Flink SQL Kafka写入Hudi详解
1、背景
前面Hudi的专栏已经详细讲解过本地如何构建这套Hudi的运行环境,在此就不在重复了,如果感兴趣想了解的可以去学习下,从0到1搭建数据湖Hudi环境_一个数据小开发的博客-CSDN博客
本次重点是为了能够很好的理解Hudi的两种表COW和MOR,下面将对这两种表操作的详情进行demo操作。
2、实操
2.1、启动Flink SQL Client
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./sql-client.sh embedded -j ../lib/hudi-flink-bundle_2.11-0.10.1.jar shell
2.2、启动Hadoop
2.3、创建KafkaTopic
kafka-topics.sh --create --bootstrap-server 11.238.116.75:9092 --replication-factor 1 --partitions 3 --topic hudi_flink_demo2.4、创建Flink Kafka表和Hudi表
-- 构建kafka source表
CREATE TABLE data_gen (
id STRING,
name STRING,
user_age STRING,
user_other STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'hudi_flink_demo',
'properties.bootstrap.servers' = 'ip:9092',
'properties.group.id' = 'testGroup3',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);2.4.1、COW表
-- 构建COW模式Hudi表
CREATE TABLE hudi_cow_data_gen(
id STRING,
name STRING,
user_age STRING,
user_other STRING,
ts TIMESTAMP(3),
PRIMARY KEY(id) NOT ENFORCED
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://localhost:9000/user/root/hudi/hudi_cow_data_gen',
'table.type' = 'COPY_ON_WRITE',
'write.insert.drop.duplicates' = 'true'
);
-- 启动任务
insert into hudi_cow_data_gen select * from data_gen;
启动成功后,可以在yarn上看到这个任务的启动状态
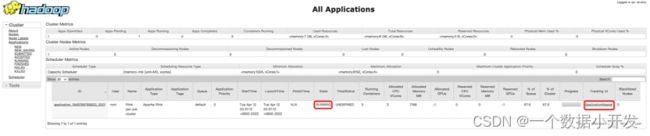
点击上面的“ApplicationMaster”之后可以跳转到相对应的这个任务在Flink之上运行的一个Dashboard页面

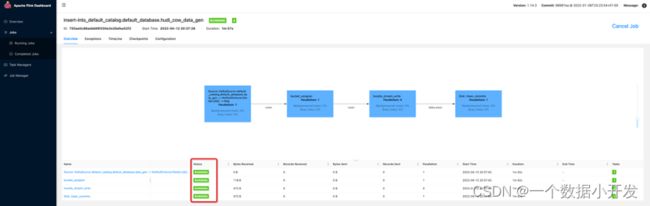
可以看到任务都运行正常,并且在hdfs上看到,数据目录已经创建成功,但是因为还没开始写入数据,所以还没有parquet数据文件产生。
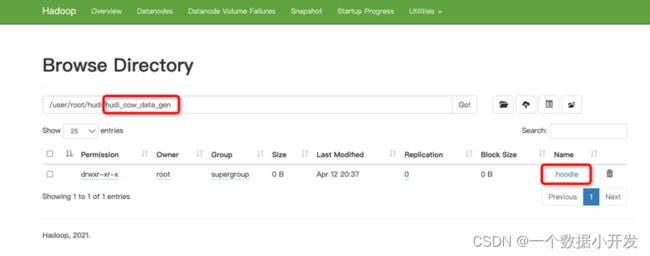
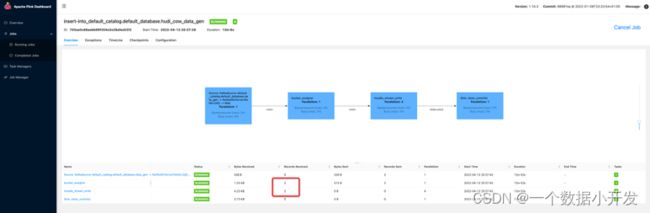
往Kafka发送一条数据之后,可以发现,records received已经有一条数据了

在去看下checkpoint页面
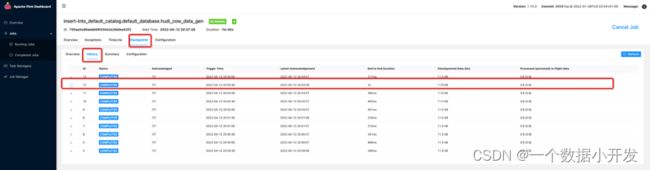 在checkpoint成功之后,发现数据文件已经生成
在checkpoint成功之后,发现数据文件已经生成
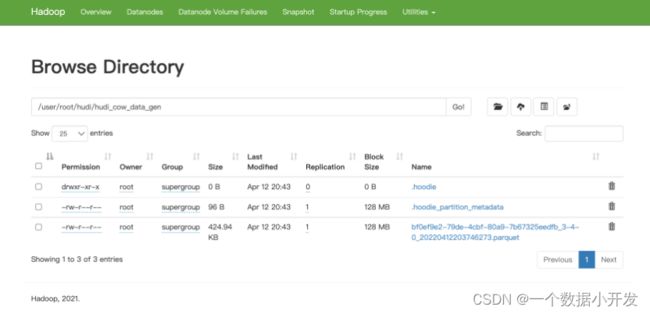 把parquet文件下载下来查看下里面的内容
把parquet文件下载下来查看下里面的内容
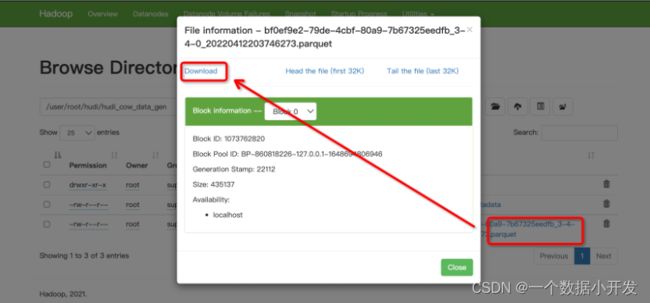
parquet文件读取方式
##查看schema:
java -jar parquet-tools-1.6.0rc3-SNAPSHOT.jar schema -d bf0ef9e2-79de-4cbf-80a9-7b67325eedfb_3-4-0_20220412203746273.parquet | head -n 10
##查看文件内容:
java -jar parquet-tools-1.6.0rc3-SNAPSHOT.jar head -n 100 bf0ef9e2-79de-4cbf-80a9-7b67325eedfb_3-4-0_20220412203746273.parquet此jar包可以在评论区留言后向我获取


发现插入的数据生效了,下面再插入一条数据,并且主键值还是“qwer1”的这条数据,只是改变下其他列的值,观察数据是否会发生变更。
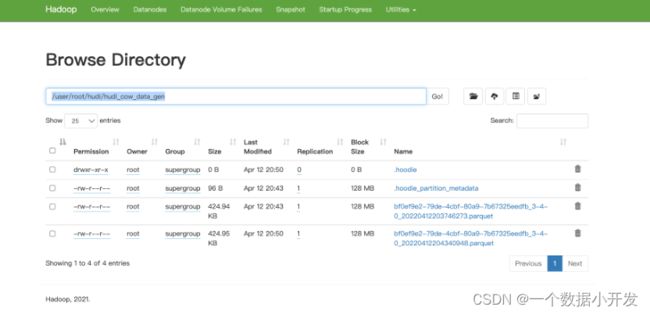
