批量归一化(PyTorch)
文章目录
-
- 批量归一化
-
- 实现原理
- 批量归一化层
- 批量归一化在做什么?
- 总结
- 从零实现
-
- 创建一个正确的`BatchNorm`图层
- 使用批量规范化层的 LeNet
- 简明实现
- QA
批量归一化
- 损失出现在最后,后面的层训练较快
- 数据在最底部
- 底部的层训练较慢
- 底部层一变化,所有都得跟这变
- 最后的那些层需要重新学习多次
- 导致收敛变慢
- 我们可以在学习底部层的时候避免变化顶部层吗?
这里变化指的是不同 batch 的分布变化,而不是指底层参数变化导致顶层参数变化
实现原理
- 固定小批量里面的均值和方差
μ B = 1 ∣ B ∣ ∑ i ∈ B x i a n d σ B 2 = 1 ∣ B ∣ ∑ i ∈ B ( x i − μ B ) 2 + ϵ \mu_B = {1 \over |B|}\sum_{i \in B}x_i\;and\;\sigma_B^2={1 \over |B|}\sum_{i \in B}(x_i-\mu_B)^2+\epsilon μB=∣B∣1i∈B∑xiandσB2=∣B∣1i∈B∑(xi−μB)2+ϵ
然后再做额外的调整(可学习的参数)
x i + 1 = γ x i − μ B σ B + β x_{i+1}=\gamma{x_i - \mu_B\over\sigma_B} + \beta xi+1=γσBxi−μB+β
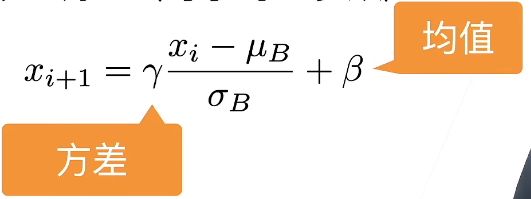
批量归一化层
- 可学习的参数为 γ \gamma γ和 β \beta β
- 作用在
- 全连接层和卷积层输出上,激活函数前
- 全连接层和卷积层输入上
- 对全连接层,作用在特征维
- 对于卷积层,作用在通道维
批量归一化是一个线性的
可以看李宏毅老师的,图文并茂
对全连接层,每一列特征计算一个标量的均值和方差
对卷积层,输入9个像素(3x3), 输出3通道,以通道作为列分量,每个像素都对应3列(输出通道=3),可以列出表格,按列求均值和方差,其实和全连接层一样的。即像素为样本,通道为特征。
特别对于 1 × 1 1\times1 1×1卷积层等价于一个全连接层。
图片本身一个像素就是一个特征。
批量归一化在做什么?
- 最初论文是想用它来减少内部变量转移
- 后续有论文指出它可能就是通过在每个小批量里加入噪音来控制模型复杂度

随机是因为两个变量在mini-batch上计算出来的,这个mini-batch的选取是一个随机的结果
- 因此没必要跟丢弃法混合使用
总结
- 批量归一化固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 可以加速收敛速度,但一般不改变模型精度
- 为了防止不同的小批量,在层数过多时,出现分布剧烈变化,导致收敛速度下降,所以要用BATCH norm。注意是不同的小批量。
- 学习率太大,上面的东西梯度比较大,就炸掉了
- 学习率太小,下面层梯度太小,根本就算不动
从零实现
import torch
from torch import nn
from d2l import torch as d2l
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
# 4D 批量大小 通道数 高 宽 输出为 1×n×1×1
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
输入X,输出Y
gamma,beta可以学的
moving_mean,moving_var 整个数据集上的均值和方差
eps 为了防止出零的一个东西
momentum 同时更新moving_mean和moving_var的东西
moving_mean,moving_var的更新很像低通滤波
创建一个正确的BatchNorm图层
我们现在可以创建一个正确的BatchNorm层。 这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新。 此外,我们的层将保存均值和方差的移动平均值,以便在模型预测期间随后使用。
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
往网络里增加自己的参数 self.gamma = nn.Parameter(torch.ones(shape)) self.beta = nn.Parameter(torch.zeros(shape))
使用批量规范化层的 LeNet
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.Linear(84, 10))
和以前一样,我们将在Fashion-MNIST数据集上训练网络。 这个代码与我们第一次训练LeNet( 6.6节)时几乎完全相同,主要区别在于学习率大得多。
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
让我们来看看从第一个批量规范化层中学到的拉伸参数gamma和偏移参数beta。
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))

简明实现
除了使用我们刚刚定义的BatchNorm,我们也可以直接使用深度学习框架中定义的BatchNorm。 该代码看起来几乎与我们上面的代码相同。
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
注意pytorch的BatchNorm的momentum默认为0.1,而不是0.9
下面,我们使用相同超参数来训练模型。 请注意,通常高级API变体运行速度快得多,因为它的代码已编译为C++或CUDA,而我们的自定义代码由Python实现。
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
QA
-
normalization 和 BatchNorm 的区别?
本质上没区别,是一个思路。模型稳定,收敛就不会变慢。
normalization 选取比较好的初始化,在初试的时候比较稳定,不能保证之后。
BatchNormalization 在训练中对每个层一直做这个操作,核心是为了让数值更加稳定。 -
批量归一化和权重衰减的作用类似?
权重衰退是每次更新的时候权重除了一个小值。
批量归一化对权重倒是没有太大影响。 -
BN 层是不是一般用于深层网络,浅层 MLP 加上 BN 效果好像不好
是的 -
assert len(X.shape) in (2, 4) 这个是什么意思?
断言语句,判断X.shape 是不是在列表(2,4)当中 -
这个 BN 只考虑了两种输入情况怎么做?
正常使用BN的时候,只要高复feature的维度是几。
默认feature_dimension=1,别的全部算均值。 -
BN 是做了线性变换,和加一个线性层有什么区别?
线性层不一定会学到我们所需要的东西,如果不做,数值可能不稳定,到不了好的值域里。 -
为啥加了 batch norm 收敛时间变短
梯度值会变大一点,导致我们可以使用更大的学习率,对权重的更新会变快。 -
PyTorch 里还有一个 layernorm,请问和BN的异同?
xx normalization 太多了,其实本质没有太大区别
batchnormlization 是在样本维度对 features 做normlization
layernorm 样本里面的features 里面做normlization -
batch size 是把显存占满好?还是利用率 gpu-util 100%就可以了?还是需要同时达到100%?
增加batch_size到一定程度之后,每秒钟处理数就不会太大变化。