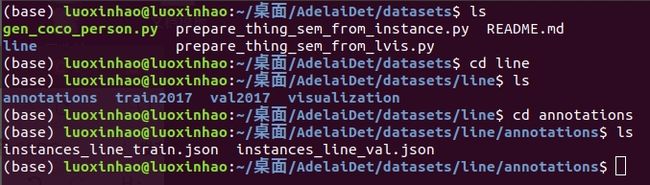
2.将yaml的datasets部分修改如下
DATASETS:
TRAIN: ("line_train",)
TEST: ("line_val",)
3.注册数据集
在adet/data/builtin.py 的PREDEFINED_SPLITS_PIC 部分后面加这两行
"line_train": ("line/line_train", "line/annotations/instances_line_train.json"),
"line_val": ("line/line_val", "line/annotations/instances_line_val.json"),将下面的
metadata_pic = {
"thing_classes": ['text']
}替换为
metadata_pic = {
"thing_classes": ['_background_', 'line']
}(注意,这里一定不要注册到后两个,虽然也能正常train,但test会报错,详见3.5.2)
此外,根据自己显存调整batch。
以下的蓝字是踩坑,不用看
我们下载的这个AdelaiDet-master里面不仅仅包含了solo算法,还包含了各种其他算法。我们这次要用soloV2来跑通。首先我们进入configs-->soloV2-->README.md进行参考
同时参考另一篇参考文献:
跑通SOLOV1-V2实例分割代码,并训练自己的数据集。_donkey_1993的博客-CSDN博客_solov2训练自己的数据集 https://blog.csdn.net/donkey_1993/article/details/108054849
https://blog.csdn.net/donkey_1993/article/details/108054849
注意,我们是通过detectron2构建的文件,而参考文献是mmdect,所以不能完全按参考文献来,只能根据他提供的思路自己修改。
终端输入
OMP_NUM_THREADS=1 python tools/train_net.py \
--config-file configs/SOLOv2/R50_3x.yaml \
--num-gpus 1 \
OUTPUT_DIR training_dir/SOLOv2_R50_3x3.2.3 报错
KeyError: "Dataset 'train2017' is not registered! Available datasets are:coco_2014_train, coco_2014_val, coco_2014_minival, coc
根据train_net.py文件上方的注释,train_net.py是一个可以集中调用多种网络的.py文件,所以可能只有注册过的coco数据集可以通过这个文件调用。因此,我们要想训练自己的数据集,需要先注册数据集
3.2.4 注册数据集
参考文献:
跑通SOLOV1-V2实例分割代码,并训练自己的数据集。_donkey_1993的博客-CSDN博客_solov2训练自己的数据集https://blog.csdn.net/donkey_1993/article/details/108054849
注意,我们是通过detectron2构建的文件,而参考文献是mmdect,所以不能完全按参考文献来,只能根据他提供的思路自己修改
builtin.py文件如下
import os
from detectron2.data.datasets.register_coco import register_coco_instances
from detectron2.data.datasets.builtin_meta import _get_builtin_metadata
from .datasets.text import register_text_instances
# register plane reconstruction
_PREDEFINED_SPLITS_PIC = {
"pic_person_train": ("pic/image/train", "pic/annotations/train_person.json"),
"pic_person_val": ("pic/image/val", "pic/annotations/val_person.json"),
}
metadata_pic = {
"thing_classes": ["person"]
}
_PREDEFINED_SPLITS_TEXT = {
"totaltext_train": ("totaltext/train_images", "totaltext/train.json"),
"totaltext_val": ("totaltext/test_images", "totaltext/test.json"),
"ctw1500_word_train": ("CTW1500/ctwtrain_text_image", "CTW1500/annotations/train_ctw1500_maxlen100_v2.json"),
"ctw1500_word_test": ("CTW1500/ctwtest_text_image","CTW1500/annotations/test_ctw1500_maxlen100.json"),
"syntext1_train": ("syntext1/images", "syntext1/annotations/train.json"),
"syntext2_train": ("syntext2/images", "syntext2/annotations/train.json"),
"mltbezier_word_train": ("mlt2017/images","mlt2017/annotations/train.json"),
"rects_train": ("ReCTS/ReCTS_train_images", "ReCTS/annotations/rects_train.json"),
"rects_val": ("ReCTS/ReCTS_val_images", "ReCTS/annotations/rects_val.json"),
"rects_test": ("ReCTS/ReCTS_test_images", "ReCTS/annotations/rects_test.json"),
"art_train": ("ArT/rename_artimg_train", "ArT/annotations/abcnet_art_train.json"),
"lsvt_train": ("LSVT/rename_lsvtimg_train", "LSVT/annotations/abcnet_lsvt_train.json"),
"chnsyn_train": ("ChnSyn/syn_130k_images", "ChnSyn/annotations/chn_syntext.json"),
}
metadata_text = {
"thing_classes": ["text"]
}
def register_all_coco(root="datasets"):
for key, (image_root, json_file) in _PREDEFINED_SPLITS_PIC.items():
# Assume pre-defined datasets live in `./datasets`.
register_coco_instances(
key,
metadata_pic,
os.path.join(root, json_file) if "://" not in json_file else json_file,
os.path.join(root, image_root),
)
for key, (image_root, json_file) in _PREDEFINED_SPLITS_TEXT.items():
# Assume pre-defined datasets live in `./datasets`.
register_text_instances(
key,
metadata_text,
os.path.join(root, json_file) if "://" not in json_file else json_file,
os.path.join(root, image_root),
)
register_all_coco()
这是solov2配置文件信息
MODEL:
META_ARCHITECTURE: "SOLOv2"
MASK_ON: True
BACKBONE:
NAME: "build_resnet_fpn_backbone"
RESNETS:
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
FPN:
IN_FEATURES: ["res2", "res3", "res4", "res5"]
DATASETS:
TRAIN: ("coco_2017_train",)
TEST: ("coco_2017_val",)
SOLVER:
IMS_PER_BATCH: 1
BASE_LR: 0.01
WARMUP_FACTOR: 0.01
WARMUP_ITERS: 1000
STEPS: (60000, 80000)
MAX_ITER: 90000
INPUT:
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
MASK_FORMAT: "bitmask"
VERSION: 2
这是我们自己的文件信息
自己的文件只有一个类“line”
我们照葫芦画瓢,将自己的文件弄进去
将yaml的dataset文件修改如下
DATASETS:
TRAIN: ("line_train",)
TEST: ("line_val",)
在builtin后面加这两行
"line_train": ("line/line_train", "line/annotations/instances_line_train.json"),
"line_val": ("line/line_val", "line/annotations/instances_line_val.json"),一个很神奇的事情,如果你是用pycharm执行的,需要在/home/luoxinhao/anaconda3/envs/AdelaiDet-master/lib/python3.7/site-packages/pycocotools/coco.py的80行左右
if not annotation_file == None:后面加一句这个。否则会报路径错误
annotation_file="../" + annotation_file但是在shell中执行则不需要(記不清了)。
这个问题的解决办法是将datasets整个文件夹复制一份放到"tools"
蓝字是踩坑,不用看
之后程序报错
"to a different value!\n{} != {}".format(key, self.name, oldval, val)
AssertionError: Attribute 'thing_classes' in the metadata of 'line_train' cannot be set to a different value!
