SVM的简单理解
1、基本知识
决策边界,或称为决策面,其目的是将两种类别的进行分开。
决策边界如何定义?训练集上的正负样本到决策边界的距离保持最大。
支撑向量是什么?可以理解为当前样本下,支撑当前决策边界的样本,如何支撑向量不变,继续增加训练样本,决策边界不会发生变化。
松弛因子ei(大于0),对约束进行放松,允许噪声点的存在,这个很重要,因为大部分情况下样本都是近似可分(即使在使用核函数的情况下),松弛因子的存在使寻找的决策边界更优。
惩罚项C(大于0),控制松弛因子ei的作用情况,当C很大,ei发挥的作用小,也就是松弛的少,当C很小,ei发挥的在作用大,松弛的多
SVM的目标函数与约束怎么来?
假设决策边界函数 g ( x ) = w x + b g(x)=wx+b g(x)=wx+b,则样本点到 g ( x ) 的 距 离 为 g(x)的距离为 g(x)的距离为
∣ g ( x ) ∣ ∣ ∣ w ∣ ∣ \frac{|g(x)|}{||w||} ∣∣w∣∣∣g(x)∣在SVM中只关注支撑样本点,然后取距离它们最远的平面为决策边界,转为数学公式为: m a x ( m i n ( ∣ g ( x ) ∣ ∣ ∣ w ∣ ∣ ) ) max(min(\frac{|g(x)|}{||w||})) max(min(∣∣w∣∣∣g(x)∣)),可以简化成: m a x ( 1 ∣ ∣ w ∣ ∣ ) max(\frac{1}{||w||}) max(∣∣w∣∣1) s . t . y i ∗ g ( x i ) ≥ 1 s.t. \ \ \ y_i*g(x_i)\ge1 s.t. yi∗g(xi)≥1怎么来的呢?一般有 y i = − 1 或 1 , ∣ g ( x ) ∣ ≥ 1 y_i=-1或1,|g(x)|\ge1 yi=−1或1,∣g(x)∣≥1所以推导得到
2、基本原理
假设给定样本集 D = ( x 1 → , y 1 → ) , ( ( x 2 → , y 2 → ) , ⋅ ⋅ ⋅ , ( ( x n → , y n → ) D={(\overrightarrow{x_1},\overrightarrow{y_1}),((\overrightarrow{x_2},\overrightarrow{y_2}),···,((\overrightarrow{x_n},\overrightarrow{y_n})} D=(x1,y1),((x2,y2),⋅⋅⋅,((xn,yn), y i ∈ { − 1 , 1 } y_i\in \{-1,1\} yi∈{−1,1}样本容量为n,SVM的目的是寻找一个最佳分类面将两个类分开,这个分类分类面可以通过下述方程描述:
w → T x + b = 0 \overrightarrow{w}^Tx+b=0 wTx+b=0
w → \overrightarrow{w} w表示平面的方向; b b b表示偏离量,决定平面与原点的距离。
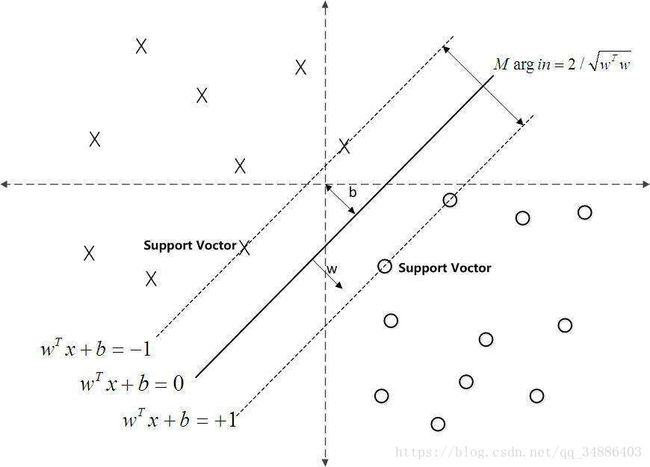
从上图可以看出左侧x点距离平面的距离是小于-1,二右侧的圆点到平面的距离是大于1的。由于 y i y_i yi为-1或1,即可以用公式 y i ( w → x + b ) ≥ + 1 y_i(\overrightarrow{w}x+b)\ge+1 yi(wx+b)≥+1,当是支撑向量时,等号成立,即 w → x + b = 1 \overrightarrow{w}x+b=1 wx+b=1和 w → x + b = − 1 \overrightarrow{w}x+b=-1 wx+b=−1,将这两个平面的距离记为 γ \gamma γ,SVM的核心就是尽量是间隔距离 γ \gamma γ最大化。
