faster rcnn 学习笔记

论文:《Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks》
作者 何凯明 rbg大神都做过简单的介绍,现在说说 Shaoqing Ren中国科学技术大学(phd)

改进
针对fast rcnn 计算的瓶颈,用选择性搜索算法生成RP是在cpu上进行的,每张图片生成RP的时间占其检测大部分时间,故而若想提高FPS的值,须在生成RP上做一系列的改进,此篇论文 便是基于cnn网络生成RP,节省检测时间。
Faster-Rcnn网络
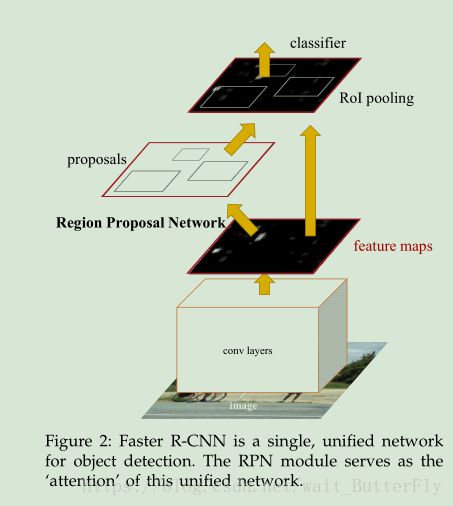
上图来自于论文原文,描述从输入图片,生成feature maps,rpn网络生存rp,roi融合,最后分类和回归定位。
conv layer
conv layers 包含conv,pooling,relu三种层,选择标准的基础网络模型(zfNet,vggNet)
conv层;kernel_size=3,pad=1
pool层:kernel_size=2,stride=2
conv层不会改变输入和输出矩阵大小(size)
pooling层会改变size大小,使输出长宽都变味输入的1/2
RPN网络
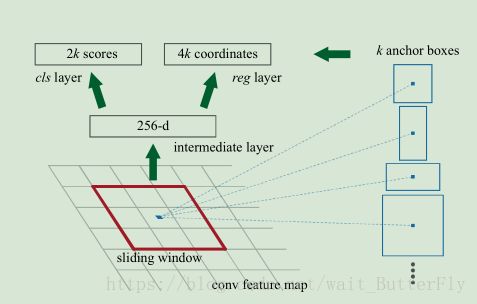
基础cnn网络用于生成RP。卷积相当于滑窗。假如输入图像是1000*600,则经过了几次stride后,map大小缩小了16倍,最后一层卷积层输出大约为60*40大小,那么相当于用3*3的窗口滑窗(注意有padding),对于左边一支路而言,输出18个通道,每个通道map大小仍为60*40,代表每个滑窗中心对应感受野内存在目标与否的概率。
anchor机制
anchor是rpn网络的核心。需要确定每个滑窗中心对应感受野内存在目标与否。由于目标大小和长宽比例不一,需要多个尺度的窗。Anchor即给出一个基准窗大小,按照倍数和长宽比例得到不同大小的窗。例如论文中基准窗大小为16,给了(8、16、32)三种倍数和(0.5、1、2)三种比例,这样能够得到一共9种尺度的anchor。
在对60*40的map进行滑窗时,以中心像素为基点构造9种anchor映射到原来的1000*600图像中,映射比例为16倍。那么总共可以得到60*40*9大约2万个anchor。但是会通过非极大值抑制的方法,设定IoU为0.7的阈值,即仅保留覆盖率不超过0.7的局部最大分数的box(粗筛)。最后留下大约2000个anchor,然后再取前N个box(比如300个)给Fast-RCNN。Fast-RCNN将输出300个判定类别及其box,对类别分数采用阈值为0.3的非极大值抑制(精筛),并仅取分数大于某个分数的目标结果(比如,只取分数60分以上的结果)。
ROI pooling
输入是原始的feature maps 和PRN输出的proposal boxes(大小不一)
fc层中需要输入的proposals是大小一致的(roi pooling是由spp发展而来的)
proposal=[x1, y1, x2, y2]是对应MxN尺度的,所以首先使用spatial_scale参数将其映射回MxN大小的feature maps尺度(这里来回多次映射,是有点绕);之后将每个proposal水平和竖直都分为7份,对每一份都进行max pooling处理。这样处理后,即使大小不同的proposal,输出结果都是7x7大小,实现了fixed-length output。
classification detection
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。
训练
1) 单独训练RPN网络,网络参数由预训练模型载入;
2) 单独训练Fast-RCNN网络,将第一步RPN的输出候选区域作为检测网络的输入。具体而言,RPN输出一个候选框,通过候选框截取原图像,并将截取后的图像通过几次conv-pool,然后再通过roi-pooling和fc再输出两条支路,一条是目标分类softmax,另一条是bbox回归。截止到现在,两个网络并没有共享参数,只是分开训练了;
3) 再次训练RPN,此时固定网络公共部分的参数,只更新RPN独有部分的参数;
4) 那RPN的结果再次微调Fast-RCNN网络,固定网络公共部分的参数,只更新Fast-RCNN独有部分的参数。