1.爬虫概述
爬虫概述
学习目标:
- 了解 爬虫的概念
- 了解 爬虫的作用
- 了解 爬虫的分类
- 掌握 爬虫的流程(原理)
1.爬虫的概念
模拟浏览器,发送请求,获取响应
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端(主要指浏览器)发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
- 原则上,只要是客户端(浏览器)能做的事情,爬虫都能够做
- 爬虫也只能获取客户端(浏览器)所展示出来的数据
1.1.举例说明(百度–搜索引擎爬虫–根据访问权重排序结果)

当我们去百度一个词条的时候,百度这个搜索引擎的爬虫机制,会在互联网中,根据自己的算法收录符合词条的结果,反馈给你,当然,这个结果,会根据百度自身的用户访问统计----(这种统计我们称为访问权重)----进行排序。
所以,我们在研究爬虫的时候,不仅要了解爬虫如何实现,还需要知道一些常见爬虫的算法,如果有必要,我们还需要自己去制定相应的算法,在此,我们仅需要对爬虫的概念有一个基本的了解。
2.爬虫的作用(领域)
思考:如今,人工智能,大数据离我们越来越近,很多公司在开展相关的业务但是人工智能和大数据中有一个东西非常重要,那就是数据,但是数据从哪里来呢?

这是百度的百度指数的一个截图,它把用户在百度上的搜索关键词做了一个统计,然后根据统计结果得出一个流行趋势,之后进行了简单的展示。
像微博上的热搜,就是这么一个原理,类似的指数网站还有很多,比如阿里指数,360指数等等,而这些网站有非常大的用户量,他们能够获取自己用户的数据进行统计和分析
那么,对于一些中小型的公司,没有如此大的用户量的时候,他们该怎么办呢?
2.1.数据来源
1.去第三方的公司购买数据(比如:企查查)
2.去免费的数据网站下载数据(比如:国家统计局)
3.通过爬虫爬取数据
4.人工收集数据(比如:问卷调查)
在上面的数据来源中,人工的方式费时费力,效率低下,免费的数据网站上面的数据质量不佳,很多第三方的数据公司他们的数据往往也是爬虫获取的,所以获取数据最有效的途径就是通过爬虫爬取
# 作用领域
1. 数据采集
1. 抓取微博评论(机器学习舆情监控)
2. 抓取招聘网站的招聘信息(数据分析、挖掘)
3. 新浪滚动新闻
4. 百度新闻网站
2. 软件测试
1. 爬虫之自动化测试
2. 虫师
3. 12306抢票
4. 网站上的投票
1. 投票网
5. 网络安全
1. 短信轰炸
1. 注册页面1
2. 注册页面2
3. 注册页面3
2. web漏洞扫描
- 人脸识别:您做人工智能是需要大数据的,举个例子您想做一个自动识别人脸的人工智能机器。您首先需要根据人脸生物特征建立AI模型,然后需要几千万或者几十亿张人脸图片进行不断的训练这个模型,最后才得到精准的人脸识别AI。几十亿的人脸图片数据哪里来呢? 公安局给你?不可能的!一张张去拍照?更不现实啦! 那就是通过网络爬虫技术建立人脸图像库,比如我们可以通过爬虫技术对facebook、qq头像、微信头像等进行爬取,来实现建立十几亿的人脸图像库。
- 市场分析:电商分析、商圈分析、一二级市场分析等
- 市场监控:电商、新闻、房源监控等
- 商机发现:招投标情报发现、客户资料发掘、企业客户发现等
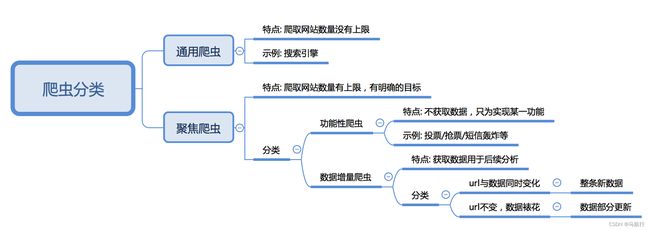
3.爬虫的分类
根据被爬取网站的数量不同,可以分为:
- 通用爬虫,如 搜索引擎
- 聚焦爬虫,如12306抢票,或专门抓取某一个(某一类)网站数据
根据是否以获取数据为目的,可以分为:
- 功能性爬虫,给你喜欢的明星投票、点赞
- 数据增量爬虫,比如招聘信息
根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
- 基于url地址变化、内容也随之变化的数据增量爬虫
- url地址不变、内容变化的数据增量爬虫
4.爬虫的流程(原理)
如图所示