['text'] != ['_background_', 'line']
调试发现,不知道为什么,
meta.thing_classes =["text"]
解决办法:将catalog.py以下函数注释掉
# def __setattr__(self, key, val):
# if key in self._RENAMED:
# log_first_n(
# logging.WARNING,
# "Metadata '{}' was renamed to '{}'!".format(key, self._RENAMED[key]),
# n=10,
# )
# setattr(self, self._RENAMED[key], val)
#
# # Ensure that metadata of the same name stays consistent
# try:
# oldval = getattr(self, key)
# assert oldval == val, (
# "Attribute '{}' in the metadata of '{}' cannot be set "
# "to a different value!\n{} != {}".format(key, self.name, oldval, val)
# )
# except AttributeError:
# super().__setattr__(key, val)之后执行程序,系统会下载rtl50.pkl文件
之后系统又报了一次路径错误,原因是我们之前在路径中加了../。但是我找不到在哪儿改。情急之下我把之前加的哪行../注释掉,然后直接将datasets复制一份放到了tools文件夹里。
之后系统又报错
[Errno 2] No such file or directory: 'datasets/line/train2017/053.jpg'
应该是我在生成json文件的时候文件夹的名字是train2017(后来被我改成train_line了)。所以我又把他改了回去
之后又报错
rone of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 128, 200, 272]], which is output 0 of ReluBackward0, is at version 3; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
根据报错的提示我们进入/anaconda3/envs/AdelaiDet-master/lib/python3.7/site-packages/detectron2/engine/train_loop.py 第285行,将
loss.backward()替换为
with torch.autograd.detect_anomaly(True):
loss.backward()重新执行,程序报错
TypeError: __init__() takes 1 positional argument but 2 were given
搜索所有inplace=True ,换为inplace=False
还是不好使。尝试更换pytorch版本
3.3 执行训练
终端输入
python tools/train_net.py \
--config-file configs/SOLOv2/R50_3x.yaml \
--num-gpus 1 \
OUTPUT_DIR training_dir/SOLOv2_R50_3x或在pycharm配置中输入
--config-file ../configs/SOLOv2/R50_3x.yaml --num-gpus 1 OUTPUT_DIR ../training_dir/SOLOv2ps:因为反复调试,有些我自己的路径是不对应的,请自行更改
3.3.1 报错1
rone of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 128, 200, 272]], which is output 0 of ReluBackward0, is at version 3; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
解决办法:
换一个pytorch版本(前面的所有操作建议都重来一遍)
注:在pytorch主页可以找到以前版本下载链接
之后莫名其妙就不报错了.可以正常执行(这个报错我处理了两天...)
3.3.2 用pycharm执行显示路径不正确
解决办法:将datasets整个文件夹复制一份放到tools文件夹中。并相应更改调试参数
3.3.3 loss发散
解决办法:降低学习率
3.3.4 训练过程中不保存权重
实际上是训练轮数不够,还没开始保存权重。默认是5000轮保存一次。具体解析见4.1
3.3.5 关于断点续训
不需要对输出的权重名字进行更改(无论是数字命名还是final)。只需要在执行命令时加入一句
--resume值得注意的是,这句必须加在OUTPUT那部分前面。
断点续训不但会保存之前的权重信息,还会保存之前的轮数等信息。
3.4 训练过程中的输出信息
训练过程中会输出如下信息:
eta: 1 day, 0:08:22 预计训练剩余时间
iter: 899 训练轮数
total_loss: 0.5141 总损失
loss_ins: 0.3549 ins损失(推测为instance,即分割的准不准)
loss_cate: 0.1629 cate损失(推测为category,即猜的种类对不对)
time: 0.3223 训练一轮所需时间
data_time: 0.0027 训练一轮加载数据所需时间
lr: 0.00044953 步长
max_mem: 1550M 所占显存
3.5 测试自己的训练结果
测试其实就是执行前面的demo.py,相当于yolov5的detect.py。终端输入
python demo/demo.py \
--config-file configs/SOLOv2/R50_3x.yaml \
--input 001.jpg \
--opts MODEL.WEIGHTS model_0000999.pth将权重改为自己的即可
3.6 评价自己的训练结果
终端输入
python tools/train_net.py \
--config-file configs/SOLOv2/R50_3x.yaml \
--eval-only \
--num-gpus 1 \
OUTPUT_DIR training_dir/SOLOv2 \
MODEL.WEIGHTS training_dir/SOLOv2/model_0000999.pth3.6.1 显存不够
我在评价模型的时候,遇到了显存不够的情况(原因是在执行过demo.py后,即使终止该命令,其所占用的显存依旧没有释放)
解决方法1:减小test图片大小(搁置)
我想通过减小图片大小来解决问题,但是却出现了修改training_dir/SOLOv2的config文件时修改无效的情况(每当我重新运行test,改完的部分又重新变回去了)。因为这个config文件是运行后生成的,所以需要在别的地方进行修改。
解决方法2:释放demo.py所占用的内存
终端输入:
nvidia-smi根据输出的信息,找到占用显存的项目,终端输入
sudo kill -9 PID其中PID是用显存的项目的PID号
以下是踩坑,不用看
3.6.2 报错
AttributeError: Cannot find field 'beziers' in the given Instances!
