【南瓜书ML】(task1)绪论+模型评估与选择
学习总结
- 学习南瓜书,先看西瓜书本—第1章和第2章主要是讲一些基本概念和术语,可以先跳过以下知识点,等后面部分学完后再来回顾:
第1章:【1.4-归纳偏好】可以跳过
第2章:【2.3.3-ROC与AUC】及其以后的都可以跳过 - 高阶指标包括 P-R 曲线,ROC 曲线和平均精度均值。P-R 曲线的横坐标是召回率,纵坐标是精确率;ROC 曲线的横坐标是假阳性率,纵坐标是真阳性率。平均精度均值 mAP是对每个用户的精确率均值的再次平均。
文章目录
- 学习总结
- 一、机器学习导言
-
- 1.1 基本术语和符号表
-
- (1)基本术语
- (2)符号表(书中常用)
- 1.2 经验误差与过拟合
- 1.3 公式推导部分
- 二、模型评估
-
- 2.0 几个评估方法
-
- (1)留出法(hold-out)
- (2)交叉验证法
- (3)自助法
- 2.1 几个评估指标
- (1)精确率(precision,P值)
- (2)召回率(Recall,R值)
- (3)准确率和召回率的权衡
- 2.2 错误率和精度
- 2.3 公式推导部分(还需研究)
-
- (1)AUC公式(公式2.20)
- (2)排序中的loss函数定义(公式2.21)
- (3)假设检验中的置信度(公式2.27)
- (4)对期望泛化误差进行分解(公式2.41)
- 三、概率统计基础知识
-
- 3.1 二项分布参数$p$的检验
- 四、时间规划
- Reference
一、机器学习导言
1.1 基本术语和符号表
(1)基本术语
- 学习任务分为两大类:监督学习、无监督学习
- 独立同分布:假设样本空间中,全体样本服从一个未知“分布”,获得的每个样本都是独立地从这个分布上采样获得
- 两大任务:
- 分类:预测值为离散值的问题
- 回归:预测值为连续值的问题
其他概念:
归纳、演绎、概念学习、假设空间、版本空间;
归纳偏好(偏好)、奥卡姆剃刀。
(2)符号表(书中常用)
- x x x-一标量
- x − \boldsymbol{x}- x−-向量
- x \mathbf{x} x 一一变量集
- A 一一矩阵
- I-一单位阵
- X \mathcal{X} X 一一样本空间或状态空间
- D一概率分布
- D D D —一数据样本(数据集)
- H一一假设空间
- H一一假设集
- L一一学习算法
- ( ⋅ , ⋅ , ⋅ ) (\cdot, \cdot, \cdot) (⋅,⋅,⋅) 一一行向量
- ( ⋅ ; ⋅ ⋅ ) (\cdot ; \cdot \cdot) (⋅;⋅⋅) 一一列向量
- ( ⋅ ) ⊤ (\cdot)^{\top} (⋅)⊤ 一一向量或矩阵转置
- { ⋯ } \{\cdots\} {⋯} 一一集合
- ∣ { ⋯ } ∣ |\{\cdots\}| ∣{⋯}∣ 一一集合 { ⋯ } \{\cdots\} {⋯} 中元素的个数
- ∥ ⋅ ∥ p − − L p \|\cdot\|_{p}--L_{p} ∥⋅∥p−−Lp 范数, p缺省时为 L 2 L_{2} L2 范数
- P ( ⋅ ) , P ( ⋅ ∣ ⋅ ) P(\cdot), P(\cdot \mid \cdot) P(⋅),P(⋅∣⋅) 一一概率质量函数, 条件概率质量函数
- p ( ⋅ ) , p ( ⋅ ∣ ⋅ ) p(\cdot), p(\cdot \mid \cdot) p(⋅),p(⋅∣⋅) 一一概率密度函数, 条件概率密度函数
- E ∼ ∼ D [ f ( ⋅ ) ] \mathbb{E}_{\sim \sim \mathcal{D}}[f(\cdot)] E∼∼D[f(⋅)] 一一函数 f ( ⋅ ) f(\cdot) f(⋅) 对.在分布 D \mathcal{D} D 下的数学期望;意义明确时将省略 D \mathcal{D} D 和(或).
