吴恩达《机器学习》课后测试Ex1:线性回归(详细Python代码注解)
基于吴恩达《机器学习》课程
参考黄海广的笔记
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
计算代价函数
代价函数: J ( θ ) = J ( θ 0 , θ 1 . . . θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J (\theta)=J\left( {\theta_{0}},{\theta_{1}}...{\theta_{n}} \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}} J(θ)=J(θ0,θ1...θn)=2m1i=1∑m(hθ(x(i))−y(i))2
其中: h θ ( x ) = θ T X = X T θ = [ x 0 ( 1 ) . . . x n ( 1 ) . . . . . . . . . x 0 ( m ) . . . x n ( m ) ] [ θ 0 . . . θ n ] = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_{\theta}\left( x \right)=\theta^{T}X=X^T{\theta}=\left[ \begin{array} {ccc} {x}_{0}^{\left( 1 \right)} & ... & {x}_{n}^{\left( 1 \right)}\\ ... & ... & ...\\ {x}_{0}^{\left( m \right)} & ... & {x}_{n}^{\left( m \right)}\\ \end{array} \right]\begin{bmatrix} {\theta_{0}} \\...\\{\theta_{n}} \end{bmatrix}={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θTX=XTθ=⎣⎢⎡x0(1)...x0(m).........xn(1)...xn(m)⎦⎥⎤⎣⎡θ0...θn⎦⎤=θ0+θ1x1+θ2x2+...+θnxn
代码如下:
def computeCost (X,y,theta):
inner=np.power((X*theta.T)-y,2)
# theta.T就是矩阵theta的转置矩阵
# np.power(A,B) 对A中的每个元素求B次方
# np.sum对矩阵中中所有元素求和
return np.sum(inner)/(2*len(X))
输入的X为 m ∗ n m*n m∗n矩阵,y为 n n n维列向量、theta为 n n n维行向量,返回值即为 J ( θ ) J (\theta) J(θ)
m m m代表训练集中实例的数量, n n n代表一个实例的维数。
批量梯度下降
θ j : = θ j − α ∂ ∂ θ j J ( θ ) : = θ j − α 1 2 m ∂ ∂ θ j ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 {\theta_{j}}:={\theta_{j}}-\alpha \frac{\partial }{\partial {\theta_{j}}}J ( \theta) :={\theta_{j}}-\alpha \frac{1}{2m}\frac{\partial }{\partial {\theta_{j}}}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}} θj:=θj−α∂θj∂J(θ):=θj−α2m1∂θj∂i=1∑m(hθ(x(i))−y(i))2
# 批量梯度下降
def gradientDescent(X, y, theta, alpha, iters): # alpha是学习率,iters为迭代次数
temp = np.matrix(np.zeros(theta.shape))
# np.zeros(theta.shape)=[0.,0.]返回的是数组,然后将temp变为矩阵[0.,0.]
parameters = int(theta.ravel().shape[1])
# theta.ravel():将多维数组theta降为一维,.shape[1]是统计这个一维数组有多少个元
# parameters表示参数
cost = np.zeros(iters) # 初始化代价函数值为0数组,元素个数为迭代次数
for i in range(iters): # 循环iters次
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:, j])
# 将误差与训练数据相乘,np.multiply将数组或矩阵对应位置点乘。
# term为偏导数,参考笔记反向传播详解
temp[0, j] = theta[0, j] - ((alpha / len(X)) * np.sum(term)) # 更新theta
theta = temp # 更新theta
cost[i] = computeCost(X, y, theta)
# 把每一次迭代的代价函数都保存了,数组最后一位就是最后的代价函数
return theta, cost
这里的error就是 δ = a − y = ∂ C ∂ z \delta=a-y=\frac{\partial C}{\partial {z}} δ=a−y=∂z∂C,X[:, j]则是 ∂ z ∂ w = a \frac{\partial z}{\partial {w}}=a ∂w∂z=a,所以term为 ∂ C ∂ w = ∂ z ∂ w ∂ C ∂ z \frac{\partial C}{\partial {w}}=\frac{\partial z}{\partial {w}}\frac{\partial C}{\partial {z}} ∂w∂C=∂w∂z∂z∂C,即为代价函数偏导数。