报错内容是输入的实例instance没有beziers(其实调试后发现也没有recs)。查阅资料(README)发现可能是需要先运行AdelaiDet/datasets/prepare_thing_sem_from_instance.py或prepare_thing_sem_from_lvis.py,从json中提取相关信息(从全景分割创建语义分割注释)。
参考文献:
https://github.com/aim-uofa/AdelaiDet/blob/master/datasets/README.md
但是这两个文件是为coco数据集准备的,所以我们要想要用作自己的数据集,需要做一些调整
3.6.3 prepare_thing_sem_from_instance.py修改
首先配置形参,输入--dataset-name line
然后修改.py文件,将最下面一段改为
for s in ["train"]:
create_coco_semantic_from_instance(
os.path.join(dataset_dir, "annotations/instances_line_{}.json".format(s)),
os.path.join(dataset_dir, "thing_{}".format(s)),
thing_id_to_contiguous_id
)
这样就会在你原本的train目录里生成.npz文件。
(ps:终端会输出将文件输入到train_thing文件夹里,但实际上文件夹是空的,文件实际输入到了存有图片的那个文件夹里。这个代码的逻辑很奇怪,可能是为了适应默认为coco的情况,他会先创建一个thing_train文件夹,然后从这个文件夹退出来,然后再进入我们自己的文件夹,将.npz输入进去)
同样,将上面那段代码第一行的train改成val,可以在验证集中生成.npz文件。但是不知道怎么用,放弃
3.6.4 另一个尝试
继续查找资料,可能和下面这篇文档有关(但是这篇文档貌似是做自然语言处理的)
https://github.com/aim-uofa/AdelaiDet/blob/master/configs/BAText/README.md#train-your-own-models
浏览器中输入https://universityofadelaide.box.com/shared/static/e3yha5080jzvjuyfeayprnkbu265t3hr.zip
会得到一个压缩文件。查阅压缩文件中的README,发现他的格式和我们想要的一样。按照其readme的指示执行main.py,报错
ModuleNotFoundError: No module named 'Levenshtein'
终端输入
conda install python-Levenshteinmain.py能正常执行,但是输出的和我预想的不太一样,没有AP值之类的参数。
继续查阅资料,程序默认走的是text_evaluation,果然这个评价是针对文档的。所以我们接下来的目的是修改评价器。
3.6.5 评价器逻辑
在没有自己选择评价器时,系统通过train_net.py中的build_evaluator函数帮你构建评价器。他会通过注册的数据集得到一个尾缀,然后根据尾缀帮你构建合适的数据集。
3.6.6 问题本质
调试发现,我们的数据集得到的尾缀居然是text的。分析原因,可能是我们在上面3.2处注册了meta_data_text。继续研究发现,好像下面这么长一段都是文本识别的(目标检测中的文本识别),所以评价模型之所以不能用,是因为我们注册数据集出了问题。回去看builtin.py,将粘到第三第四栏的改到第一第二栏,程序test终于能正确执行。
四、测试test
4.1 测试输入
变量配置如下:
--config-file ../configs/SOLOv2/8_8_1_0.0005*10_0.0005*3k4k5k_.yaml --num-gpus 1 --eval-only OUTPUT_DIR ../training_dir/aaa MODEL.WEIGHTS ../training_dir/aaaa/model_0004999.pth加了一个--eval-only ,一个权重路径
4.2 测试评价指标
该测试评价指标依照coco
这是我的一个样例输出:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.436
IOU从0.5到0.95,没0.05取一个,计算出来的AP值的平均
AP值:准确率,你测到的&&是真的/你测到的
AR值:召回率,你测到的&&是真的/是真的
IOU:交并比,用来判断东西是不是真的。比如你测到的
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.880
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.441
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.436
