大型零售店的数据中台搭建历程
前言
2015年至今,新式茶饮时代的到来诞生了一大批“网红”茶饮店,随后各大品牌迅速在城市街头如雨后春笋般张罗开店,市场逐渐趋于饱和,产品同质化现象显露,近年来关于食品安全问题也频频爆出引发社会热议。对于零售企业而言,精细化的营销以及产品质量的追踪把控已然成为企业关注的重点,由此 IT 部门也将面临更大更细粒度的数据挑战。
近期在 Kyligence 云系列活动中,我们邀请到云产品客户代表——合阔的数据工程师杜森与大家分享大型零售店的数据中台搭建历程。本文就将从 “一杯茶的背后故事” 来展示业务中台如何支撑零售企业高速发展的业务态势。
一杯网红茶饮的诞生离不开的两个关键词——口感、口味。绝大多数零售连锁企业畅销全球的秘密武器就是把握了全世界人普遍喜欢的口感,例如肯德基的炸鸡都是香香脆脆的,唇齿之间都是鲜嫩的汤汁,这就是口感。
所谓口味就是每个人可以根据自己的喜好去添加或者减少一些佐料,形成定制化的茶饮服务。对于餐饮行业来说,如果能够找到一个适合全世界人的口感的产品就可以推广到全世界,例如连锁巨头肯德基、麦当劳、星巴克。
要想确保品牌之下统一的口感和定制化的茶饮口味服务,在这背后就少不了中台系统的强大算力。数字化中台是聚焦连接前台业务和后台 ERP 基干系统,建立以用户为中心的现代商业中最核心竞争力:敏捷的用户响应力。
业务中台建设就是帮助零售客户解决全渠道整合交易不通和数据不准,以及各种供应链之间连接不灵活的问题。
一杯茶的背后:动态配方计算 & 实时库存扣减
对于中台系统来说,当用户选择了一杯“少冰、五分甜、加奶盖的多肉葡萄”,系统就会自动计算这杯定制茶饮里要放多少葡萄,放多少冰沙。原料含量的计算是非常复杂的,例如茶饮中需要有金凤茶底,但可能当天门店没有常用的茶品牌A,只能选用另一个茶品牌B,但不同品牌会有一些差异,为了保证这杯茶的口味没有太多变化,系统需要计算出如果使用茶品种 B 需要放多少量。
因为门店原料的动态化,其实每一杯茶的口味都有些许微妙差异,但是对于茶饮品牌来说,就需要确保全国连锁店里面的口感是一样的。
正因为对口味的个性化需求也导致一杯茶的背后需要涉及大量的计算,而中台就需要配合做好以下两件非常复杂的操作:
1)动态配方的计算
中台就有一个动态配方计算和库存计算的引擎去解决,因为动态配方涉及到不同的原材料,这些原材料组合在一些会产生不同的口味,同时这些口味之间的比例是不一样的,需要后台进行实时动态的计算。
2)实时库存扣减
另一方面,在交易完成后就需要及时扣除这些原料库存,如果发现门店库存不足就需要总仓库或临近的门店及时帮忙补货。库存盘点也可以帮助企业去判定实验室的标准配料是不是跟实际的市场反馈有出入,或是来判别是否有个别门店的员工存在私拿原料的问题。
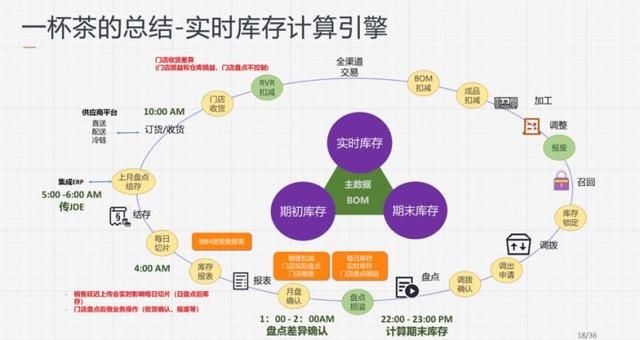
一杯茶复杂的意义:全渠道订单履约 & 商业协同
对于大多数企业来说,可能认为上述的计算过程过于复杂,但是对于品牌来说,无论是动态配方或是库存的实时计算都是企业全渠道订单履约和商业协同与运营优化的基础。
全渠道订单履约就是用户在手机上点了一杯茶,然后通过门店制作、外卖配送,最终将茶送到客户手上,这就完成了一次履约。
但假设有这样一个场景,某一个公司老板心情好,请公司所有人喝奶茶,通过手机点了200杯奶茶,这样一笔订单到一家门店到底是一个惊喜还是惊吓呢?