发现hdfs上已经生成了两个parquet文件了,下面换一种方法读取里面的数据,用spark
读取里面的值
2.4.2、Spark读取COW表
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkReadHudi {
public static void main(String[] args) {
SparkConf conf = null;
SparkSession sparkSession = null;
conf = new SparkConf()
.setAppName("SparkHudi")
.set("spark.executor.extraJavaOptions", "-Dlog4j.configuration=file:log4j.properties")
.set("spark.logConf", "true")
.set("spark.debug.maxToStringFields", "1000")
.set("spark.sql.decimalOperations.allowPrecisionLoss", "false")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]");
sparkSession = SparkSession.builder()
.config(conf)
.getOrCreate();
Dataset hudiDataset = sparkSession.read()
.format("hudi")
.load("hdfs://localhost:9000/user/root/hudi/hudi_cow_data_gen")
;
hudiDataset.createOrReplaceTempView("t_flink_hudi_table");
sparkSession.sql("select * from t_flink_hudi_table").show();
}
}
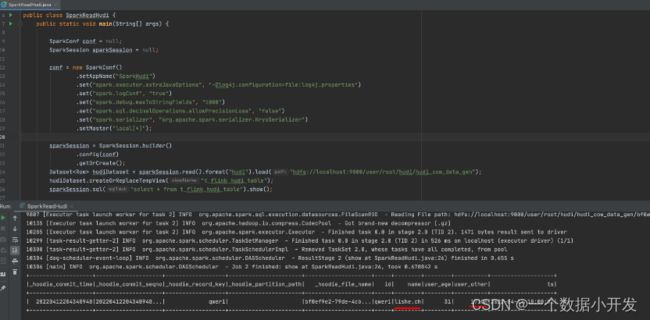 可以对比发现数据发生了变更,证明Hudi 数据更新生效了。
可以对比发现数据发生了变更,证明Hudi 数据更新生效了。
2.4.3、MOR表
delta_commits --指标含义,根据设置的提交次数来合并数据
-- 构建MOR模式的表
CREATE TABLE hudi_mor_data_gen(
id STRING,
name STRING,
user_age STRING,
user_other STRING,
ts TIMESTAMP(3),
PRIMARY KEY(id) NOT ENFORCED
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://localhost:9000/user/root/hudi/hudi_mor_data_gen',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'write.tasks'= '4',
'compaction.tasks'= '4',
'compaction.delta_seconds' = '120',
'compaction.delta_commits' = '1',
'read.streaming.check-interval' = '1'
);
CREATE TABLE hudi_mor_data_gen2(
id STRING,
name STRING,
user_age STRING,
user_other STRING,
ts TIMESTAMP(3),
PRIMARY KEY(id) NOT ENFORCED
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://localhost:9000/user/root/hudi/hudi_mor_data_gen2',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'write.tasks'= '4',
'compaction.tasks'= '4',
'compaction.delta_seconds' = '120',
'compaction.delta_commits' = '3',
'read.streaming.check-interval' = '1'
);第一个表构建的是 delta_commits = 1 ,实际测试发现,当发生一次数据提交的时候,后台就会根据checkpoint去触发一次compaction,符合预期;
第二个表构建的是 delta_commits = 3,实际测试发现,当发生三次数据提交的时候,后台就会根据checkpoint去触发一次compaction,符合预期;
2.4.4、Spark增量模式读取MOR表
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.hudi.DataSourceReadOptions;
public class SparkReadHudi {