记 w → x + b = 1 \overrightarrow{w}x+b=1 wx+b=1上的为正样本 x + x_+ x+,在 w → x + b = − 1 \overrightarrow{w}x+b=-1 wx+b=−1上的是负样本 x − x_- x−,根据向量的加减法规则, x + x_+ x+减去 x − x_- x−得到的向量在最佳超平面的法向量 w → \overrightarrow{w} w方向的投影即使距离 γ \gamma γ:
γ = ( x + − x − ) w → ∣ ∣ w → ∣ ∣ = w → x + ∣ ∣ w → ∣ ∣ − w → x − ∣ ∣ w → ∣ ∣ \gamma=(x_+-x_-)\frac{\overrightarrow{w}}{||\overrightarrow{w}||}=\frac{\overrightarrow{w}x_+}{||\overrightarrow{w}||}-\frac{\overrightarrow{w}x_-}{||\overrightarrow{w}||} γ=(x+−x−)∣∣w∣∣w=∣∣w∣∣wx+−∣∣w∣∣wx−
又有 w → x + = 1 − b \overrightarrow{w}x_+=1-b wx+=1−b, w → x − = − 1 − b \overrightarrow{w}x_-=-1-b wx−=−1−b
所以得
γ = 2 ∣ ∣ w → ∣ ∣ \gamma=\frac{2}{||\overrightarrow{w}||} γ=∣∣w∣∣2
就是说距离 γ \gamma γ决策面的法向量有关,要找到最大间隔的决策边界,只需找到满足约束条件下参数 w → , b \overrightarrow{w},b w,b使得 γ \gamma γ最大,即有:
{ m a x w → , b 2 ∣ ∣ w → ∣ ∣ s . t y i ( w → x + b ) ≥ + 1 \left\{ \begin{aligned} max_{\overrightarrow{w},b}\frac{2}{||\overrightarrow{w}||} \\ s.t \ \ \ y_i(\overrightarrow{w}x+b)\ge+1 \end{aligned} \right. ⎩⎪⎨⎪⎧maxw,b∣∣w∣∣2s.t yi(wx+b)≥+1
一般转化为求最小值:
{ m i n w → , b 1 2 ∣ ∣ w → ∣ ∣ 2 s . t y i ( w → x + b ) ≥ + 1 \left\{ \begin{aligned} min_{\overrightarrow{w},b}\frac{1}{2}||\overrightarrow{w}||^2 \\ s.t \ \ \ y_i(\overrightarrow{w}x+b)\ge+1 \end{aligned} \right. ⎩⎨⎧minw,b21∣∣w∣∣2s.t yi(wx+b)≥+1
这就是基本的SVM
结合之前提及到惩罚项C和松弛因子ei,优化的目标变为下述:
{ m i n w → , b 1 2 ∣ ∣ w → ∣ ∣ 2 + C ∑ i = 1 n e i s . t y i ( w → x + b ) ≥ 1 − e i , i = 1 , 2 ⋅ ⋅ ⋅ , n e i ≥ 0 \left\{ \begin{aligned} min_{\overrightarrow{w},b}\frac{1}{2}||\overrightarrow{w}||^2+C\sum^n_{i=1}e_i \\ s.t \ \ \ y_i(\overrightarrow{w}x+b)\ge1-e_i,i=1,2···,n\\ e_i\ge0 \end{aligned} \right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧minw,b21∣∣w∣∣2+Ci=1∑neis.t yi(wx+b)≥1−ei,i=1,2⋅⋅⋅,nei≥0
这是我们一般情况下使用的SVM