- sup ( ⋅ ) \sup (\cdot) sup(⋅) 一一上确界
- I ( ⋅ ) \mathbb{I}(\cdot) I(⋅) 一一指示函数, 在.为真和假时分别取值为 1,0
- sign ( ⋅ ) 一一符号函数, 在 : < 0 , = 0 , > 0 时分别取值为 − 1 , 0 , 1 \operatorname{sign}(\cdot) \text { 一一符号函数, 在 }:<0,=0,>0 \text { 时分别取值为 }-1,0,1 sign(⋅) 一一符号函数, 在 :<0,=0,>0 时分别取值为 −1,0,1
对上面的几个解释:
- 空间可以简单的理解为集合,假设空间是一个超集(全集)
- 全集的一部分被称为假设集,可以认为假设集是假设空间的一个子集
逗号分割:行向量
分号分割:列向量
指示函数:把逻辑空间映射成{0,1}进而参与运算
1.2 经验误差与过拟合
- 错误率:在m个样本中有个a个样本分类错误,错误率为E=a/m
- 误差:学习器的prediction和样本的真实label之间的差距
- 训练误差or经验误差:学习器在训练集上的误差
- 泛化误差:学习器在新样本上的误差
1.3 公式推导部分
- 假设样本空间 X \mathcal{X} X 和假设空间 H \mathcal{H} H 都是离散的. 令 P ( h ∣ X , L a ) P\left(h \mid X, \mathfrak{L}_{a}\right) P(h∣X,La) 代表算法 L a \mathfrak{L}_{a} La 基于训练数据 X X X 产生假设 h h h 的概率
- 令 f f f 代表我们希望学习的 真实目标函数. L a \mathfrak{L}_{a} La 的 “训练集外误差”, 即 L a \mathfrak{L}_{a} La 在训练集之外的所有样本上的误差为:
E o t e ( L a ∣ X , f ) = ∑ h ∑ x ∈ X − X P ( x ) I ( h ( x ) ≠ f ( x ) ) P ( h ∣ X , L a ) E_{o t e}\left(\mathfrak{L}_{a} | X, f\right)=\sum_{h} \sum_{\boldsymbol{x} \in \mathcal{X}-X} P(\boldsymbol{x}) \mathbb{I}(h(\boldsymbol{x}) \neq f(\boldsymbol{x})) P\left(h | X, \mathfrak{L}_{a}\right) Eote(La∣X,f)=h∑x∈X−X∑P(x)I(h(x)=f(x))P(h∣X,La)
其中 I ( ⋅ ) 是指示函数, 若. 为真则取值 1 , 否则取值 0 . \text { 其中 } \mathbb{I}(\cdot) \text { 是指示函数, 若. 为真则取值 } 1 \text {, 否则取值 } 0 \text {. } 其中 I(⋅) 是指示函数, 若. 为真则取值 1, 否则取值 0.
考虑二分类问题, 且真实目标函数可以是任何函数 X ↦ { 0 , 1 } \mathcal{X} \mapsto\{0,1\} X↦{0,1}, 函数空间 为 { 0 , 1 } ∣ X ∣ \{0,1\}^{|\mathcal{X}|} {0,1}∣X∣. 对所有可能的 f f f 按均匀分布对误差求和, 有:
∑ f E o t e ( L a ∣ X , f ) = ∑ f ∑ h ∑ x ∈ X − X P ( x ) I ( h ( x ) ≠ f ( x ) ) P ( h ∣ X , L a ) = ∑ x ∈ X − X P ( x ) ∑ h P ( h ∣ X , L a ) ∑ f I ( h ( x ) ≠ f ( x ) ) = ∑ x ∈ X − X P ( x ) ∑ h P ( h ∣ X , L a ) 1 2 2 ∣ X ∣ = 1 2 2 ∣ X ∣ ∑ x ∈ X − X P ( x ) ∑ h P ( h ∣ X , L a ) = 2 ∣ X ∣ − 1 ∑ x ∈ X − X P ( x ) ⋅ 1 \begin{aligned} \sum_{f}E_{ote}(\mathfrak{L}_a\vert X,f) &= \sum_f\sum_h\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x})\mathbb{I}(h(\boldsymbol{x})\neq f(\boldsymbol{x}))P(h\vert X,\mathfrak{L}_a) \\ &=\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x}) \sum_hP(h\vert X,\mathfrak{L}_a)\sum_f\mathbb{I}(h(\boldsymbol{x})\neq f(\boldsymbol{x})) \\ &=\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x}) \sum_hP(h\vert X,\mathfrak{L}_a)\cfrac{1}{2}2^{\vert \mathcal{X} \vert} \\ &=\cfrac{1}{2}2^{\vert \mathcal{X} \vert}\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x}) \sum_hP(h\vert X,\mathfrak{L}_a) \\ &=2^{\vert \mathcal{X} \vert-1}\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x}) \cdot 1\\ \end{aligned} f∑Eote(La∣X,f)=f∑h∑x∈X−X∑P(x)I(h(x)=f(x))P(h∣X,La)=x∈X−X∑P(x)h∑P(h∣X,La)f∑I(h(x)=f(x))=x∈X−X∑P(x)h∑P(h∣X,La)212∣X∣=212∣X∣x∈X−X∑P(x)h∑P(h∣X,La)=2∣X∣−1x∈X−X∑P(x)⋅1
南瓜书:解析:从第一步到第二步
∑ f ∑ h ∑ x ∈ X − X P ( x ) I ( h ( x ) ≠ f ( x ) ) P ( h ∣ X , L a ) = ∑ x ∈ X − X P ( x ) ∑ f ∑ h I ( h ( x ) ≠ f ( x ) ) P ( h ∣ X , L a ) = ∑ x ∈ X − X P ( x ) ∑ h P ( h ∣ X , L a ) ∑ f I ( h ( x ) ≠ f ( x ) ) \begin{aligned} &\sum_f\sum_h\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x})\mathbb{I}(h(\boldsymbol{x})\neq f(\boldsymbol{x}))P(h\vert X,\mathfrak{L}_a) \\ &=\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x})\sum_f\sum_h\mathbb{I}(h(\boldsymbol{x})\neq f(\boldsymbol{x}))P(h\vert X,\mathfrak{L}_a) \\ &=\sum_{\boldsymbol{x}\in\mathcal{X}-X}P(\boldsymbol{x}) \sum_hP(h\vert X,\mathfrak{L}_a)\sum_f\mathbb{I}(h(\boldsymbol{x})\neq f(\boldsymbol{x})) \\ \end{aligned} f∑h∑x∈X−X∑P(x)I(h(x)=f(x))P(h∣X,La)=x∈X−X∑P(x)f∑h∑I(h(x)=f(x))P(h∣X,La)=x∈X−X∑P(x)h∑P(h∣X,La)f∑I(h(x)=f(x))
第 2 步到第 3 步:
首先要知道此时我们对 f f f 的假设是任何能将样本映射到 0,1 的函数且服从均匀分布, 也就是说不止一个 f f f 且每个 f f f 出现的概率相等, 例如样本空间只有两个样本时: X = { x 1 , x 2 } , ∣ X ∣ = 2 \mathcal{X}=\left\{x_{1}, x_{2}\right\},|\mathcal{X}|=2 X={x1,x2},∣X∣=2, 那 么所有的真实目标函数 f f f 为:
f 1 : f 1 ( x 1 ) = 0 , f 1 ( x 2 ) = 0 ; f 2 : f 2 ( x 1 ) = 0 , f 2 ( x 2 ) = 1 ; f 3 : f 3 ( x 1 ) = 1 , f 3 ( x 2 ) = 0 ; f 4 : f 4 ( x 1 ) = 1 , f 4 ( x 2 ) = 1 ; \begin{aligned} f_1:f_1(\boldsymbol{x}_1)=0,f_1(\boldsymbol{x}_2)=0;\\ f_2:f_2(\boldsymbol{x}_1)=0,f_2(\boldsymbol{x}_2)=1;\\ f_3:f_3(\boldsymbol{x}_1)=1,f_3(\boldsymbol{x}_2)=0;\\ f_4:f_4(\boldsymbol{x}_1)=1,f_4(\boldsymbol{x}_2)=1; \end{aligned} f1:f1(x1)=0,f1(x2)=0;f2:f2(x1)=0,f2(x2)=1;f3:f3(x1)=1,f3(x2)=0;f4:f4(x1)=1,f4(x2)=1;