假设一杯茶的制作时间是10分钟到15分钟,体量比较大的的门店会有 5-10 名制茶人员,如果他们关闭现场点单、马不停蹄得去完成这样一单可能就需要4-5个小时,但客户只想在 1 小时之内收到这 200 杯茶。
对于这种大单,行业普遍的做法是限制客户的订单数量,例如在网上点单最多可点十杯,或者这种大需求量的订单需要客户提前 3 个小时下单。但目前合阔的客户完全可以根据动态配方的计算得出这笔订单需要消耗多少原料,然后再根据这样实时库存引擎计算出以这家门店为中心,附近有多少家门店还有原料的余量,然后协同周边的茶饮店一起做这200杯茶的订单,有了这样一个动态配方计算和实时库存数,对这样的大单下到某一个门店时,系统就可以把这个订单分解成好几个小单到附近的门店,等这些门店全做完之后再把这个单收回来送到用户手中完成订单,这就是一个客户履约的能力。
另一点是商业协同,对于茶饮品牌来说如果每一家门店做出来的口感不一就会削弱品牌的一致性,在这背后就需要一个实时的计算引擎来精准计算配方,每个人的口味都可以满足而且可以保证全国所有连锁店里面的口感都是一样的;另一个方面库存的实时扣减可以做到智能的订货或者是补货,也可以推算出来这家门店明天该进多少原料,减少物料浪费。
随着茶饮市场的迅发展,再加上越来越多的人追求口味小众的定制饮品,中台如何确保企业即使在一千家门店的规模下也能保证在高峰期做到动态配方及库存的实时计算显得尤为重要,为了有效支撑未来业务发展的数据库,合阔也经历了许多尝试与变革。
合阔在大数据场景下的数据库历程
以下是某客户的库存引擎和配方拆解的增长图,一个月有近5亿多条数据的增量,按照目前店铺不断扩张的趋势,合阔预计在未来1-2年的时间中,单表的数据量就能达到10 亿,传统数据库就将面临巨大的数据挑战。
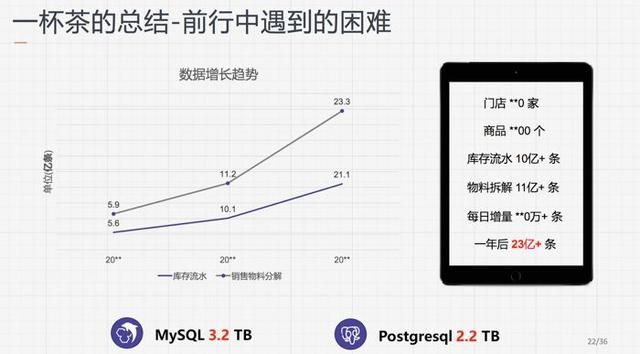
起初在数据量并不大的时候,合阔采用的是微服务架构,但是底层还是需要一个强大的数据库来支撑高速发展的业务态势,最早是本地的私有部署形式,但在业务高峰时期无法快速扩容,导致灵活性较差。后面在大数据的探索中主要经历了以下几个发展阶段:
第一阶段:数据库上云
自从使用云上数据库后解决了很多问题,比如在某一个高峰期交易量特别大,因为云数据库可以动态升降配置,将不同类型的数据库分开部署,化解了高并发下的数据处理难题。
第二阶段:热数据冷数据
在上了云之后发现依旧要面临大数据场景下的数据挑战,一开始采用基于不同的时间或门店来做分库分区分表的策略,并且需要满足实时计算,历史数据的倒推,后面因为业务架构的复杂导致在真正实践的过程中遇到非常多的麻烦所以就不再使用了。
第三阶段:Mongo/ElasticSearch
Mango 特别适合前期业务不太明确的阶段,但是到后期随着用户量的积累,部分业务比较成熟,并且Mongo在高并发或者是数据量大的时候也无法很好地支撑业务,对内存的要求也非常高所以就不再使用;另外使用 ES 作为数据分析的工具,但是在分页这一块对准确度的支持程度不是很高,需要耗费大量人力去做筛查,因此也不作使用考虑了。
第四阶段:Greenplum
Greenplum 基本上可以做到秒级查询,但是在实际生产环境中发现对高并发的支持非常差,几十个并发之后基本上就不行了,但对客户而言高并发的支持是非常重要的,因此也排除了这项选择。
胜利的曙光:Kyligence
刚开始调研 Kyligence 的时候发现预计算技术的优势,在业务维度比较固定的情况下使用预计算功能可以把一些分析维度提前建好,另外就是在维度保持不变的情况下数据量不会线性增长。
