Hive同步数据到ES
第一步:下载需要的jar包,必须的是es-hadoop的包
elasticsearch-hadoop-5.5.1.jar 下载地址:http://download.elastic.co/hadoop/
到官网下载与ES一致的版本,比如ES版本是5.5.1,则下载elasticsearch-hadoop-5.5.1.zip
第二步:如下是放到hadoop根目录的jars目录下
[hadoop@master lib]$ hadoop fs -put elasticsearch-hadoop-5.5.1.jar /jars/第三步:在hive中添加jar包,
ADD JAR hdfs://nmcluster/user/root/test/es_hadoop/elasticsearch-hadoop-hive-7.8.0.jar;
第四步:hive中建立es外部表
CREATE EXTERNAL TABLE hive_to_es_test (
user string
)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES(
'es.nodes' = 'es地址', --serverIP:port
'es.index.auto.create' = 'true',
'es.resource' = '索引/类型r','es.mapping.id' = 'use_year_code',
--'es.resource'='index/type',
'es.write.operation'='upsert'--如果这里是upsert的话,上边的id一定要指定,否则可以不用设置
'es.mapping.id' = 'uuid'
);es.nodes表示es的节点,多个用“,”分开;
es.index.auto.create表示如果索引不存在自动创建;
es.resource表示指定的索引和类型;
es.mapping.id表示es的_id对应的字段;
es.mapping.names表示其他字段的对应(可以不写,插入时按顺序依次对应即可);
es.write.operation表示如果id重复就更新数据;
第五步:hive中的需要同步的数据表,准备好,如果不写names配置项,需要和es中的字段顺序对应
CREATE TABLE `emptoes2`(
`empno` int COMMENT 'from deserializer',
`name` string COMMENT 'from deserializer',
`job` string COMMENT 'from deserializer',
`mgr` int COMMENT 'from deserializer',
`hiredate` string COMMENT 'from deserializer',
`sal` double COMMENT 'from deserializer',
`comm` double COMMENT 'from deserializer',
`deptid` int COMMENT 'from deserializer')
ROW FORMAT SERDE
'org.elasticsearch.hadoop.hive.EsSerDe'
STORED BY
'org.elasticsearch.hadoop.hive.EsStorageHandler'
WITH SERDEPROPERTIES (
'serialization.format'='1')
LOCATION
'hdfs://master:9000/user/hive/warehouse/bond_edu.db/emptoes2'
TBLPROPERTIES (
'es.index.auto.create'='TRUE',
'es.nodes'='10.0.1.118',
'es.nodes.wan.only'='TRUE',
'es.port'='9200',
'es.resource'='bond/edu',
'last_modified_by'='hadoop',
'last_modified_time'='1592642827',
'numFiles'='0',
'numRows'='0',
'rawDataSize'='0',
'totalSize'='0',
'transient_lastDdlTime'='1592642827') 第六步:推送数据
INSERT OVERWRITE TABLE hive_to_es_test SELECT * FROM test_app.to_es;注意事项:
数据类型要把持一致
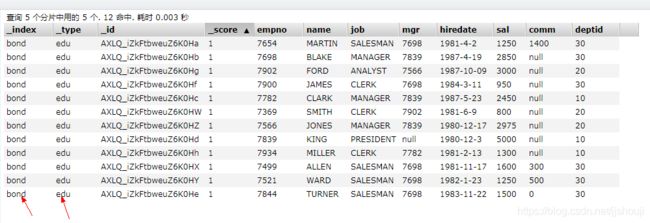
第六步:查看ES中索引
查看hive表中映射的索引:【'es.resource'='bond/edu'】,下图是elasticsearch-head中查看到的数据:
总结
通常使用ES, 首当其冲的问题就是: 如何快速将海量数据导入ES? 由于ES的数据需要建立倒排索引,所以导入数据到ES的瓶颈往往在ES这里。
总结有3点:
1、根据应用场景创建mapping, 去除不必要的字段,如_all, _source;
这里是从应用场景下手,以避免存储不必要的信息来提升索引数据的性能。
2、修改es/lucene默认的设置,比如
refresh_interval,
index.number_of_replicas,
index.merge.scheduler.max_thread_count,
index.translog.interval,
indices.memory.index_buffer_size
index.index_concurrency
等参数。 这里是从集群的角度进行调优, 通常用于大批量导入数据到ES。
3、如果前面两种还是没能解决问题,那就需要对集群进行横向扩展了,比如增加集群的分片数量。
集群大了后,各个结点的功能就需要单一化,专注化了。
比如节点只承担数据相关的任务。
node.master: false
node.data: true
node.ingest: false
bulk api的批量值需要实验,找到最佳参数。建议bulk的大小在5M~10M.
使用SSD硬盘。索引数据时,副本数设置为0。
-----------------------------------