#原理 #开发流程
1. 获取一个url ---->1.准备数据(请求的地址,headers,请求参数,用户输入等等)
2. 向url发送请求,并获取响应(需要http协议) ---->2.发送请求,获取响应
3. 如果从响应中提取url,则继续发送请求获取响应 ---->3.解析响应,数据提取(url--继续请求,数据--执行第4步)
4. 如果从响应中提取数据,则将数据进行保存 ---->4.保存数据
http协议复习
学习目标:
- 掌握 http以及https的概念和默认端口
- 掌握 url地址的构成
- 掌握 查看网络请求(请求头和响应头)
- 了解 常见的响应状态码
- 理解 浏览器和爬虫爬取的区别
- 了解 爬虫协议
1. http以及https的概念和区别
HTTPS比HTTP更安全,但是性能更低
- HTTP:超文本传输协议,默认端口号是80
- 超文本:是指超过文本,不仅限于文本;还包括图片、音频、视频等文件
- 传输协议:是指使用共用约定的固定格式来传递转换成字符串的超文本内容
- HTTPS:HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协,默认端口号:443
- SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
- 可以打开浏览器访问一个url,右键检查,点击net work,点选一个url,查看http协议的形式
2.网址的构成
地址:https://www.baidu.com/s?ie=UTF-8&wd=python%E7%88%AC%E8%99%AB
协议部分:https://
域名部分:www.baidu.com
路径资源部分:/s
参数部分:?ie=UTF-8&wd=python%E7%88%AC%E8%99%AB
3.查看网络请求(请求头和响应头)
以chrome浏览器为例,在网页上点击鼠标右键,检查(或者直接F12),选择network,刷新页面,选择ALL下面的第一个链接,这样就可以看到网页的各种请求信息。


请求头(Request Headers)信息详解: 请求头重点信息:Cookie,User-Agent,Referer
Accept: text/html,image/*(浏览器可以接收的类型)
Accept-Charset: ISO-8859-1(浏览器可以接收的编码类型)
Accept-Encoding: gzip,compress(浏览器可以接收压缩编码类型)
Accept-Language: en-us,zh-cn(浏览器可以接收的语言和国家类型)
Host: www.it315.org:80(浏览器请求的主机和端口)
If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT(某个页面缓存时间)
Referer: http://www.it315.org/index.jsp(请求来自于哪个页面)
User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)(浏览器相关信息)
Cookie:(浏览器暂存服务器发送的信息,个人用户心信息)
Connection: close(1.0)/Keep-Alive(1.1)(HTTP请求的版本的特点)
Date: Tue, 11 Jul 2000 18:23:51 GMT(请求网站的时间)
1234567891011
响应头(Response Headers)信息详解:
Location: http://www.it315.org/index.jsp(控制浏览器显示哪个页面)
Server:apache tomcat(服务器的类型)
Content-Encoding: gzip(服务器发送的压缩编码方式)
Content-Length: 80(服务器发送显示的字节码长度)
Content-Language: zh-cn(服务器发送内容的语言和国家名)
Content-Type: image/jpeg; charset=UTF-8(服务器发送内容的类型和编码类型)
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(服务器最后一次修改的时间)
Refresh: 1;url=http://www.it315.org(控制浏览器1秒钟后转发URL所指向的页面)
Content-Disposition: attachment; filename=aaa.jpg(服务器控制浏览器发下载方式打开文件)
Transfer-Encoding: chunked(服务器分块传递数据到客户端)
Set-Cookie:SS=Q0=5Lb_nQ; path=/search(服务器发送Cookie相关的信息)
Expires: -1(服务器控制浏览器不要缓存网页,默认是缓存)
Cache-Control: no-cache(服务器控制浏览器不要缓存网页)
Pragma: no-cache(服务器控制浏览器不要缓存网页)
Connection: close/Keep-Alive(HTTP请求的版本的特点)
Date: Tue, 11 Jul 2000 18:23:51 GMT(响应网站的时间)
4. 常见的响应状态码
100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)
我们在学习web知识的时候就已经学过了状态码的相关知识,我们知道这是服务器给我的相关反馈,我们在学习的时候就被教育说应该将真实情况反馈给客户端,但是在爬虫中,可能该站点的开发人员或者运维人员为了阻止数据被爬虫轻易获取,可能在状态码上做手脚,也就是说返回的状态码并不一定就是真实情况,比如:服务器已经识别出你是爬虫,但是为了让你疏忽大意,所以照样返回状态码200,但是响应体重并没有数据。
所有的状态码都不可信,一切以是否从抓包得到的响应中获取到数据为准
5. 浏览器的运行过程
在回顾完http协议后,我们来了解以下浏览器发送http请求的过程
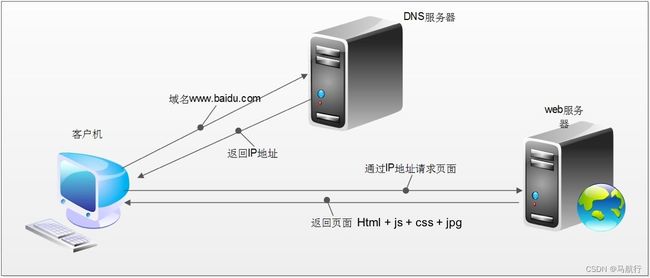
浏览器的请求过程:
浏览器获取的内容(elements的内容)包含:url地址对应的响应+js+css+jpg
爬虫会获取:url地址对应的响应
爬虫获取的内容和elements内容不一样,进行数据提取的时候,需要根据url地址对应的响应为准
爬虫协议(了解)
robots协议:网站通过robots协议,告诉我们搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是道德层面上的约束。
chrome浏览器抓包说明
学习目标
掌握chrome在爬虫中的使用
1.新建无痕窗口
#1.使用隐身窗口,首次打开网站,不会带上cookie,能够观察页面的获取情况,包括对方服务器如何设置cookie在本地
#2.无痕模式下,如果一个地址能够访问,说明该地址的代码请求头中,只需要一个user-agent即可,可观察headers中需要的键值对

2.Chrome中network的更多功能
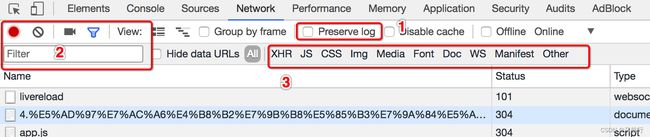
Preserve log
默认情况下,页面发生跳转之后,之前的请求url地址等信息都会消失,勾选perserve log后之前的请求都会被保留
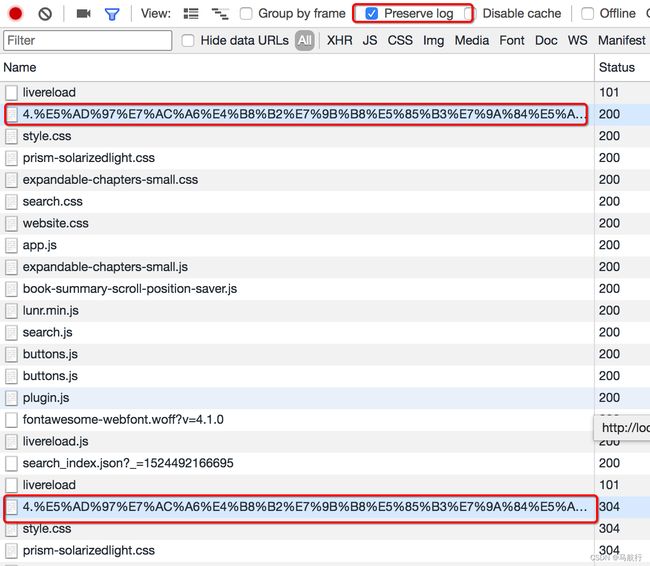
filter过滤
在url地址很多的时候,可以在filter中输入部分url地址,对所有的url地址起到一定的过滤效果,具体位置在上面第二幅图中的2的位置
观察特定种类的请求

