推理时去除残差结构!RMNet:让ResNet、RepVGG Great Again
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童

虽然残差连接可以训练深度非常深的神经网络,但由于其多分支拓扑结构,对在线推理并不友好。这鼓励了许多研究人员去设计没有残差连接的DNN。例如,RepVGG在部署时将多分支拓扑重新参数化为类VGG(单分支)结构,在网络相对较浅的情况下表现出良好的性能。然而,RepVGG不能将ResNet等效地转换为VGG,因为重新参数化方法只能应用于线性块,而非线性层(ReLU)必须放在残差连接之外,这导致了表示能力有限,特别是对于更深层次的网络。
在本文中,旨在解决这个问题,并提出通过ResBlock上的Reserving和Merging(RM)操作等效地去除普通ResNet中的残差连接。RM操作允许输入特征映射通过block,同时保留它们的信息,并在每个block的末尾合并所有的信息,在不改变原始输出的情况下去除残差连接。
RM操作作为一种plugin方法,基本上有3个优点:
其实现使其对高比率网络剪枝比较友好
突破了RepVGG的深度限制
与ResNet和RepVGG相比,RMNet具有更好的精度-速度权衡网络
RMNET: EQUIVALENTLY REMOVING RESIDUAL CONNECTION FROM NETWORKS
论文: https://arxiv.org/abs/2111.00687
代码: https://github.com/fxmeng/RMNet
1简介
自从AlexNet问世以来,CNN最先进的架构变得越来越深入。例如,AlexNet只有5层卷积层,很快VGG网络和GoogLeNet分别将其扩展到19层和22层。然而,简单叠加层的深度网络很难训练,因为梯度反向传播到后面比较深的层时梯度可能会消失和爆炸(重复乘法可能会使梯度无穷小或无穷大)。
标准化初始化和中间标准化层在很大程度上解决了上述问题,它们使具有数十层的网络能够收敛。同时,也暴露出另一个退化问题:随着网络深度的增加,精度趋于饱和,然后迅速退化。
ResNet解决了退化问题,并通过添加一个从块的输入到输出的残差连接来实现1000+层的模型。ResNet不是希望每个堆叠层直接适合所需的底层映射,而是让这些层适合残余映射。当恒等映射是最优的时,将残差推到零比用一堆非线性层来拟合恒等映射更容易。随着ResNet的日益普及,研究者们提出了许多新的基于ResNet的架构,并从不同的方面对其成功进行了解释。
然而,ResDistill指出,ResNet-50中的残差连接约占特性图全部内存使用量的40%,这将减缓推理过程。此外,网络中的残留连接对网络剪枝也不友好。相比之下,VGG-like模型(本文也称plain模型)只有一条路径,速度快、内存经济、并行友好。
RepVGG提出了一种通过在推理时重新参数化来去除残差连接。具体来说,RepVGG将卷积、卷积和identity加在一起进行训练。在每个分支的末端加入BN层,并在加成后加入ReLU。在训练过程中,RepVGG只需要学习残差映射,而在推理阶段,利用重新参数化将RepVGG的基本块转换为卷积层加ReLU运算的堆叠,相对于ResNet有较好的速度-精度权衡。但是作者发现,随着网络的加深,RepVGG的性能会出现严重的下降。
本文提出了一种新的RM操作方法,该方法可以去除内部带有非线性层的残差连接,并保持模型的结果不变。RM操作通过第1卷积层、BN层和ReLU层保留输入的特征映射,然后在ResBlock中通过最后一次卷积将它们与输出的特征映射合并。通过这种方法,可以等价地将预训练的ResNet或MobileNetV2转换为RMNet模型,以增加并行度。此外,RMNet的体系结构使其具有良好的修剪性能,因为它没有残差连接。
主要贡献总结如下:
作者发现用重参数化方法去除残差连接有其局限性,特别是在模型较深的情况下。它是一种非线性运算,不能放在残差连接内进行重新参数化;
提出了一种新的RM操作方法,通过保留输入特征映射并将其与输出特征映射合并,在不改变输出的情况下去除非线性层间的残差连接;
