李宏毅深度强化学习笔记
文章目录
- 增强学习(RL)的一些基本概念:
-
- RL的基本组成:
- 三者相互作用的过程:
- Policy:
- 轨迹的概率:
- Expected Reward:
- Policy gradient:
- On-policy → \rightarrow →Off-policy
-
- Importance Sampling:
- PPO:
-
-
-
-
- 注:
-
-
-
增强学习(RL)的一些基本概念:
RL的基本组成:
1-actor:即操纵/需要学习的对象,如飞机大战里的飞机
2-environment:外部环境,如飞机大战里除了飞机以外的所有东西,他们均为游戏内部设定
3-reward:回报,如飞机大战中打死一个飞机得到的分数
其中1是我们自己控制的,可以学习。2,3均无法控制。
三者相互作用的过程:

其中s为环境的状态state,a为actor的行动action。
某一次游戏/实验中的状态和行动组成的集合叫做轨迹 τ : = { ( s 1 , a 1 ) , . . . , ( s t , a t ) , . . . } \tau:=\{(s_1,a_1),...,(s_t,a_t),...\} τ:={(s1,a1),...,(st,at),...}
Policy:
一般用 π \pi π表示,指的是给定环境的某状态s之后actor采取的行动a(的概率分布)。由于一般a都不是一个确定的值而是一个随机变量,所以Policy实际是一个概率分布。
在将RL和神经网络(NN)结合之后,Policy一般可以理解为一个参数为 θ \theta θ的NN。其输入为状态s,输出为给定s之后对应的行动的概率分布的某个抽样。
轨迹的概率:
直观上,某个轨迹 τ : = { ( s 1 , a 1 ) , . . . , ( s t , a t ) , . . . } \tau:=\{(s_1,a_1),...,(s_t,a_t),...\} τ:={(s1,a1),...,(st,at),...}出现的概率,自然是给定的初始状态为 s 1 s_1 s1的概率 p ( s 1 ) p(s_1) p(s1),乘上给定 s 1 s_1 s1之后actor输出的action为 a 1 a_1 a1的概率 p θ ( a 1 ∣ s 1 ) p_\theta(a_1|s_1) pθ(a1∣s1)的概率,乘以给定当前环境的状态 s 1 s_1 s1以及actor采取行动 a 1 a_1 a1之后环境的状态变为 s 2 s_2 s2的概率。乘以…即
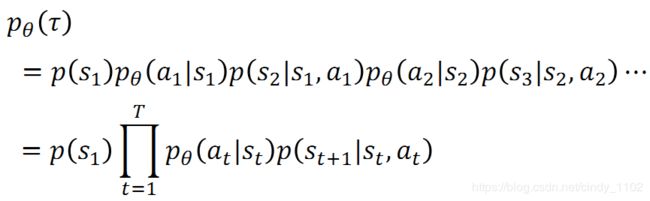
p θ ( a 1 ∣ s 1 ) p_\theta(a_1|s_1) pθ(a1∣s1):有了 s 1 s_1 s1之后采取的 a 1 a_1 a1不是固定的,而是随机的,符合一个概率分布。即NN的输出是一个概率分布,而真正采取到的action a 1 a_1 a1是从这个分布中抽样得到的。
p ( s 2 ∣ s 1 , a 1 ) p(s_2|s_1,a_1) p(s2∣s1,a1): 有了第一个画面 s 1 s_1 s1以及player的行为 a 1 a_1 a1之后游戏本身转化为的另一个画面 s 2 s_2 s2。这个东西由游戏本身决定,一般来说不是确定的,否则这个游戏就太过无聊了。
我们能控制的是前者,后者是游戏设定好的。
Expected Reward:
我们的目标就是最大化某次完整的实验(Episode)所得到的轨迹 τ \tau τ对应的reward的总和。但由于状态s和行动a都是随机的,所以需要针对这些随机性取期望,即我们最大化的实际上是下面的Expected Reward:
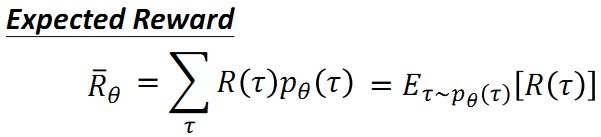
Policy gradient:
使用类似于GD的方法来优化上述目标函数:
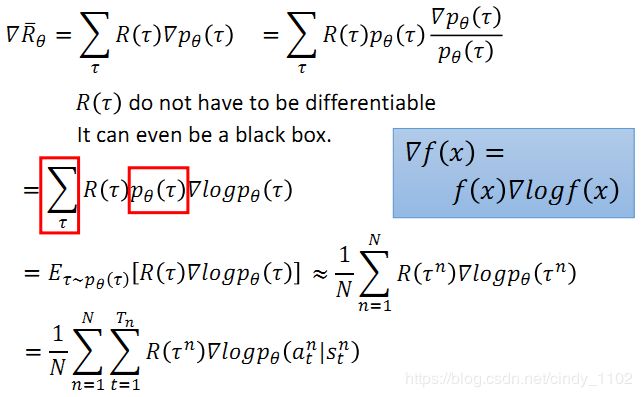
其中倒数第二行的约等号是用样本平均代替期望值;
最后一行根据的是 p θ ( τ n ) p_\theta(\tau^n) pθ(τn)的计算公式以及该公式中的一部分和 θ \theta θ无关,所以求梯度后是0.
最后一行的直观:如果给定某个s时采取行为a得到的reward是正的,那么就要增加给定s时采取行为a的概率 p θ ( a ∣ s ) p_\theta(a|s) pθ(a∣s)。
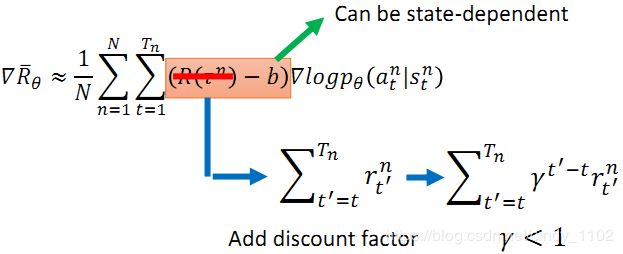
在实际应用中,为了更合理,需要对 R ( τ n ) R(\tau^n) R(τn)进行一定的调整,一般通过添加基准线和考虑各个时间点的收益权重(添加权重因子)来将 R ( τ n ) R(\tau^n) R(τn)转化为 A θ ( s t , a t ) A^\theta(s_t,a_t) Aθ(st,at)
On-policy → \rightarrow →Off-policy
回忆Policy gradient中梯度的最终结果
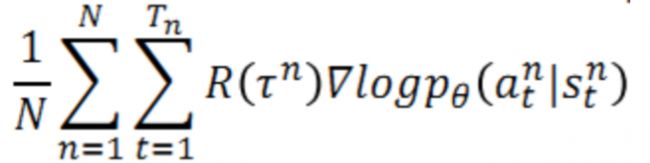
因此在用policy gradient迭代更新时,每迭代一次得到一个新的 θ \theta θ之后,就需要用新的policy θ \theta θ与环境做互动很多次得到样本数据,才能再次更新 θ \theta θ:
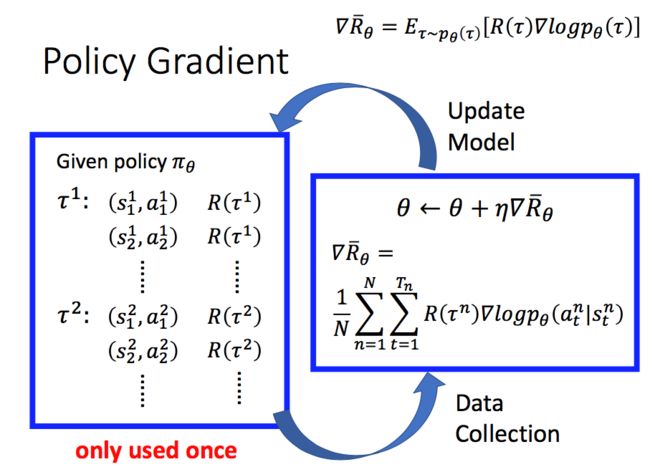
非常非常耗时。
接下来要提到的On-policy → \rightarrow →Off-policy就是为了解决这个计算量太大的问题。
首先介绍两者的概念:
On-policy:和环境交互的agent与学习的agent是同一个(比如阿光自己在和别人下棋,一边下棋一边学习)
Off-policy:上述的两个agent不是同一个(比如阿光在看两外两个人下棋,在一边学习)
Importance Sampling:
为了实现On-policy → \rightarrow →Off-policy首先需要介绍一个更一般的数学概念Importance Sampling。他把关于一个概率分布求期望转化为了关于另一个概率分布取期望:
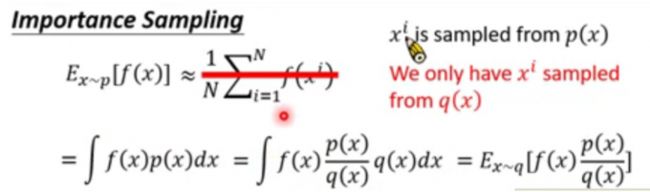
虽然理论上来说上述相等是严格的,但实际上我们计算期望的方式其实是样本平均,所以要想让两个样本平均近似相等,需要的一个要求就是 p , q p,q p,q两个分布的差距不太大。
利用上述思想,就可以完成on policy到off policy的转化:
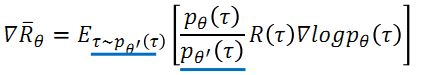
利用 π θ ′ \pi_\theta' πθ′来进行采样,将采集的样本拿来训练 θ \theta θ ,由于 θ ′ \theta′ θ′是固定的,采集的样本可以被重复使用,即用一个 θ ′ \theta' θ′采集到的样本进行多次 θ \theta θ的更新。
PPO:
上面提到,为了保证On-policy → \rightarrow →Off-policy的准确性,需要 θ , θ ′ \theta,\theta' θ,θ′两个分布非常相似。所以在真正用policy gradient优化时,目标函数需要在原来的基础上加一个惩罚项,即 β K L ( θ , θ ′ ) \beta KL(\theta,\theta') βKL(θ,θ′)用来控制两个分布的差距。其中 β \beta β是惩罚系数,可以手动调整。KL的意思是KL divergence
因此对于PPO,真正来优化的目标函数不是Expected Reward R ˉ θ \bar R_\theta Rˉθ,而是下面的:

注:
1-从 R ˉ θ \bar R_\theta Rˉθ到 J θ ′ ( θ ) J^{\theta'}(\theta) Jθ′(θ)的转化也需要一些技术细节,这里省略了中间过程。
2-这里的KL( θ , θ ′ \theta,\theta' θ,θ′)并不是指做为分布时两个参数的KL divergence(做为分布时两者的KL divergence实验中是无法得到的),而是指两者behaviour上的距离,即根据两者的历史行为算出经验上的KL divergence。
实际算法如下:
