【C语言进阶篇】字符和字符串函数 - 总有一款适合你
目录
- 前言
- strlen - 统计字符串长度
- strcpy - 字符串拷贝
- strncpy - 指定长度的字符串拷贝
- strcat - 字符串追加
- strncat - 指定长度的字符串追加
- strcmp - 字符串比较
- strncmp - 指定长度的字符串比较
- strstr - 子字符串查找
- strtok - 分割字符串
- strerror - 获取报错信息
- 字符分类函数
- 小尾巴
前言
本文将参照 MSDN 详细介绍几种使用较为频繁的字符和字符串函数。它们分别是 strlen 、strcpy 、strcat 、strcmp 、strncpy 、strncat 、strncmp 、strstr 、strtok 、strerror ,并通过模拟实现其中部分函数来加深对其实现机制的认识。
此外,每个函数还设置了超链接。点击即可查看较为官方的解释,链接网址均来自 cplusplus.com 。
strlen - 统计字符串长度
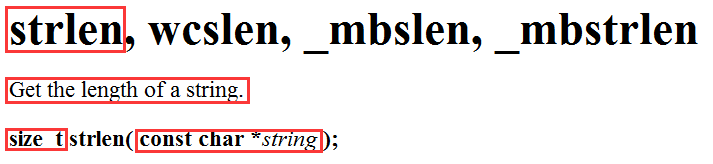
可以看到,它的作用是获取字符串的长度;返回类型是 unsigned int ,返回的是字符串的长度;参数是一个 char* ,是要计算长度的字符串首字符的首地址。
我们知道,字符串是以 \0 结尾,所以 strlen 是会沿着传过来的地址向后走,直至找到 \0 。所以在传参时,要保证传过去的字符串是以 \0 结尾的。
此外,它的返回值是字符串的长度,这个长度不包含 \0。
下面是它的一个正当使用范例:

知道了它的功能,想要模拟实现是比较简单的,下面给出三种实现方法,分别用到了计数器、递归和指针-指针,其核心思想都是找到 \0 :
//计数器
int my_strlen(const char * str)
{
int count = 0;
while(*str)
{
count++;
str++;
}
return count;
}
//递归
int my_strlen(const char * str)
{
if(*str == '\0')
return 0;
else
return 1+my_strlen(str+1);
}
//指针 - 指针
int my_strlen(char *s)
{
char *p = s;
while(*p != ‘\0’ )
p++;
return p-s;
}
strcpy - 字符串拷贝
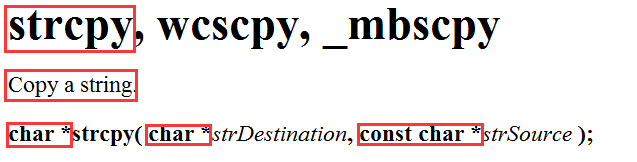
可以看到,它的作用是复制一个字符串;返回类型为 char* ,返回的是拷贝后字符串首字符地址;参数是两个 char*:前面的那个是用于接收的字符串地址,后面的那个是要复制的字符串地址,由于不用改变它,所以用 const 修饰,增加代码的安全性。
在拷贝字符串时,源字符串一定是以 \0 结尾,而且 \0 也会一并拷贝到接收字符串中。接收字符串从首地址开始接收,原来的内容会被替换掉。
在拷贝字符串时,要保证接收字符串的大小不比源字符串的小,这样才能保证拷贝的安全性。
此外,由于接收字符串是要被替换的,所以还要保证它是可变字符串,能被赋值。
下面是它的一个正当使用范例:

如果想编写一个函数实现 strcpy 的功能也不难,将接收字符串的每个字符都替换成源字符串对应位置的字符即可:
char *my_strcpy(char *dest, const char*src)
{
char *ret = dest;
assert(dest != NULL);
assert(src != NULL);
while((*dest++ = *src++));
return ret;
}
稍微解释一下, assert() 是断言,需要引头文件
如果括号内的表达式值为假就会报错,这里是防止传过来空指针。
地址在向后走的过程中, dest 是会增加的,所以拷贝完之后它已经不是接收字符串的首地址了,故创建变量 ret 临时保存。
那如果我想只拷贝源字符串的几个字符,上面这个函数就无法完成,所以就引出了下面一个函数。
strncpy - 指定长度的字符串拷贝