public static void main(String[] args) {
SparkConf conf = null;
SparkSession sparkSession = null;
conf = new SparkConf()
.setAppName("SparkHudi")
.set("spark.executor.extraJavaOptions", "-Dlog4j.configuration=file:log4j.properties")
.set("spark.logConf", "true")
.set("spark.debug.maxToStringFields", "1000")
.set("spark.sql.decimalOperations.allowPrecisionLoss", "false")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.setMaster("local[*]");
sparkSession = SparkSession.builder()
.config(conf)
.getOrCreate();
Dataset hudiDataset = sparkSession.read()
.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE().key(), DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL())
// 设置增量读取数据时开始时间
.option(DataSourceReadOptions.BEGIN_INSTANTTIME().key(), "20220413101430946")
.load("hdfs://localhost:9000/user/root/hudi/hudi_mor_data_gen2");
hudiDataset.createOrReplaceTempView("t_flink_hudi_table");
sparkSession.sql("select * from t_flink_hudi_table").show();
}
}
3、本次Spark代码的pom文件
4.0.0 org.example hudi-flink-spark 1.0-SNAPSHOT 3.2.0 3.0.0-M4 3.0.0-M4 3.2.4 3.1.1 3.8.0 2.4 0.15 1.7 3.0.0-M1 0.37.0 1.8 2.6.7 2.6.7.3 2.6.7.1 2.7.4 2.10.0 2.3.0 5.3.4 2.17 1.10.1 5.7.0-M1 5.7.0-M1 1.7.0-M1 3.3.3 1.2.17 2.17.0 1.7.30 2.9.9 3.3.1 org.apache.hive 2.3.1 core 4.1.1 1.6.0 0.16 0.8.0 4.4.1 ${spark2.version} 1.12.0 2.4.4 3.1.2 hudi-spark2 1.8.2 2.11.12 2.12.10 ${scala11.version} 2.11 0.12 3.3.1 3.0.1 file://${project.basedir}/src/test/resources/log4j-surefire.properties 0.12.0 9.4.15.v20190215 3.1.0-incubating 1.2.3 1.9.13 1.4.199 3.1.2 false ${skipTests} ${skipTests} ${skipTests} ${skipTests} ${skipTests} ${skipTests} UTF-8 ${project.basedir} provided compile org.apache.hudi.spark. provided -Xmx2g 0.8.5 compile org.apache.hudi. true 2.7.1 4.7 1.12.22 3.17.3 3.1.0 1.1.0 8000 http://localhost:${dynamodb-local.port} 1.2.72 org.apache.spark spark-core_${scala.binary.version} ${spark.version} provided org.apache.spark spark-sql_${scala.binary.version} ${spark.version} provided org.apache.spark spark-hive_${scala.binary.version} ${spark.version} provided org.apache.hudi hudi-spark-bundle_2.11 0.10.1 org.apache.spark spark-avro_2.11 2.4.4 org.apache.spark spark-mllib_2.11 ${spark.version} org.apache.hudi hudi-common 0.10.1