通过RM操作可以将ResBlocks转换为一个卷积和ReLU的堆叠,这有助于得到一个没有残差连接的更深层次的网络,并使其更适应于剪枝。
2相关工作
1、残差网络相对于普通模型的优势
何凯明引入了ResNet来解决退化问题。此外,在PreActResNet中,卷积层的梯度即使在权值任意小的情况下也不会消失,这带来了良好的反向传播特性。Balduzzi等人发现shattered gradients 问题使得DNN训练困难,实验结果表明,标准前馈网络中梯度之间的相关性随深度呈指数衰减。
相比之下,ResNet中的梯度更抗shattered,呈亚线性衰减。Veit等人也指出,残差网络可以看作是多个长度不同路径的集合。从这个观点来看,n个ResNet-Block有条隐式路径连接输入和输出,添加一个Block会使路径的数量增加一倍。
2、无残差连接的DNN
最近的一项工作结合了包括Leaky ReLU、max-norm和初始化在内的几种技术来训练一个30层Plain ConvNet,它可以达到74.6%的top-1精度,比Baseline低2%。
有学者提出了一种基于平均场理论的无分支超深卷积神经网络训练方法。而在CIFAR-10上,1k层普通网络的准确率仅为82%。Balduzzi使用外观线性初始化方法和CReLUs 在CIFAR-10上训练一个198层Plain ConvNet到85%的精度。尽管这些理论贡献颇有见地,但这些模型并不实用。可以通过重新参数化的方式获得没有残差连接的DNN:重新参数化意味着使用一个结构的参数来参数化另一组参数。这些方法首先训练具有残差连接的模型,并在推理时通过重新参数化去除残差连接。
DiracNet采用添加单位矩阵和卷积矩阵进行传播,卷积的参数只需要学习ResNet的残差函数即可。经过训练后,DiracNet将单位矩阵加入到卷积矩阵中,并使用重新参数化的模型进行推理。而DiracNet在ImageNet上只能训练34层Plain ConvNet,准确率为72.83%。
RepVGG只在训练时部署残差神经网络。在推理时,RepVGG可以通过重新参数化将残差块转换为由卷积和ReLU组成的普通模块。
DiracNet和RepVGG的区别在于DiracNet中的每个block都有2个分支(identity without BN和 ConvBN),而RepVGG有3个分支(identity with BN, ConvBN, ConvBN)。然而,那些利用交换性的重新参数化方法只能应用于线性层,即非线性层必须在残差连接之外,这限制了神经网络在大深度的潜力。
3、Filter剪枝
Filter剪枝是一种常见的加速CNN的方法。有学者提出了启发式度量,如卷积核的大小,零激活的平均百分比(APoZ)。也有一些工作让网络自动选择重要的Filter。例如,Liu对BN层的权值进行稀疏化,从而自动找出哪些Filter对网络性能贡献最大。但是,对于基于ResNet的体系结构,由于残差连接的输入和输出的维数必须保持一致,因此残差连接的存在限制了修剪的能力。因此,ResNet的剪枝率不大于plain Model的剪枝率。由于RM操作可以将ResNet等价地转换为一个plain Model,因此转移模型(RMNet)在剪枝方面也有很大的优势。
3Preliminary
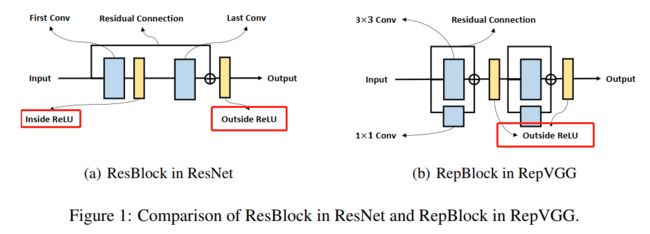
在图1中描述了ResNet和RepVGG中使用的基本块。
在ResBlock(图1(a))中,有2个ReLUs分别为残差连接的内部和外部。而在RepBlock(图1(b)),由于重参数化是基于乘法交换律,2个Relu必须都在残差连接之外。通过用2个Rep-Block替换每个Res-Block,可以从基本的ResNet体系结构构建RepVGG。
接下来,分析了为什么Rep-VGG不能像ResNet一样通过向前和向后的传播进行深度较大模型的训练:
1、前向传播Path
假设ResNet的成功归咎于“model ensemble ”,那么可以把ResNet看作是许多不同长度路径的集合。因此,n个ResNet-Block有条隐式路径连接输入和输出。但是,不同于ResNet Block中的2个分支是可分离的、不能合并的,而RepVGG中的多个分支可以用一个分支来表示,可以表示为:

其中,是分支中每个Conv的合并卷积。因此,RepVGG不具有ResNet隐含的“ensemble assumption ”,同时随着block数量的增加,RepVGG与ResNet之间的表征差距也会增大。
2、反向传播Path
Balduzzi等人分析了深度神经网络中的”shattered gradients problem” 。当向后路径中有更多relu时,梯度的相关性表现为‘White Gaussian Noise’ 。
假设ResNet和RepVGG都有n层。从图1(a)可以看出,ResNet中的Information可以不经过每个block的ReLU内部而通过残差。然而,RepVGG中的每个ReLU都位于主路径中。
因此,ResNet在反向路径中的ReLUs为n/2, RepVGG在反向路径中的ReLUs为n,说明ResNet中的梯度在深度较大时更不易shattered,因此ResNet的性能优于RepVGG。
在图2中研究了网络深度如何影响ResNet和RepVGG的网络性能。作者使用的数据集是CIFAR-10/100。为了公平比较,每个方法都部署了相同的超参数:
Batchsize:256
优化器:SGD
初始学习率(0.1),动量(0.9),权重衰减(0.0005)
Epoch数200
学习率每60 Epoch衰减0.1

从图2可以看出,随着深度的增加,ResNet可以得到更好的精度,这与前面的分析一致。相比之下,RepVGG-133在CIFAR-100上的准确率为79.57%,而RepVGG-133的准确率仅为41.38%。

表1显示了RepVGG和ResNet在ImageNet数据集上的性能。可以看到,在相同的网络结构下,ResNet-18比RepVGG-18高0.5%,而ResNet-34为
top-1准确度比RepVGG高0.8%;因此,RepVGG是以失去表征能力为代价提高了速度。
4RM操作和RMNET:迈向高效的Plain Network
4.1 RM操作
图3显示了RM操作等效去除残差连接的过程。为简单起见,在图中没有显示BN层,输入通道、中间通道和输出通道的数量相同,并赋值为C。

1、Reserving
首先在Conv 1中插入几个Dirac initialized filters(输出通道)。Dirac initialized filters的数量与卷积层输入通道的数量相同。Dirac initialized filters定义为一个4维矩阵:
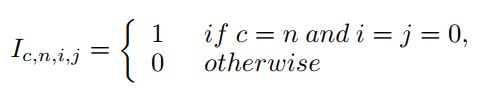
可以在图3(b)中看到这些filters。每个filter只有一个元素1,通过卷积可以保留输入特征映射对应通道的信息。
对于BN层,为了保留输入的feature map,需要调整BN中的权值w和偏差b使BN层表现得像一个恒等函数。
假设feature map的running mean和running variance分别为和,设,偏差。然后任意输入x通过BN层,输出为:

其中,
对于ReLU层,有2种情况需要考虑:
当通过残差连接的输入值是非负的(即,在ResNet中,每个ResBlock有一个后面的ReLU层,它保持输入值都是非负的),我们可以直接使用ReLU来保留信息。因为ReLU不会改变非负数的值;
当通过剩余连接的输入值为负时(例如,在MobileNetV2中,ReLU只位于ResBlock的中间),我们使用PReLU而不是ReLU来保留信息。PReLU关于附加通道的参数设置为1。这样,PReLU的行为就像一个Identity函数。
由以上分析可知,在ResBlock中,Conv 1、BN和ReLU可以很好地保留输入的Feature map。
2、Merging
作者这扩展了Conv2中的输入通道然后dirac initialize这些通道。第i个通道的值z是原始的第i个滤波器输出与原始ResBlock中第i个输入特征映射的和,等于。整个Merging过程可以表述为:
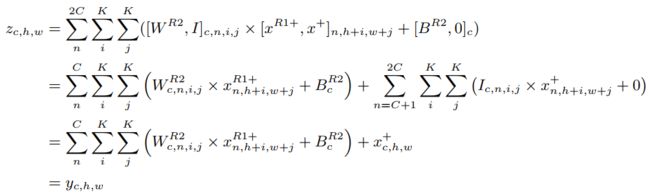
其中,为concat操作。
因此,通过reserving和merging可以在不改变ResBlock原始输出的情况下删除残差连接。
参考下图,Pytorch实现如下:

def deploy(self, merge_bn=False):
"""
self.mid_planes = mid_planes - out_planes + in_planes
self.conv1 = nn.Conv2d(in_planes, self.mid_planes - in_planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.mid_planes - in_planes)
self.conv2 = nn.Conv2d(self.mid_planes - in_planes, out_planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
"""
idconv1 = nn.Conv2d(self.in_planes, self.mid_planes, kernel_size=3, stride=self.stride, padding=1, bias=False).eval()
idbn1=nn.BatchNorm2d(self.mid_planes).eval()
# dirac初始化矩阵,中心为 1 的矩阵
nn.init.dirac_(idconv1.weight.data[:self.in_planes])
# dirac初始化矩阵 BN 层权重计算
bn_var_sqrt=torch.sqrt(self.running1.running_var + self.running1.eps)
# 对于cat后半部分的BN作用进行赋值,主要还是 running_mean,running_var,weight,bias
# dirac初始化矩阵 weight 的赋值
idbn1.weight.data[:self.in_planes]=bn_var_sqrt
# dirac初始化矩阵 bias 的赋值
idbn1.bias.data[:self.in_planes]=self.running1.running_mean
# dirac初始化矩阵 running_mean 的赋值
idbn1.running_mean.data[:self.in_planes]=self.running1.running_mean
# dirac初始化矩阵 running_var 的赋值
idbn1.running_var.data[:self.in_planes]=self.running1.running_var
# 原始特征矩阵 卷积 weight 的赋值
idconv1.weight.data[self.in_planes:]=self.conv1.weight.data
# 原始特征矩阵 BN层 weight 的赋值
idbn1.weight.data[self.in_planes:]=self.bn1.weight.data
# 原始特征矩阵 BN层 bias 的赋值
idbn1.bias.data[self.in_planes:]=self.bn1.bias.data
# 原始特征矩阵 BN层 running_mean 的赋值
idbn1.running_mean.data[self.in_planes:]=self.bn1.running_mean
# 原始特征矩阵 BN层 running_var 的赋值
idbn1.running_var.data[self.in_planes:]=self.bn1.running_var
# 实例化一个 cat channel 后的卷积
idconv2 = nn.Conv2d(self.mid_planes, self.out_planes, kernel_size=3, stride=1, padding=1, bias=False).eval()
idbn2=nn.BatchNorm2d(self.out_planes).eval()
# 进行 Conv2 的操作
downsample_bias=0
if self.in_planes==self.out_planes:
# Channel number 不变的话,直接对idconv2的后部分进行dirac初始化
nn.init.dirac_(idconv2.weight.data[:,:self.in_planes])
else:
# Channel number 变化的话,这时需要考虑downsample的weight,bias,然后进行融合,在4.4部分有说明
idconv2.weight.data[:,:self.in_planes],downsample_bias=self.fuse(F.pad(self.downsample[0].weight.data, [1, 1, 1, 1]),self.downsample[1].running_mean,self.downsample[1].running_var,self.downsample[1].weight,self.downsample[1].bias,self.downsample[1].eps)
idconv2.weight.data[:,self.in_planes:],bias=self.fuse(self.conv2.weight,self.bn2.running_mean,self.bn2.running_var,self.bn2.weight,self.bn2.bias,self.bn2.eps)
# 对于idbn2阶段的赋值,主要还是 running_mean,running_var,weight,bias
bn_var_sqrt=torch.sqrt(self.running2.running_var + self.running2.eps)
idbn2.weight.data=bn_var_sqrt
idbn2.bias.data=self.running2.running_mean
idbn2.running_mean.data=self.running2.running_mean+bias+downsample_bias
idbn2.running_var.data=self.running2.running_var
# 推理时融合Conv + bn
if merge_bn:
return [torch.nn.utils.fuse_conv_bn_eval(idconv1,idbn1),self.relu,torch.nn.utils.fuse_conv_bn_eval(idconv2,idbn2),self.relu]
else:
return [idconv1,idbn1,self.relu,idconv2,idbn2,self.relu]4.2 Pruning RMNet
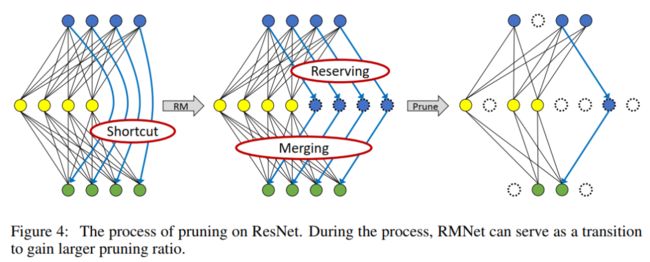
由于RMNet没有任何残差连接,因此它对filter 剪枝更友好。本文采用Network slimming对RMNet进行slimming,因为它简单、有效。具体来说,
首先训练ResNet并稀疏化BN层的权值。注意,在训练时应在残差连接中添加一个额外的BN层,因为还需要确定RM操作后哪些额外的filter是重要的。
训练完成后,将ResNet转换为RMNet,根据BN层的权值对filter进行修剪,这与vanilla Network slimming相同。图4显示了剪枝的整体过程。与传统方法不同的是,RMNet可以作为一个过渡来获得更大的剪枝率。
4.3 使用RM操作提升RepVGG
RM Operation作为一种’plug-in’ 方法,可以帮助RepVGG在深度较大的情况下获得更好的性能。
如图5所示,训练了一个具有残差连接的网络。通过通道将输入特征图分割为预定义保留比例的两部分。
输入特征图左侧信息流为:RepVGG
输入特征图右侧信息流为:ResNet
通过RM操作,可以利用第一层的一些通道来保留输入的feature map,之后的ReLU不会改变它的值。第二层是RepBlock,可以将保留的输入特征图合并到输出特征图中。接下来,可以使用重新参数化将RepBlocks转换为PlainBlocks。这种设计的好处是打破了RepVGG的深度限制,因为保留的输入通道可以帮助模型更好地学习。