它与 strcpy 的唯一不同就是多了一个参数 unsigned int ,也就是要复制字符的个数。
函数会拷贝 count 个字符从源字符串到目标空间,如果源字符串的长度小于 count ,则拷贝完源字符串之后,在目标的后边追加 \0 ,直到够 count 个。
下面是它的一个正当使用范例:

而它的模拟实现与 strcpy 也是大差不差,只是拷贝方式变了:
char* my_strncpy(char* dest, const char* src, unsigned int count)
{
assert(dest != NULL);
assert(src != NULL);
char* ret = dest;
while (count && (*dest++ = *src++))
count--;
if (count)
while (--count)
*dest++ = '\0';
return ret;
}
strcat - 字符串追加
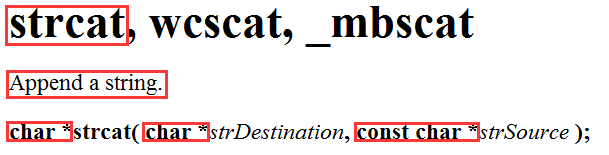
可以看到,它的作用是添加一个字符串;返回值是 char* ,返回添加字符后字符串的首字符地址;参数是两个 char* ,第一个是接收字符串首字符的地址,第二个是要添加字符串的首字符地址,由于不需要改变它,所以用 const 修饰。
函数会将 strSource 追加到 strDestination 后面,并以一个空字符结束结果字符串,且 strSource 的起始字符将覆盖结束 strDestination 的空字符,即 \0 。
所以,两个作为参数的字符串都需以 \0 结尾。另外,与上个函数一样,接收字符串的大小要容得下追加的字符串,且必须是可修改的变量字符串。
但是,这个函数无法实现在字符串后面追加自己,原因在模拟实现后会做出解释。
下面是它的一个正当使用范例:

想要实现追加字符串,就要先找出接收字符串中 \0 的位置,在此之后进行赋值操作,所以实现代码如下:
char *my_strcat(char *dest, const char*src)
{
char *ret = dest;
assert(dest != NULL);
assert(src != NULL);
while(*dest++);
dest--;
while((*dest++ = *src++));
return ret;
}
现在回答上面那个问题,如果要在字符串后面追加它自己,那接收参数 src 就要改成 dest ,在追加的时候就无法给字符赋值了。
与上面一样,如果我只想追加部分字符,此时又有下面的函数。
strncat - 指定长度的字符串追加
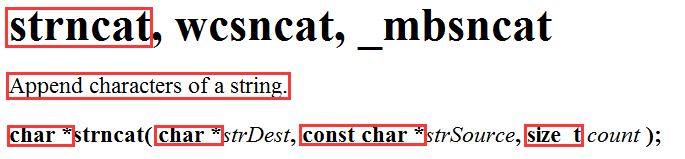
它与 strcat 的唯一不同之处也是参数多了一个 unsigned int ,是要追加字符的个数。
函数会将源字符串中前 count 个字符追加到目标字符串之后。
如果源字符串长度小于 count ,则与 strcat 完全相同,源字符串的自动代替 count 不会补 \0。
下面是它的一个正当使用范例:

如果想编写函数模拟实现它的功能也只需改动追加字符串部分:
char* strncat (char* dest, const char* src, unsigned int count)
{
assert(dest != NULL);
assert(src != NULL);
char* ret = dest;
while (*dest++);
dest--;
while (count--)
if (*dest++ = *src++)
return ret;
*dest = '\0';
return ret;
}
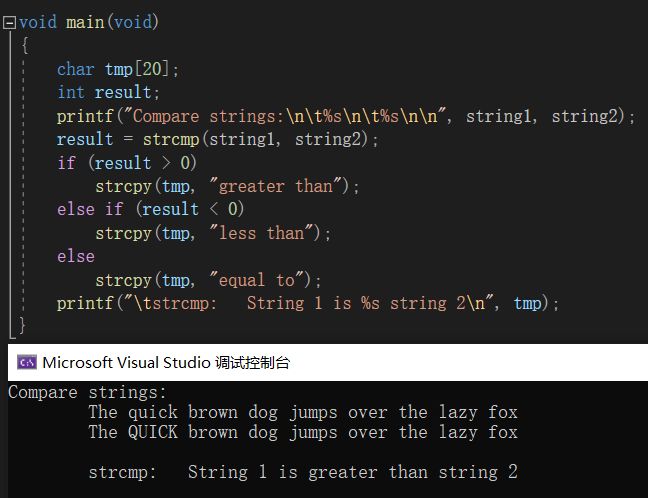
strcmp - 字符串比较
有些场景下我们会比较两个字符串,字符可以直接比较,但字符串不能,这时 strcmp 函数就派上用场了。

