torch从零开始搭建deeplabv3+训练自己的数据集!
目录
一、制作自己数据集
1.1 torch数据加载原理
1.2 地理信息科学与深度学习的结合
1.3代码实现
1.4分批次加载数据集
二、训练网络
2.1参数选择
2.2训练过成可视化
三、执行预测
3.1滑动窗口预测
3.2滑动窗口主要代码
因为很多人会问代码能开源吗,在哪里,因此开头就先把代码地址放出来。
项目代码地址:点击获取地址
一、制作自己数据集
1.1 torch数据加载原理
torch数据输入需要转换为张量,因此需要将读取的图片数据和标签转换为tensor,重写自己的读取数据类,只需要提供图片和标签的文件夹路径,即可实现数据的读取,但是数据读取完毕后因为计算能力有限,需要使用torch框架提供的
Data.DataLoader函数实现分批次输入。
1.2 地理信息科学与深度学习的结合
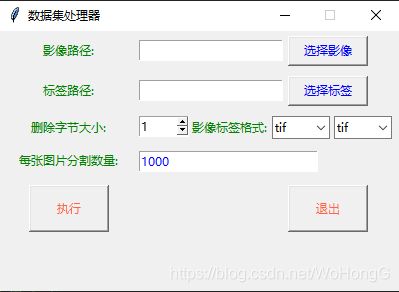
利用GIS专业技术,可以将空间地理方面的所有信息,数字化,转换为数字信息数据,而深度学习技术则可以提取这些数据中我们所关注的信息。因此这两种技术相互结合,就可以代替人工,解决人工矢量化,提取遥感影像特征等一系列问题,同时深度学习需要大量的标签数据,而GIS技术矢量化精度要求较高,通过转换正好可以用于神经网络训练。利用python 中的tk模块编写了可视化数据集制作脚本。
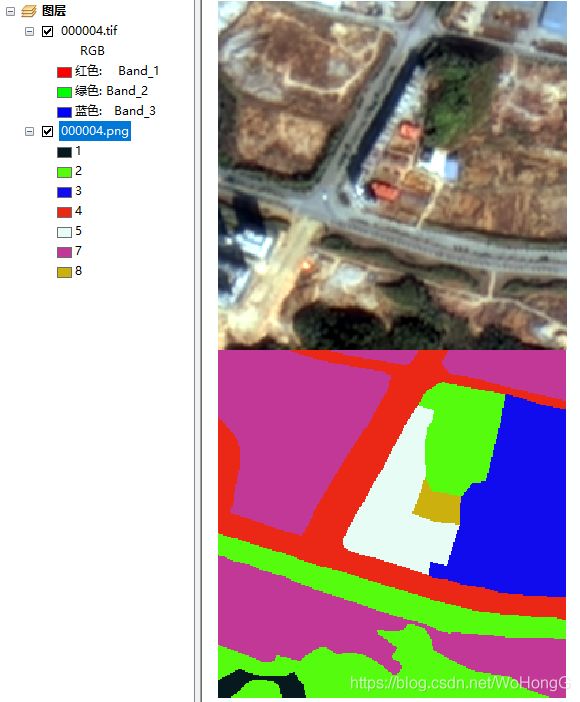
输入图片格式,mask标签不用采取one-hot编码输入网络,需要格式为背景值:对应数值0,类别A:对应数值1,类别B:对应数值2,类别C:对应数值3,如下图所示。
1.3代码实现
代码为项目中data文件。
class MyData(Data.Dataset):
def __init__(self, imagepath, maskpath):
super(MyData, self).__init__()
self.imagepath = imagepath
self.maskpath = maskpath
self.imagelist = glob.glob(os.path.join(imagepath, "*.tif"))
self.masklist = glob.glob(os.path.join(maskpath, "*.png"))
# 归一化
def TransForm(self, image, mask):
image_t = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
[0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
tens_image = image_t(image.astype(np.float32)) # 转化image为tensor
tens_mask = torch.from_numpy(mask)
return tens_image, tens_mask
# 调用对象P[k]就会执行这个方法
def __getitem__(self, index):
oneimg = self.imagelist[index] # 获取路径
onemask = self.masklist[index]
img = skimage.io.imread(oneimg)
if img.shape[-1]>3:
img = ChangeChen(skimage.io.imread(oneimg)) # 读取图片
mask = skimage.io.imread(onemask).astype(np.int64)
return self.TransForm(img, mask)
def __len__(self):
return len(self.imagelist)1.4分批次加载数据集
train_load = Data.DataLoader(
voc_val,
batch_size=batchsize,
shuffle=True)二、训练网络
2.1参数选择
训练网络主要涉及到,优化器,损失函数,批次,学习率,修改41-56行为自己的参数。
images = r'E:\RandomTasks\Dlinknet\dataset\train\images'
mask = r'E:\RandomTasks\Dlinknet\dataset\train\labels'
voc_val = MyData(images,mask)
batchsize = 16#计算批次大小
train_load = Data.DataLoader(
voc_val,
batch_size=batchsize,
shuffle=True)
NAME = 'DinkNet34_class8_xiaomai'#数据模型