4.4 把MobileNetv2转化为MobleNetv1
从技术上讲,RM操作转换ResNet和使用MobileNetV2之间没有区别。然而,MobileNetV2结构的特殊性使得RM操作后的参数融合可以进一步减少推理时间。

从图6中可以看出,在MobileNetV2上应用RM操作后残差被删除,这使得虚线框中合并出2个Pointwise-ConvBN。由于卷积和批处理归一化都可以用矩阵乘法表示,而且它们之间不存在非线性层,因此这2个Pointwise-ConvBN层可以进行融合。
这里让X, Y, W B为虚框内第1个Pointwise-ConvBN层的输入特征、输出特征、权重和偏置;让为虚框内第2个Pointwise-ConvBN层的输出特征、权重和偏置。那么,参数融合的过程可以表示为:

fused weight为,fused bias为。因此,RM操作提供了另一个机会,通过融合参数进一步减少推理时间。经过参数融合后,RMNet的架构与MobileNetV1相同,这一点非常有趣,因为MobileNetV2的存在是为了利用残差连接来提高MobileNetV1的泛化能力。然而,本文证明了RM操作可以反转这个过程,即将MobileNetV2转换为MobileNetV1,使MobileNetV1再次伟大。
Pytorch实现融合如下:
def fuse(conv_w, bn_rm, bn_rv,bn_w,bn_b, eps):
bn_var_rsqrt = torch.rsqrt(bn_rv + eps)
conv_w = conv_w * (bn_w * bn_var_rsqrt).reshape([-1] + [1] * (len(conv_w.shape) - 1))
conv_b = bn_rm * bn_var_rsqrt * bn_w-bn_b
return conv_w,conv_b5实验
5.1 剪枝友好
作者进行了一个如图7所示的实验来验证RMNet剪枝的有效性。这里利用L1范数乘以某个稀疏性因子来惩罚BN层的权值,将权值小于某一阈值的通道视为无效同通道。稀疏性因子从[1e-4,1e -3],阈值选取[5e- 4,5e -3]。稀疏度和阈值越大,剪枝率越高。

实验表明,在相同速度下,修剪后的RMNet比修剪前的ResNet具有更高的准确率。剪枝率相同时,剪枝RMNet的速度要快于剪枝ResNet,这是因为剪枝RMNet的结构更加合理。因此,RMNet与ResNet架构相比,在剪枝任务上有更好的准确性和速度-权衡。
5.2 打破RepVGG的深度限制
作者在CIFAR-10/100和ImageNet上进行了实验以评估RM操作在网络加深时是否能够提供帮助,以让RepVGG可以获得更好的性能。如图8所示绘制不同预留比率下的性能曲线。为了进行公平的比较,ImageNet上的实验遵循了RepVGG的官方实现。

从4.3可知,原始RepVGG在深度较小时性能较好,而在深度增加时性能略有下降。而带有RM操作的RepVGG可以随着深度的增加而保持良好的性能。
例如,当RepVGG为21或37层时,保留25%的输入特征图通道依然表现得更好;当RepVGG为69层时,保留50%的输入特征图通道效果更好;当RepVGG为133层时,保留75%的输入特征图通道效果更好。
结果表明,浅层网络需要更多的参数和更小的残差连接(小预留比),而深层网络需要更多的残差连接(大预留比)。因此,实验表明,本文的设计可以打破RepVGG的深度限制。
5.3 轻量化模型友好
在第4.4节中进行了一个实验来验证分析。首先按照4.4节中介绍的过程从头开始训练一个MobileNetV2,并将其转换为RMNetV1(即MobileNetV1)。注意,MobileNetV2的初始架构必须重新设计,以确保转换后的RMNetV1具有与原始论文中的MobileNetV1相同的架构(深度和宽度)。因此,图6中的MobileNetV2与普通的MobileNetV2不同。为了便于比较,还从头开始训练了一个MobileNetV1。结果如表2所示:
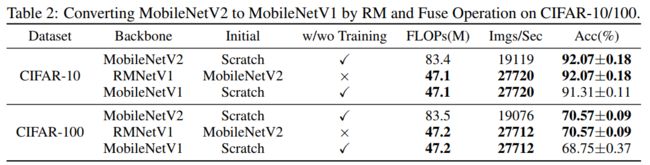
从表2的实验中可以看到RMNetV1的速度(等效转换为MobileNetV2)比MobileNetV2快,RMNetV1的性能比MobileNetV1高,这表明RM操作对于轻量级模型非常友好。
5.4 SOTA对比

从表3可以看出,在相同的速度下,RMNet 50×6 32的准确率比ResNet 101高2.3%,比RepVGG B2高0.59%。值得注意的是,RMNet 101×6 16在没有使用任何技巧的情况下达到了80%以上的top-1准确率,据论文描述这是一个普通模型的第一次达到这个精度。此外,将深度增加到152仍然对RMNet有好处,这显示了本文方法的巨大潜力。
RMNet论文和代码下载
后台回复:RM,即可下载上述论文和代码(链接)
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看