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.460
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.475
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.475
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.475
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
[03/19 15:24:36 d2.evaluation.coco_evaluation]: Evaluation results for segm:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:-----:|:------:|:-----:|
| 43.581 | 87.995 | 44.082 | nan | 43.581 | nan |
[03/19 15:24:36 d2.evaluation.coco_evaluation]: Some metrics cannot be computed and is shown as NaN.
[03/19 15:24:36 d2.evaluation.coco_evaluation]: Per-category segm AP:
| category | AP | category | AP |
|:-------------|:-----|:-----------|:-------|
| _background_ | nan | line | 43.581 |
[03/19 15:24:36 d2.engine.defaults]: Evaluation results for line_val in csv format:
[03/19 15:24:36 d2.evaluation.testing]: copypaste: Task: bbox
[03/19 15:24:36 d2.evaluation.testing]: copypaste: AP,AP50,AP75,APs,APm,APl
[03/19 15:24:36 d2.evaluation.testing]: copypaste: 0.0000,0.0000,0.0000,nan,0.0000,nan
[03/19 15:24:36 d2.evaluation.testing]: copypaste: Task: segm
[03/19 15:24:36 d2.evaluation.testing]: copypaste: AP,AP50,AP75,APs,APm,APl
[03/19 15:24:36 d2.evaluation.testing]: copypaste: 43.5809,87.9950,44.0819,nan,43.5809,nan进程已结束,退出代码为 0
参考文献:看懂COCO数据集目标识别性能评价标准AP,AP50,AP75,APsmal等_疯狂的大山鸡的博客-CSDN博客_ap50 ap75
五、代码逻辑解析
由于这部分比较多,所以新开了一个博客,链接如下:
https://blog.csdn.net/m0_58348465/article/details/122771195
六、部署
5.1 .pt-->.onnx(未解决)
部署过程遇到了一些问题。执行export_model_to_onnx时,报错:
too many indices for tensor of dimension 3
报错位置发生在train_net.py第152行,如下:
images = [x["image"].to(self.device) for x in batched_inputs]调试发现,训练过程中也执行过这行语句,变量batched_inputs保存了一个图片的全部信息,包括路径,长宽,像素等等。但在执行export_model_to_onnx.py过程中传入batched_inputs仅仅是一个全是0的tensor。
目前有一种想法是直接手写batched_inputs,将其改变成和train_net.py相类似的格式。但没有尝试,不确定是否可行。
查阅源代码github相关问题,也确实有人遇到了相似问题,但没有给出具体的解决方案。还有人说onnx不支持linspace操作(soloV2中用到),所以想部署必须跳过此部分。
此外detectron2平台似乎提供了一些部署的方式,可以参考下面几篇文档:
detectron2配置与部署_alex1801-CSDN博客_detectron2部署
Deployment — detectron2 0.6 documentation
detectron2.export — detectron2 0.6 documentation
最后还查到有一个版本是支持导出onnx的,但需要付费。链接如下:
MANA AI工具链详情