modefiles = 'weights/'+NAME+'.th'
write = SummaryWriter('weights')#可视化
loss = nn.NLLLoss()
#loss = nn.CrossEntropyLoss()
solver = MyFrame(DinkNet34, loss, 0.0003)#网络,损失函数,以及学习率
2.2训练过成可视化
主要利用下面两个模块将网络训练过成中的输出,展示出来。
from tensorboardX import SummaryWriter
import torchvision.utils as vutils
write = SummaryWriter('weights')#可视化
for epoch in tqdm.tqdm(range(1, total_epoch + 1)):
train_epoch_loss = 0
for i,(img,mask) in enumerate(train_load):
#总循环次数
allstep=epoch*len(train_load)+i+1
solver.set_input(img, mask)
#网络训练,返回loss和网络输出
train_loss,netout = solver.optimize()
#可视化训练数据
img_x = vutils.make_grid(img,nrow=4,normalize=True)
write.add_image('train_images',img_x,allstep)
#可视化标签
mask_pic=IamColor(mask)
mask_pic = torch.from_numpy(mask_pic)
mask_pic = vutils.make_grid(mask_pic,nrow=4,normalize=True)
write.add_image('label_images',mask_pic,allstep)
#可视化网络输出
pre = torch.argmax(netout.cpu(),1)
img_out = np.zeros(pre.shape + (3,))
for ii in range(num_class):
img_out[pre == ii,:] = COLOR_DICT[ii]#对应上色
pre = img_out / 255
pre = np.transpose(pre,(0,3,1,2))#变成b c h w
pre = torch.from_numpy(pre)
img_out = vutils.make_grid(pre,nrow=4,normalize=True)#必须是tensor
write.add_image('predict_out',img_out,allstep)#必须是三个通道的
#可视化损失函数输出
train_epoch_loss += train_loss#所有的loss和
write.add_scalar('train_loss',train_loss,allstep)
#可视化网络参数直方图感觉影响速度
for name,param in solver.net.named_parameters():
write.add_histogram(name,param.data.cpu().numpy(),allstep)
三、执行预测
3.1滑动窗口预测
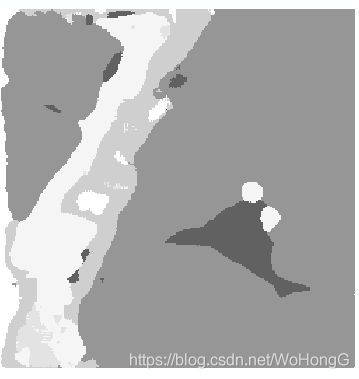
执行预测为了防止出现重叠,采取滑动步长,同时只取中心1/4的方法,下图分别为直接拼接,取中间1/4,和最终应用的方法结果。


3.2滑动窗口主要代码
def make_prediction_img(self,x, target_size, batch_size, predict): # 函数当做变量
"""
滑动窗口预测图像。
每次取target_size大小的图像预测,但只取中间的1/4,这样预测可以避免产生接缝。
"""
# target window是正方形,target_size是边长
quarter_target_size = target_size//4
half_target_size = target_size // 2
pad_width = (
(quarter_target_size, target_size), # 32,128是因为遍历不到最后一个值
(quarter_target_size, target_size), # 32,128
(0,0))#第三个维度扩展维度为0,所以是0,0
# 只在前两维pad
pad_x = np.pad(x, pad_width, 'constant', constant_values=0) # 填充(x.shape[0]+160,x.shape[1]+160)
pad_y = np.zeros(
(pad_x.shape[0], pad_x.shape[1],8),
dtype=np.float32) # 32位浮点型
def update_prediction_center(one_batch):
"""根据预测结果更新原图中的一个小窗口,只取预测结果正中间的1/4的区域"""
wins = [] # 窗口
for row_begin, row_end, col_begin, col_end in one_batch:
win = pad_x[row_begin:row_end, col_begin:col_end, :] # 每次裁剪数组这里引入数据
win = self.Test_read(win)#转换数据,会自动改变数据维度
win = torch.unsqueeze(win,0) # 喂入数据的维度确定了喂入的数据要求是(n, 3,256,256)
wins.append(win)
x_window = np.concatenate(wins, 0) # 一个批次的数据
x_window = torch.from_numpy(x_window)
y_window = predict(x_window) # 预测一个窗格,返回结果需要一个一个批次的取出来
for k in range(len(wins)): # 获取窗口编号
row_begin, row_end, col_begin, col_end = one_batch[k] # 取出来一个索引
if len(y_window.shape)>3:
pred = y_window[k, ...] # 裁剪出来一个数组,取出来一个批次数据5*256*256
if len(y_window.shape)==3:
pred = y_window
pred = np.transpose(pred,(1,2,0))#互换
#直接把结果保存到空矩阵中效果不好
# pad_y[
# row_begin:row_end,col_begin :col_end,:
# ] = pred
# 把预测的结果放到建立的空矩阵中[32:96,32:96]
y_window_center = pred[
quarter_target_size:target_size - quarter_target_size,
quarter_target_size:target_size - quarter_target_size,
:] # 只取预测结果中间区域减去边界32[32:96,32:96]
pad_y[
row_begin + quarter_target_size:row_end - quarter_target_size,
col_begin + quarter_target_size:col_end - quarter_target_size,:
] = y_window_center # 只取4/1
# 每次移动半个窗格
batchs = []
batch = []
for row_begin in range(0, pad_x.shape[0], half_target_size): # 行中每次移动半个[0,x+160,64]
for col_begin in range(0, pad_x.shape[1], half_target_size): # 列中每次移动半个[0,x+160,64]
row_end = row_begin + target_size # 0+128
col_end = col_begin + target_size # 0+128
if row_end <= pad_x.shape[0] and col_end <= pad_x.shape[1]: # 范围不能超出图像的shape
batch.append((row_begin, row_end, col_begin, col_end)) # 取出来一部分列表[0,128,0,128]
if len(batch) == batch_size: # 够一个批次的数据
batchs.append(batch)
batch = []
if len(batch) > 0:
batchs.append(batch)
batch = []
for bat in tqdm.tqdm(batchs, desc='Batch pred'): # 添加一个批次的数据
update_prediction_center(bat) # bat只是一个裁剪边界坐标
y = pad_y[quarter_target_size:quarter_target_size + x.shape[0],
quarter_target_size:quarter_target_size + x.shape[1],
:] # 收缩切割为原来的尺寸
return y # 原图像的预测结果