在上面第二幅图中的3的位置,有很多选项,默认是选择的all,即会观察到所有种类的请求
很多时候处于自己的目的可以选择all右边的其他选项,比如常见的选项:
- XHR:大部分情况表示ajax请求
- JS:js请求
- CSS:css请求
但是很多时候我们并不能保证我们需要的请求是什么类型,特别是我们不清楚一个请求是否为ajax请求的时候,直接选择all,从前往后观察即可,其中js,css,图片等不去观察即可
不要被浏览器中的一堆请求吓到了,这些请求中除了js,css,图片的请求外,其他的请求并没有多少个
3 寻找登录接口
回顾之前人人网的爬虫我们找到了一个登陆接口,那么这个接口从哪里找到的呢?
http://www.renren.com
3.1 寻找action对的url地址
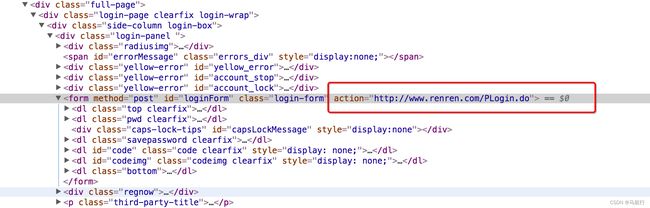
可以发现,这个地址就是在登录的form表单中action对应的url地址,回顾前端的知识点,可以发现就是进行表单提交的地址,对应的,提交的数据,仅仅需要:用户名的input标签中,name的值作为键,用户名作为值,密码的input标签中,name的值作为键,密码作为值即可
思考:
如果action对应的没有url地址的时候可以怎么做?
3.2 通过抓包寻找登录的url地址

通过抓包可以发现,在这个url地址和请求体中均有参数,比如uniqueTimestamp和rkey以及加密之后的password
这个时候我们可以观察手机版的登录接口,是否也是一样的
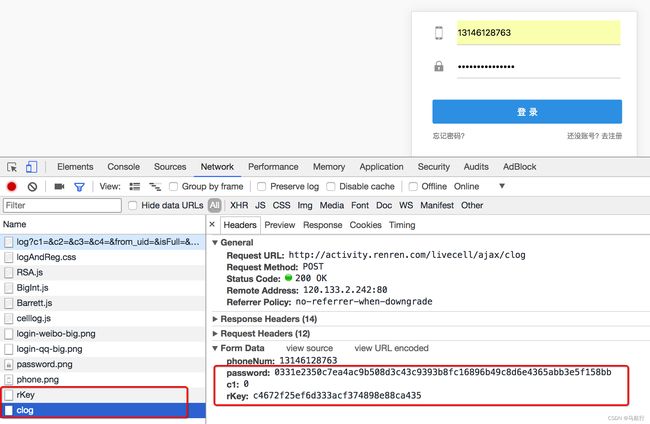
可以发现在手机版中,依然有参数,但是参数的个数少一些,这个时候,我们可以使用手机版作为参考