可以看到,它的功能是比较字符串;返回类型为 int ;参数是两个 char* ,即要进行比较的两个字符串的首字符地址,由于不用改变,所以用 const 修饰。
对于它的返回值,参考如下:

这个函数开始比较每个字符串的第一个字符。如果它们相等,则继续比较后面的字符,直到字符不同或到达一个结束的空字符为止。
这里的 strcmp 函数按字典顺序,也就是ASCII表,比较 string1 和 string2 ,并返回指示它们关系的值。
下面是它的一个正当使用范例:
设计一个函数实现它的功能的话也不难:
int my_strcmp(const char* src, const char* dest) {
assert(src != NULL);
assert(dest != NULL);
while (!(*(unsigned char*)src - *(unsigned char*)dest) && *dest)
{
src++;
dest++;
}
return *src - *dest;
}
好事那个老问题,现在我又不想比较两个字符串的全部内容,只比较部分,那就又有下面一个函数供你使用。
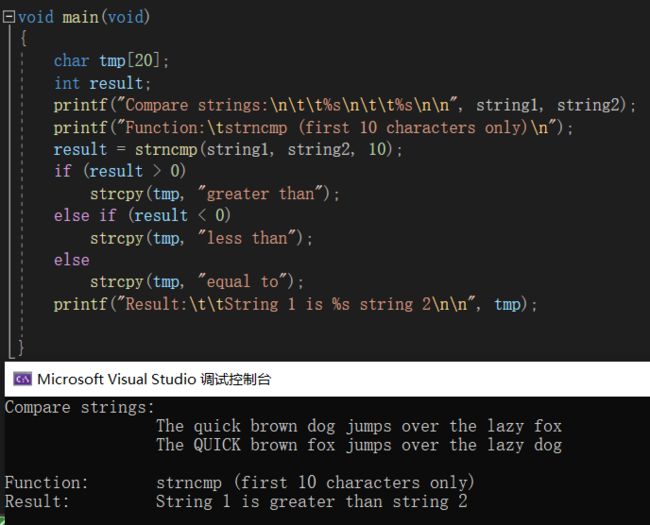
strncmp - 指定长度的字符串比较

它与 strcmp 的唯一区别也是参数部分多了一个 unsigned int ,即想要比较两个字符串的前 count 个字符。
下面是它的一个正当使用范例:
它的模拟实现思路和上面的几个也是大差不差:
int my_strncmp(const char* str1, const char* str2, unsigned int count)
{
assert(str1 != NULL);
assert(str2 != NULL);
while (count && str1 && str2)
{
if (!(*(unsigned char*)str1++ - *(unsigned char*)str2++))
count--;
else
return *str1 - *str2;
}
return *str1 - *str2;
}
strstr - 子字符串查找

它的作用比较独特,是在一个字符串中寻找子字符串。举个例子,现在有两个字符串:
char arr1[] = "abcdef";
char arr2[] = "bcd";
那么就可以在 arr1 中找到 arr2。
函数的返回类型是 char* 。它会返回一个指向 strCharSet 在 string 中首次出现的指针;如果 strCharSet 没有在 string 中出现,则返回 NULL ;如果 strCharSet 指向长度为 0 的字符串,则函数返回 string 。
下面看一个使用实例:

显然能在 str[ ] 中找到 simple ,所以它会返回 str[ ] 中第一次出现 simple 时 s 的地址;
把这个地址存放在 pch 中,此时 pch 就指向 str[ ] 中 simple 的首字符 s ;
再对 pch 调用 strncpy 函数,pch 自身和它后面的5个字符都被替换为sample。
它的模拟实现如下,其中有几个需要注意的点:
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 != NULL);
assert(str2 != NULL);
char* s1;
char* s2;
if (!*str2)
return (char*)str1;
while (*str1)
{
s1 = str1;
s2 = (char*)str2;
while (*s1 && *s2 && !(*s1 - *s2))
s1++, s2++;
if (!*s2)
return str1;
str1++;
}
return NULL;
}
第一,如果接收到的 str2 是个空字符,直接返回 str1;
第二,要从字符串中寻找子字符串,则需要从字符串的首字符开始寻找。如果前几个都匹配上了,最后突然匹配不上,此时主字符串需要重置并往后走一个,子字符串需要重置。
strtok - 分割字符串