选择 Kyligence 的第一考虑就是未来当数据到达几十亿,上百亿的时候,同时在面临高并发的查询时能够很好得支撑客户的日常业务发展,其次对于业务维度比较固定的企业来说,只需要设计好一个模型,通过预计算可以将查询变得非常快速,并且可以多次使用,大大保证了整体产品的稳定性。除了预计算,Kyligence 读写分离功能在构建模型的时候完全不会影响到分层查询的操作,另外弹性伸缩机制也有效解决了资源配置问题,提升了构建的速度。

Kyligence 在查询响应速度上的提升可以看下图所示,对比现有数据库的响应速度快了几十倍,在实际生产环境中 Kyligence 对于库存的查询基本上是在 1~2 秒之间响应的,总体来说对系统响应时间的提升还是非常快速的。
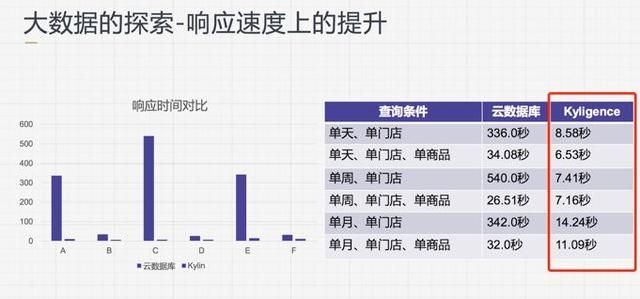
上图显示 Kyligence 需要 7、8 秒,主要是因为我们的业务是微服务的形式,一个查询需要从多个服务取得数据。实际 Kyligence 的查询响应只需要 1~2 秒。未来我们会持续优化其他微服务,使其总体查询速度变快。
Kyligence 不仅仅使查询速度有很大的提升,同时也节省了很多在存储上的费用支出,目前以记录库存的数据库存储来说,这部分的数据存储费用一年7万元左右,按 6 个月的业务体量,每个月产生一两亿的增量数据,预测一年之后的储存费用是翻倍的。当我们把库存的历史数据搬到 Kyligence 上后,主业务数据库的存储减少了很多,相应的费用也减少了很多。下图是一个存储减少之后的开销对比:
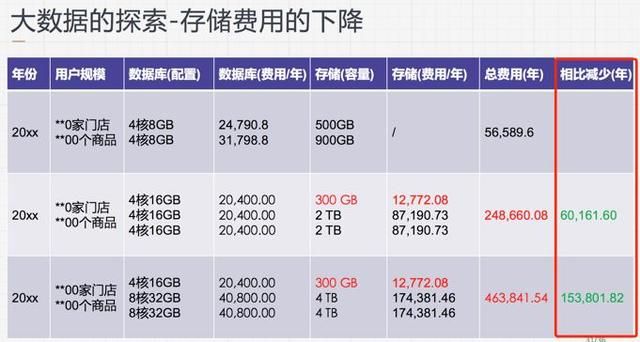
库存相关的业务数据存储,总共有 1.6 TB。我们把历史数据(1.3 TB)搬到了 Kyligence,使得主业务数据存储费用每年下降 6~15 万。那这些费用是不是转嫁到 Kyligence 上了呢?
其实不是的。1.3 TB的数据转移到 Kyligence,只占用了400 GB(包含原始数据和 CUBE 数据)。
1.6 TB 减少到 400 GB,存储减少的原因有两个:
- 业务数据库使用的是 OLTP 型数据库,为了查询快使用了很多的索引,导致整体存储占用比较高
- Kyligence 使用的是 Hive 数据源云 BLOB 存储,数据压缩存放,而且CUBE构建后的数据远远小于 OLTP 型数据库索引。
最重要的是 Kyligence 所用的云存储费用是我们业务数据库存储费用的十分之一,2 TB 的数据存储一年也只需要4000~5000元。随着我们业务/数据的高速增长,Kyligence 会带给我们更大的效益,降低更多的费用开支。
下图展示的是 Kyligence 在合阔的系统架构中的位置,和数据库在一个地位,未来也计划会把更多数据和业务放在这个平台上,因为有这样一个强大的 Kyligence 作为数据分析的后盾就可以探索更多的想象力。
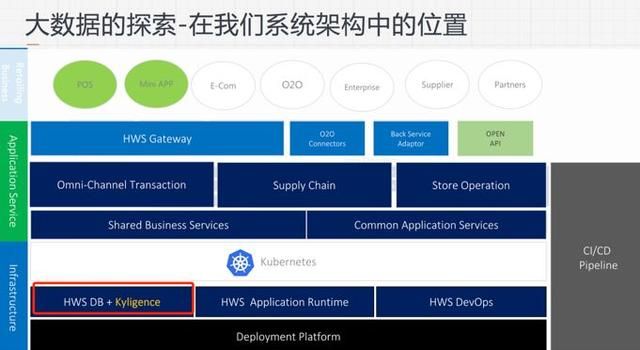
未来计划
首先合阔要做的就是迁移更多的业务场景到 Kyligence 平台上,例如交易订单信息,目前这些信息都是存储在数据库中,不同的分析报告需要提前将数据进行拆分到不同的报表里,使用 Kyligence 平台只需要基于 Cube 构建或者是维度建模,减少了很多无效的劳动。
另一点就是挖掘数据的价值,过去面对几十亿条数据的情况下无法做到快速查询以及维度分析,但是有 Kyligence 可以帮助客户更好的完善智能订货以及更快了解食品安全问题,未来也希望能挖掘更多数据的想象空间来提升企业的客户服务。