正规方程
只适用于线性模型,不适合逻辑回归模型等其他模型。通常来说当特征数量n小于10000 时还是可以接受的。
θ = ( X T X ) − 1 X T y \theta ={{\left( {X^T}X \right)}^{-1}}{X^{T}}y θ=(XTX)−1XTy
def normalEqn(X, y):
theta = np.linalg.inv(X.T @ X) @ X.T @ y # np.linalg.inv 矩阵求逆
# X.T@X等价于X.T.dot(X) .dot()表示点积,也就是矩阵相乘的意思
return theta
单变量线性回归
根据城市人口数量,预测开小吃店的利润 。
数据在ex1data1.txt里,第一列是城市人口数量,第二列是该城市小吃店利润。
调用了上述两个函数。
def ex1_2():
path = 'ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
# header = None表示没有表头
# pd.read_csv的作用是将csv文件读入并转化为数据框形式,有非常多的参数,用到时可查阅文档。
# print(data.head(10)) # 括号内可填写要读取的前n行,如果不填,默认为n=5
# print(data.info()) # 查看索引、数据类型和内存信息
# 通过绘制散点图来观察原始数据
data.plot(kind='scatter', x='Population', y='Profit', figsize=(12, 8))
# scatter表示散点图,figsize设置图形大小
# plt.show()
# 数据前面已经读取完毕,让我们在数据中添加了一列,以便我们可以使用向量化的解决方案来计算代价和梯度。
data.insert(0, 'ONE', 1) # 在第0列插入表头为“ONE”的列,数值为1
# 初始化X和y
cols = data.shape[1] # 获取表格data的列数
X = data.iloc[:, 0:cols-1] # 除最后一列外,取其他列的所有行,即X为ONE和人口组成的列表
y = data.iloc[:, cols - 1:cols] # y是data最后一列
# 代价函数是应该是numpy矩阵,所以我们需要转换X和Y,然后才能使用它们。我们还需要初始化theta。
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix(np.array([0, 0]))
# 看下维度
print(X.shape, theta.shape, y.shape, theta)
# 计算代价函数 (theta初始值为0)
print(computeCost(X, y, theta))
# 初始化一些附加变量,比如学习速率α和要执行的迭代次数。
alpha = 0.01
iters = 3000
# 运行梯度下降算法
g, cost = gradientDescent(X, y, theta, alpha, iters) # 令g和cost分别等于函数的两个返回值
print(g, cost)
# 预测35000和70000城市规模的小吃摊利润
predict1 = [1, 3.5] * g.T
print("predict1:", predict1)
predict2 = [1, 7] * g.T
print("predict2:", predict2)
# 数据可视化,绘制线性模型以及数据。
x = np.linspace(data.Population.min(), data.Population.max(), 100)
# 以人口最小值为起点,最大值为终点,创建元素个数为100的等差数列
f = g[0, 0] + (g[0, 1] * x) # f是假设函数H=x_0+x_1*theta
fig, ax = plt.subplots(figsize=(12, 8)) # 建立一个fig对象,建立一个axis对象
# 等价于 fig = plt.figure() ax = fig.add_subplot()
# figsize=(a,b):figsize 设置图形的大小,b为图形的宽,b为图形的高,单位为英寸
ax.plot(x, f, 'r', label='Prediction') # 设置点的横坐标,纵坐标,用红色线,并且设置Prediction为关键字参数
ax.scatter(data.Population, data.Profit, label='Traning Data') # 以人口为横坐标,利润为纵坐标并且设置Traning Data为关键字参数
ax.legend(loc=2) # legend为显示图例函数,loc为设置图例显示的位置,loc=2即在左上方
ax.set_xlabel('Population') # 设置x轴变量
ax.set_ylabel('Profit') # 设置x轴变量
ax.set_title('Predicted Profit vs. Population Size') # 设置表头
plt.show()
# 代价函数递减可视化
fig, ax = plt.subplots(figsize=(12, 8)) # 以其他关键字参数**fig_kw来创建图
ax.plot(np.arange(iters), cost, 'b') # 作图:以迭代次数为x,代价函数值为y,线条颜色为蓝色
ax.set_xlabel('Iterations') # 设置x轴变量
ax.set_ylabel('Cost') # 设置y轴变量
ax.set_title('Error vs. Training Epoch') # 设置表头
plt.show()
对于单变量线性回归: h θ ( x ) = θ 0 + θ 1 x 1 h_\theta \left( x \right)=\theta_{0} + \theta_{1}x_1 hθ(x)=θ0+θ1x1
在第0列插入表头为ONE的列,数值为1,即为使 x 0 = 1 x_0=1 x0=1
倒数第二步画图结果为:

多变量线性回归
ex1data2.txt里的数据,第一列是房屋大小,第二列是卧室数量,第三列是房屋售价
根据已有数据,建立模型,预测房屋的售价。
def ex1_3():
data2 = pd.read_csv('ex1data2.txt', names=['square', 'bedrooms', 'price']) # 默认,为分隔符
print(data2.head())
# 统一量级会让梯度下降收敛的更快。进行特征缩放=(−)/,un是平均值,sn 是标准差。
data2 = (data2 - data2.mean()) / data2.std()
print(data2.head())
# 重复第1部分的预处理步骤,对新数据集运行线性回归程序。
data2.insert(0, 'Ones', 1) # 在第0列插入表头为“ONE”的列,数值为1
cols = data2.shape[1] # 获取表格df的列数
X2 = data2.iloc[:, 0:cols - 1] # 除最后一列外,取其他列的所有行,即X2为O,面积,卧室数组成的列表
y2 = data2.iloc[:, cols - 1:cols] # 取最后一列的所有行,即y2为价格
X2 = np.matrix(X2.values) # 转换为矩阵
y2 = np.matrix(y2.values) # 转换为矩阵
theta2 = np.matrix(np.array([0, 0, 0])) # 初始化theta
# 初始化学习速率α和要执行的迭代次数
alpha = 0.01
iters = 3000
g2, cost2 = gradientDescent(X2, y2, theta2, alpha, iters)
print(g2, cost2)
# 代价函数可视化
fig, ax = plt.subplots(figsize=(12, 8)) # 以其他关键字参数**fig_kw来创建图
ax.plot(np.arange(iters), cost2, 'r') # 作图:以迭代次数为x,代价函数值为y,线条颜色为红色
ax.set_xlabel('Iterations') # 设置x轴变量
ax.set_ylabel('Cost') # 设置y轴变量
ax.set_title('Error vs. Training Epoch') # 设置表头
plt.show()
或者用正规方程也可以求参数theta
# 用正规方程求theta
final_theta2 = normalEqn(X2, y2)
print(final_theta2)
代价函数-迭代次数图如下:
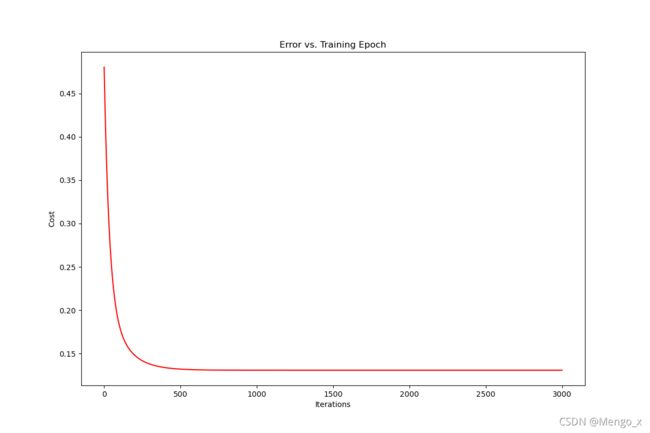
使用高级优化方法
我们也可以使用scikit-learn的线性回归函数,而不是从头开始实现这些算法。 我们将scikit-learn的线性回归算法应用于ex1data1的数据,并看看它的表现。
首先要导入sklearn库:
from sklearn import linear_model # 从sklearn库中引入线性模块
def ex1_4():
path = 'ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
data.insert(0, 'ONE', 1) # 在第0列插入表头为“ONE”的列,数值为1
cols = data.shape[1] # 获取表格data的列数
X = data.iloc[:, 0:cols - 1] # 除最后一列外,取其他列的所有行,即X为ONE和人口组成的列表
y = data.iloc[:, cols - 1:cols] # y是data最后一列
# 代价函数是应该是numpy矩阵,所以我们需要转换X和Y,然后才能使用它们。
X = np.matrix(X.values)
y = np.matrix(y.values)
# 和第一部分一样,得到X,y
model = linear_model.LinearRegression() # 声明对象为线性回归模型
model.fit(X, y) # 拟合X,y
# 画 迭代次数 - 代价函数 图
x = np.array(X[:, 1].A1)
f = model.predict(X).flatten() # 将model.predict(X)中的数据降为一维,并返回源数据的副本
fig, ax = plt.subplots(figsize=(12, 8)) # 以其他关键字参数**fig_kw来创建图
ax.plot(x, f, 'r', label='Prediction') # 设置点的横坐标,纵坐标,用红色线,并且设置Prediction为关键字参数
ax.scatter(data.Population, data.Profit, label='Traning Data') # 以人口为横坐标,利润为纵坐标并且设置Traning Data为关键字参数
ax.legend(loc=2) # legend为显示图例函数,loc为设置图例显示的位置,loc=2即在左上方
ax.set_xlabel('Population') # 设置x轴变量
ax.set_ylabel('Profit') # 设置x轴变量
ax.set_title('Predicted Profit vs. Population Size') # 设置表头
plt.show()
不过model.predict(X)用法这里没太懂。