爬虫实战——求是网周刊文章爬取(一)and 爬虫基本原理

@R星校长
第1关:获取新闻url
任务描述
本关任务:编写一个爬虫,并使用正则表达式获取求是周刊2019年第一期的所有文章的url。详情请查看《求是》2019年第1期 。
相关知识
获取每个新闻的url有以下几个步骤:
- 首先获取
2019年第1期页面的源码,需要解决部分反爬机制; - 找到目标
url所在位置,观察其特征; - 编写正则表达式,获取目标数据。
编程要求
使用正则表达式获取求是周刊2019年第一期的所有文章的url,返回的是一个包含所有url的列表。
预期输出:
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123924154.htm
http://www.qstheory.cn/dukan/qs/2018-12/31/c_1123923896.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923886.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923852.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923828.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923817.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923778.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923740.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923715.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123923686.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922609.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922550.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922484.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922467.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123922434.htm
http://www.qstheory.cn/dukan/qs/2019-01/01/c_1123924169.htm
开始你的任务吧,祝你成功!
import requests
import re
def geturls():
# ********** Begin ********** #
url = "http://www.qstheory.cn/dukan/qs/2014/2019-01/01/c_1123924172.htm"
#请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36",
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
}
response = requests.get(url,headers=headers)
result = response.content.decode("utf8")
urls = re.findall(',result)
# ********** End ********** #
return urls
if __name__ == "__main__":
urls = geturls()
for x in urls:
print(x)
不会的看这里,详细介绍了爬虫基本原理
文章目录
-
-
-
- 一、爬虫简介
- 二、简单爬虫架构
-
- 1.Python简单爬虫架构
- 2.Python简单爬虫架构的动态运行流程
- 三、分别讲解各模块设计思路
-
- 1.URL管理器
- 2.网页下载器
- 3.网页解析器
-
-
一、爬虫简介
爬虫:一段自动抓取互联网信息的程序
爬虫可以从一个url出发,访问其所关联的所有的url。并从每个url指向的网页中,获取我们所需要的信息。
二、简单爬虫架构
1.Python简单爬虫架构
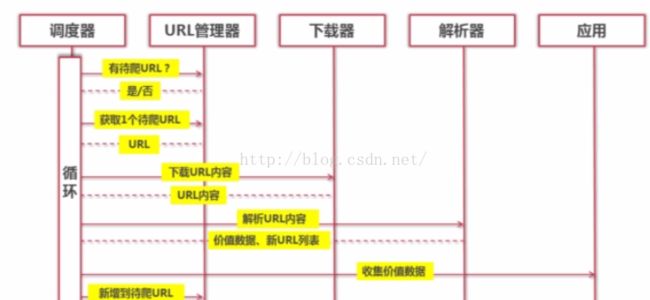
(1)爬虫调度端:启动爬虫、停止爬虫、监视爬虫的运行情况。
(2)在爬虫程序中,有三个模块:
1)Url管理器:管理将要爬取的url和已经爬取的url。将待爬取的url传送给网页下载器。
2)网页下载器:将Url指定的网页下载下来,保存为一个字符串。将这个字符串传送给网页解析器进行解析。
3)网页解析器:一方面,会解释出有价值的数据;另一方面,解析出字符串中的url,将其补充到url管理器。
这三个模块,形成了一个循环。只有有未爬取的url,这个循环就会一直继续下去。

2.Python简单爬虫架构的动态运行流程
三、分别讲解各模块设计思路
1.URL管理器
作用:管理待抓取URL集合和已抓取URL集合
目的:防止重复抓取、防止循环抓取
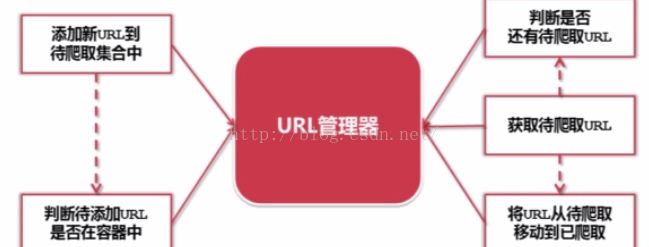
实现方式:

在这里,我们选用Python的set()来实现小型的url管理器
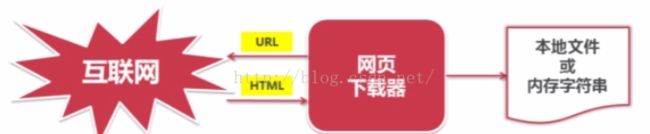
2.网页下载器
作用:将互联网上URL对应的网页下载到本地的工具
工作流程:
实现方式:

在这里,我们选择urllib.request这个简单的模块,来实现代码的下载。
使用urllib.request下载网页的三种方法:
import urllib.request as req
import http.cookiejar
url = "http://www.baidu.com"
print ("first method")
response1 = req.urlopen(url)
#if 200,succeed
print (response1.getcode())
print (len(response1.read()))
print ("second method")
request = req.Request(url);
request.add_header("user_agent","Mozilla/5.0")
response2 = req.urlopen(request)
print (response2.getcode())
print (len(response2.read()))
print ("three method")
cj = http.cookiejar.CookieJar()
opener = req.build_opener(req.HTTPCookieProcessor(cj))
req.install_opener(opener)
response3 = req.urlopen(url)
print (response3.getcode())
print (cj)
print (len(response3.read()))
3.网页解析器
作用:从网页中提取有价值的数据
从下载好的html网页或者字符串中,可以提取出url、有价值的数据。
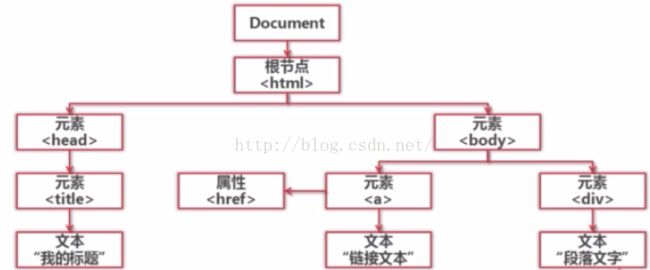
类型:正则表达式、html.parser、BeautifulSoup、lxml
其中,BeautifulSoup这个第三方插件可以使用html.parser和lxml作为它的解析器。
其中,正则表达式是模糊匹配,另外三种则是结构化的解析。
附,结构化解析:
爬虫需要反反复复的尝试,没有痛苦,就没有收获,走出舒适区,风雨过后总能见彩虹下
2020年浙江卫视《美好的时光:第9期》现场回放金志文和赖美云合唱《远走高飞》
远走高飞