这个函数就比较有意思了。
strDelimit 参数是个字符串,定义了用作分隔符的字符集合;
strToken 指定一个字符串,它包含了0个或者多个由 strDelimit 字符串中一个或者多个分隔符分割的标记。
strtok 函数找到 strToken 中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok 函数会改变被操作的字符串,所以在使用 strtok 函数切分的字符串一般都是临时拷贝的内容并且可修改。)
函数的第一个参数不为 NULL 时,函数将找到strToken 中第一个标记,strtok 函数将保存它在字符串中的位置。
函数的第一个参数为 NULL 时,由于上一次调用时函数保存了strToken 中第一个标记的位置,所以这次会在同一个字符串中被保存的位置开始,查找下一个标记。
如果字符串中不存在更多的标记,则返回 NULL 指针。
下面是它的一个使用范例:
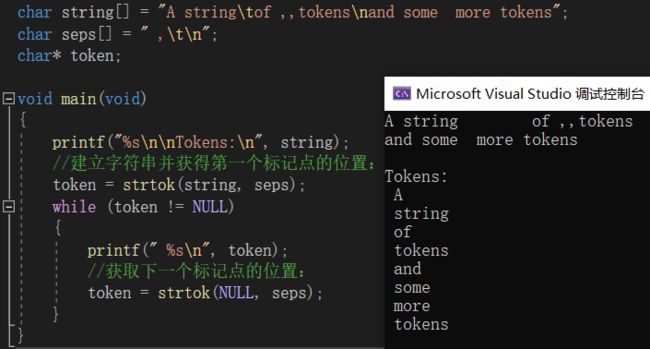
由于这个函数实现难度较大,在下精力有限,心有余而力不足。
strerror - 获取报错信息

这个函数就比较单纯了,给它错误码,返回给你错误信息。
不过需要注意的是,这个函数必须要引头文件
可以看看下面几种错误码对应的错误信息:
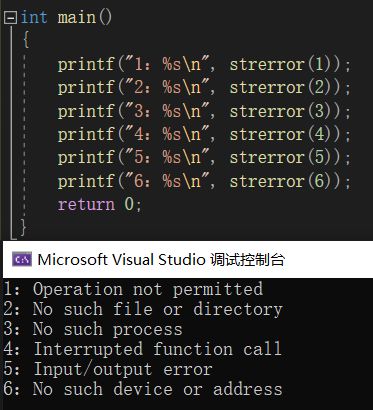
再看一个使用范例:
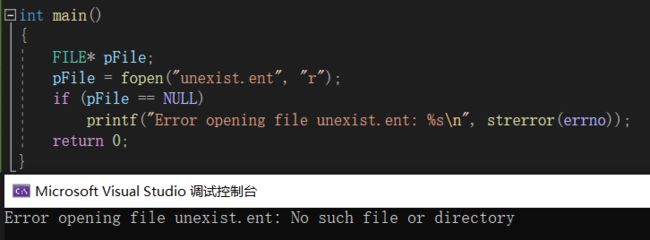
这个程序试图打开一个名为 unexist.ent 的文件。但这个文件不存在,所以会返回错误信息:没有该文件。
字符分类函数
有时我们可能需要判断某个字符是什么类型,下面提供了几种字符分类函数的简介:
| 函数 | 如果参数符合下列条件就返回真 |
|---|---|
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行’\n’,回车‘\r’,制表符’\t’或者垂直制表符’\v’ |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母a ~ f,大写字母A ~ F |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母a ~ z或A ~ Z |
| isalnum | 字母或者数字,a ~ z, A ~ Z, 0 ~ 9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
小尾巴
本文只是详细介绍了几种常用的字符串函数和简介了一些字符分类函数,其中用到了两个查找函数的工具,在开头都有介绍,所以有需要查找函数的需求完全可以利用起来。
老规矩,封面图:
