Hadoop生态圈hive应用
第 1 章 Hive 基本概念
1.1 什么是 Hive
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并
提供类 SQL 查询功能。
1.2 Hive 的优缺点
1.2.1 优点
1) 操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
2) 避免了去写 MapReduce,减少开发人员的学习成本。
3) Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
4) Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较
高。
5) Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
1.2.2 缺点
1.Hive 的 HQL 表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗
1.3 Hive 架构原理

图 1-2 Hive 架构原理
1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java 访问 hive)、WEBUI(浏览器访问 hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表
的类型(是否是外部表)、表的数据所在目录等;
3.Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用
第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存
在、SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来
说,就是 MR/Spark。
第 2 章 Hive 安装2.1 Hive 安装部署
2.2.1 Hive 安装及配置
1)修改 apache-hive-1.1.0-bin 的名称为 hive
[hadoop@master1 software]$ cd /opt/module
[hadoop@master1 module]$ ll
total 0
drwxrwxr-x 8 hadoop hadoop 159 Nov 24 10:36 apache-hive-1.1.0-bin
drwxr-xr-x 16 hadoop hadoop 275 Nov 23 06:52 hadoop-2.6.0
drwxr-xr-x 8 hadoop hadoop 176 Nov 22 03:30 jdk1.6.0_45
drwxr-xr-x 8 hadoop hadoop 255 Nov 22 03:29 jdk1.8.0_171
[hadoop@master1 module] mv apache-hive-1.2.1-bin/ hive2)拷贝/opt/module/hive/conf 目录下的 hive-env.sh.template 名称为 hive-env.sh
[hadoop@master1 conf]$ cp hive-env.sh.template hive-env.sh3)配置 hive-env.sh 文件
-
- (a)添加配置
export HADOOP_HOME=/opt/module/hadoop-2.6.0-
- (b)添加配置
export HIVE_CONF_DIR=/opt/module/hive/conf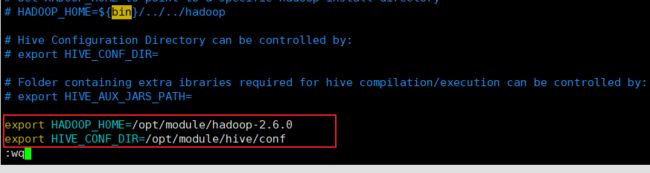
2.2.2 Hadoop 集群配置
(1)启动 hdfs 和 yarn
[hadoop@master1 hadoop-2.6.0]$ sbin/start-dfs.sh
[hadoop@master1 hadoop-2.6.0]$ sbin/start-yarn.sh(2)在 HDFS 上创建/tmp 和/user/hive/warehouse 两个目录
[hadoop@master1 hadoop-2.6.0]$ bin/hadoop fs -mkdir /tmp
[hadoop@master1 hadoop-2.6.0]$ bin/hadoop fs -mkdir -p /user/hive/warehouse2.2.3 Hive 基本操作
(1)启动 hive
[hadoop@master1 hive]$ bin/hive
(2)查看数据库
hive> show databases;
(3)打开默认数据库
hive> use default;
(4)显示 default 数据库中的表
hive> show tables;
(5)创建一张表
hive> create table student(id int, name string);
(6)显示数据库中有几张表
hive> show tables;
(7)查看表的结构
hive> desc student;
(8)向表中插入数据
hive> insert into student values(1000,"ss");
(9)查询表中数据
hive> select * from student;
(10)退出 hive
hive> quit;
2.3、 将本地文件导入 Hive 案例
需求:
将本地/opt/module/data/student.txt 这个目录下的数据导入到 hive 的 student(id int, name
string)表中。
1.数据准备:
2.Hive 实际操作:
(1)启动 hive
[hadoop@master1 hive]$ bin/hive(2)显示数据库
hive> show databases;(3)使用 default 数据库
hive> use default;(4)显示 default 数据库中的表
hive> show tables;(5)删除已创建的 student 表
hive> drop table student;(6)创建 student 表, 并声明文件分隔符’\t’
hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';(7)加载/opt/module/data/student.txt 文件到 student 数据库表中。
hive> load data local inpath '/opt/module/datas/student.txt' into table student;(8)Hive 查询结果
hive> select * from student;
OK
1001 zhangshan
1002 lishi
1003 zhaoliu
Time taken: 0.266 seconds, Fetched: 3 row(s)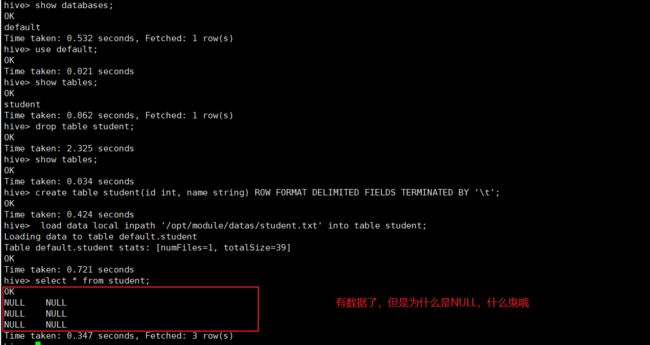
2.4 MySql 安装
2.4.1 安装包准备
2.4.2 查看 mysql 是否安装,如果安装了,卸载 mysql(root下)
(1)查看
[hadoop@master1 ~]# su
[root@master1 ~]# rpm -qa|grep mysql
mysql-libs-5.1.73-7.el6.x86_64
(2)卸载
[root@master1 ~]# rpm -e --nodeps
mysql-libs-5.1.73-7.el6.x86_642.4.3.解压 mysql压缩 文件到当前目录
[root@master1 software]# tar -xvf mysql-5.7.28-linux-glibc2.12-x86_64.tar //解压 tar包
#出现两个 tar.gz文件,解压下面这个。另一个删除即可。
[root@master1 software]# tar -xvf mysql-5.7.28-linux-glibc2.12-x86_64.tar.gz
2.4.4、MySQL主目录处理
在software目录下移动文件到/usr/local/mysql:
[root@master1 software]# mv mysql-5.7.28-linux-glibc2.12-x86_64 /usr/local/mysql
[root@master1 mysql]# mkdir data
2.4.5、主目录权限处理
查看组和用户情况:
[root@master1 mysql]# cat /etc/group | grep mysql
[root@master1 mysql]# cat /etc/passwd |grep mysql
若存在,则删除原mysql用户:userdel -r mysql,会删除其对应的组和用户。(没有则跳过)

在查看就会发现没有,说明你已经删掉了。

创建mysql组和mysql用户。
[root@master1 mysql]# groupadd mysql
[root@master1 mysql]# useradd -r -g mysql mysql![]()
2.4.6、创建配置文件及相关目录
修改配置文件:/etc/my.cnf,配置不对的话,后面初始化不全,会拿不到默认密码。
[root@master1 mysql]# vim /etc/my.cnf
#修改内容
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
port = 3306
socket=/tmp/mysql.sock
pid-file=/tmp/mysqld/mysqld.pid
character-set-server = utf8
log-error=/var/log/mysqld.log:wq! 保存退出。
创建文件/tmp/mysql.sock:设置用户组及用户,授权
[root@master1 etc]# cd /tmp
[root@master1 tmp]# touch mysql.sock
[root@master1 tmp]# chown mysql:mysql mysql.sock
创建文件 /tmp/mysqld/mysqld.pid:
mkdir mysqld
cd mysqld
touch mysqld.pid
cd ..
chown -R mysql:mysql mysqld
cd mysqld
chmod 755 mysqld.pid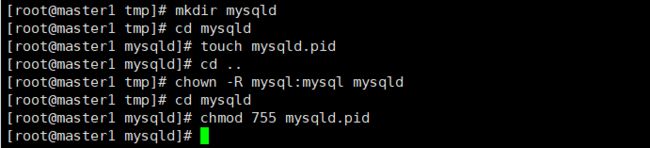
创建文件 /var/log/mysqld.log:
2.4.7、安装和初始化数据库
(1)进入bin目录,初始化数据库:
[root@master1 bin]# cd /usr/local/mysql/bin/
[root@master1 bin]# ./mysqld --initialize --user=mysql --basedir=/usr/local/mysql--datadir=/usr/local/mysql/data
![]()
(2)安全启动:
./mysqld_safe --user=mysql &
![]()
是否启动成功,可以通过查看mysql进程,ps -ef | grep mysql

默认密码在mysqld.log日志里, 找到后保存到安全的地方:
cat /var/log/mysqld.log

其中root@localhost: 后面的就是默认密码,后面登录用.(如果找不到可能默认是空,登录时密码直接回车,否则可能安装有问题)
(3)登录mysql:
拷贝或者输入mysqld.log中获得的默认密码,即可进入mysql命令客户端。
[root@master1 bin]# cd /usr/local/mysql/bin/
[root@master1 bin]# ./mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.28
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> 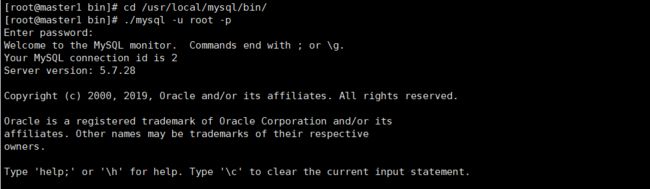
show databases;
![]()
假设密码修改为:123456
mysql> set password=password("123456");
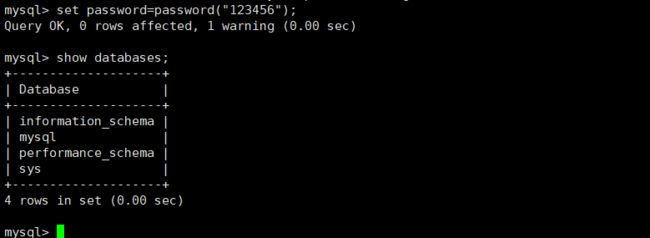
(4)开机服务启动设置:
把support-files/mysql.server 拷贝为/etc/init.d/mysql
查看是否拷贝成功
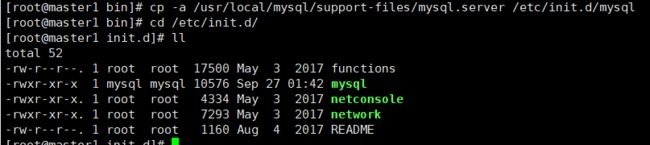
查看mysql服务是否在服务配置中:
[root@master1 init.d]# chkconfig --list mysql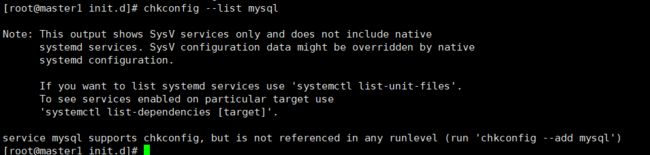
(5)启动 或 停止MySQL:
[root@master1 init.d]# service mysql stop
Shutting down MySQL.. SUCCESS!
[root@master1 init.d]# service mysql start
Starting MySQL. SUCCESS!
[root@master1 init.d]# service mysql status
SUCCESS! MySQL running (8121)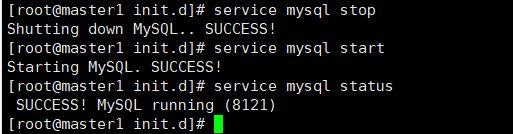
2.4.8、 MySql 中 user 表中主机配置
配置只要是 root 用户+密码,在任何主机上都能登录 MySQL 数据库。
1.进入 mysql
[root@hadoop102 mysql-libs]# mysql -uroot -p1234562.显示数据库
mysql>show databases;3.使用 mysql 数据库
mysql>use mysql;4.展示 mysql 数据库中的所有表
mysql>show tables;5.展示 user 表的结构
mysql>desc user;6.查询 user
mysql>select User, Host, passwd from user;7.修改 user 表,把 Host 表内容修改为%
mysql>update user set host='%' where host='localhost';8.删除 root 用户的其他 host
delete from user where Host='hadoop102';
delete from user where Host='127.0.0.1';
delete from user where Host='::1';9.刷新
mysql>flush privileges;
10.退出
mysql>quit;
2.5 Hive 元数据配置到 MySql
2.5.1 配置 Metastore 到 到 MySql
1.创建一个 hive-site.xml
[hadoop@master1 conf]$ ls
beeline-log4j.properties.template hive-default.xml.template hive-env.sh hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
[hadoop@master1 conf]$ touch hive-site.xml
[hadoop@master1 conf]$ vim hive-site.xml2.根据官方文档配置参数,拷贝数据到 hive-site.xml 文件中
https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin

3.配置完毕后,如果启动 hive 异常,可以重新启动虚拟机。(重启后,别忘了启动 hadoop 集群)
[hadoop@master1 hive]$ bin/hive2.5.2 多窗口启动 Hive 测试
1.先启动 MySQL
[hadoop@master1 hive]$ mysql -uroot -p123456
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec)2.再次打开多个窗口,分别启动 hive
[hadoop@master1 hive]$ bin/hive3.启动 hive 后,回到 MySQL 窗口查看数据库,显示增加了 metastore 数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| metastore |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec)2.6 HiveJDBC 访问
2.6.1 启动 hiveserver2 服务
[hadoop@master1 hive]$ bin/hiveserver2
2.6.2 另开窗口:启动 beeline
PS:启动完 hiveserver后,出现和启动hive一样的五条提示信息。然后停止在本界面
需要,重新在开一个窗口 启动 beeline
[hadoop@master1 hive]$ bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline>
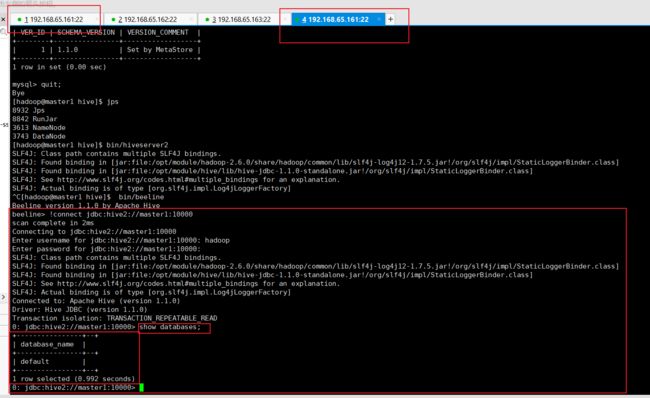
2.6.3 连接 hiveserver2
beeline> !connect jdbc:hive2://master1:10000
scan complete in 2ms
Connecting to jdbc:hive2://master1:10000
Enter username for jdbc:hive2://master1:10000: hadoop
Enter password for jdbc:hive2://master1:10000:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hive/lib/hive-jdbc-1.1.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Connected to: Apache Hive (version 1.1.0)
Driver: Hive JDBC (version 1.1.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://master1:10000> show databases;
+----------------+--+
| database_name |
+----------------+--+
| default |
+----------------+--+
1 row selected (0.992 seconds)
0: jdbc:hive2://master1:10000>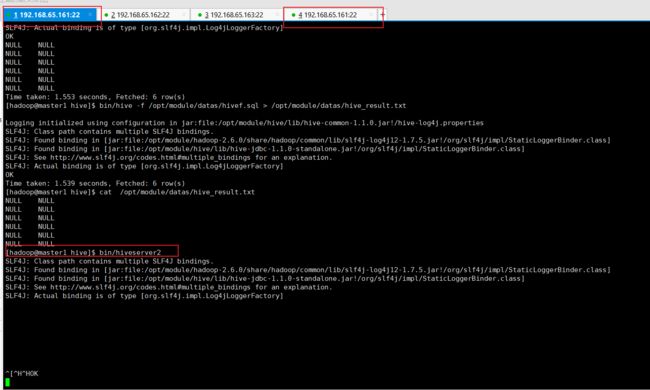
2.7 Hive 常用交互命令
[atguigu@hadoop102 hive]$ bin/hive -help1.“-e”不进入 hive 的交互窗口执行 sql 语句
[hadoop@master1 hive]$ bin/hive -e "select id from student;"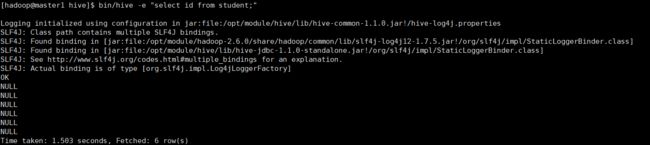
2.“-f”执行脚本中 sql 语句
(1)在/opt/module/datas 目录下创建 hivef.sql 文件
[hadoop@master1 hive]$ touch hivef.sql
[hadoop@master1 hive]$ vim hivef.sql
#文件中写入正确的 sql 语句
select * from student;
[hadoop@master1 hive]$ mv hivef.sql /opt/module/datas/(2)执行文件中的 sql 语句
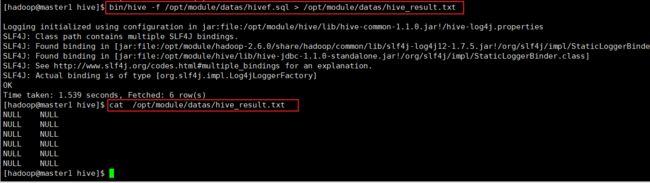
[hadoop@master1 hive]$ bin/hive -f /opt/module/datas/hivef.sql
(3)执行文件中的 sql 语句并将结果写入文件中
[atguigu@hadoop102 hive]$ bin/hive -f /opt/module/datas/hivef.sql > /opt/module/datas/hive_result.txt