一共 2 ∣ x ∣ = 2 2 = 4 2^{|x|}=2^{2}=4 2∣x∣=22=4 个真实目标函数。
所以此时通过算法 L a \mathfrak{L}_{a} La 学习出来的模型 h ( x ) h(\boldsymbol{x}) h(x) 对每个样本无论 预测值为 0 还是 1 必然有一半的 f f f 与之预测值相等, 例如, 现在学出来的模型 h ( x ) h(x) h(x) 对 x 1 x_{1} x1 的预测值 为 1 , 也即 h ( x 1 ) = 1 h\left(\boldsymbol{x}_{1}\right)=1 h(x1)=1, 那么有且只有 f 3 f_{3} f3 和 f 4 f_{4} f4 与 h ( x ) h(\boldsymbol{x}) h(x) 的预测值相等, 也就是有且只有一半的 f f f 与 它预测值相等, 所以 ∑ f I ( h ( x ) ≠ f ( x ) ) = 1 2 2 ∣ X ∣ \sum_{f} \mathbb{I}(h(x) \neq f(x))=\frac{1}{2} 2^{|X|} ∑fI(h(x)=f(x))=212∣X∣; 第 3 步一直到最后显然成立。
在这里假设真实的目标函数 f f f 为 “任何能将样本映射到 0,1 的函数且服从均匀分布”, 但是实际情形并非如此, 通常我们只认为能高度拟合已有样本数据的函数才是真实目标函数:
- 例如, 现在已有的样本 数据为 { ( x 1 , 0 ) , ( x 2 , 1 ) } \left\{\left(x_{1}, 0\right),\left(x_{2}, 1\right)\right\} {(x1,0),(x2,1)}, 那么此时 f 2 f_{2} f2 才是我们认为的真实目标函数, 由于没有收集到或者压根不存在 { ( x 1 , 0 ) , ( x 2 , 0 ) } , { ( x 1 , 1 ) , ( x 2 , 0 ) } , { ( x 1 , 1 ) , ( x 2 , 1 ) } \left\{\left(x_{1}, 0\right),\left(x_{2}, 0\right)\right\},\left\{\left(x_{1}, 1\right),\left(x_{2}, 0\right)\right\},\left\{\left(x_{1}, 1\right),\left(x_{2}, 1\right)\right\} {(x1,0),(x2,0)},{(x1,1),(x2,0)},{(x1,1),(x2,1)} 这类样本
所以 f 1 , f 3 , f 4 f_{1}, f_{3}, f_{4} f1,f3,f4 都不算是真实目标函数。这也就是西瓜书公式 (1.3) 下面的第 3 段话举的 “骑自行车” 的例子所想表达的内容。
二、模型评估
2.0 几个评估方法
(1)留出法(hold-out)
最简单常用的,将数据集划分为训练集和测试集(2个集合互斥)。
(2)交叉验证法
【交叉验证的工作原理】
如果要对测试误差进行估计,有训练误差修正和交叉验证两种方式。前者是通过训练误差的桥梁的一种间接方式;而交叉验证是对测试误差的直接估计。
【K折交叉验证】
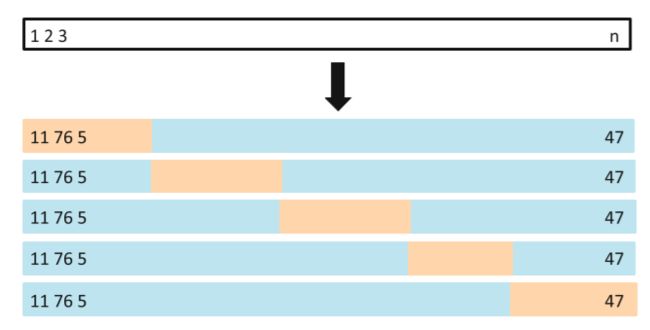
K折交叉验证:我们把训练样本分成K等分,然后用K-1个样本集当做训练集,剩下的一份样本集为验证集去估计由K-1个样本集得到的模型的精度,这个过程重复K次取平均值得到测试误差的一个估计 C V ( K ) = 1 K ∑ i = 1 K M S E i CV_{(K)} = \frac{1}{K}\sum\limits_{i=1}^{K}MSE_i CV(K)=K1i=1∑KMSEi。5折交叉验证如下图:(蓝色的是训练集,橙色的是验证集)
(3)自助法
概念: 给定包含 m m m 个样本的数据集 D D D, 每次随本, 将其拷贝放入 D ′ D^{\prime} D′, 然后再将该样本放回初始数据集 D D D 中, 使得该 样本在下次采样时仍有可能被采到。重复执行 m m m 次, 就可以得到了包 含 m m m 个样本的数据集 D ′ D^{\prime} D′ 。可以得知在 m m m 次采样中, 样本始终不被采到 的概率取极限为:
lim m → ∞ ( 1 − 1 m ) m → 1 e ≈ 0.368 \lim _{m \rightarrow \infty}\left(1-\frac{1}{m}\right)^{m} \rightarrow \frac{1}{e} \approx 0.368 m→∞lim(1−m1)m→e1≈0.368
通过自助采样, 初始样本集D中大约有 36.8 % 36.8 \% 36.8% 的样本没有出 现在 D ′ D^{\prime} D′ 中, 于是可以将 D ′ D^{\prime} D′ 作为训练集, D − D ′ D-D^{\prime} D−D′ 作为测试集。
2.1 几个评估指标
混淆矩阵:

(1)精确率(precision,P值)
是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是
P = T P T P + F P P=\frac{T P}{T P+F P} P=TP+FPTP
(2)召回率(Recall,R值)
是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN,F即预测错):
R = T P T P + F N R=\frac{T P}{T P+F N} R=TP+FNTP
【小栗子】
有60个正样本,40个负样本,我们要找出所有的正样本,系统查找出50个,其中只有40个是真正的正样本,计算上述各指标。
- TP: 将正类预测为正类数 40
- FN: 将正类预测为负类数 20
- FP: 将负类预测为正类数 10
- TN: 将负类预测为负类数 30
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%
召回率(recall) = TP/(TP+FN) = 2/3
(3)准确率和召回率的权衡
F1值:P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,通过计算F值来评价一个指标!
F1-score 的值越高,就证明模型在精确率和召回率的整体表现上越好。
F 1 = 2 ⋅ precision ⋅ recall precision + recall \mathrm{F} 1=\frac{2 \cdot \text { precision } \cdot \text { recall }}{\text { precision }+\text { recall }} F1= precision + recall 2⋅ precision ⋅ recall
2.2 错误率和精度
错误率:
E ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) ≠ y i ) E(f ; D)=\frac{1}{m} \sum_{i=1}^{m} I\left(f\left(x_{i}\right) \neq y_{i}\right) E(f;D)=m1i=1∑mI(f(xi)=yi)
精度: acc ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) = y i ) = 1 − E ( f ; D ) \begin{aligned} \operatorname{acc}(f ; D) &=\frac{1}{m} \sum_{i=1}^{m} I\left(f\left(x_{i}\right)=y_{i}\right) \\ &=1-E(f ; D) \end{aligned} acc(f;D)=m1i=1∑mI(f(xi)=yi)=1−E(f;D)
2.3 公式推导部分(还需研究)
(1)AUC公式(公式2.20)
AUC = 1 2 ∑ i = 1 m − 1 ( x i + 1 − x i ) ⋅ ( y i + y i + 1 ) \text{AUC}=\frac{1}{2}\sum_{i=1}^{m-1}(x_{i+1} - x_i)\cdot(y_i + y_{i+1}) AUC=21i=1∑m−1(xi+1−xi)⋅(yi+yi+1)
[解析]:在解释 AUC \text{AUC} AUC公式之前,我们需要先弄清楚 ROC \text{ROC} ROC曲线的具体绘制过程,下面我们就举个例子,按照西瓜书图2.4下方给出的绘制方法来讲解一下 ROC \text{ROC} ROC曲线的具体绘制过程。假设我们已经训练得到一个学习器 f ( s ) f(s) f(s),现在用该学习器来对我们的8个测试样本(4个正例,4个反例,也即 m + = m − = 4 m^+=m^-=4 m+=m−=4)进行预测,假设预测结果为:
( s 1 , 0.77 , + ) , ( s 2 , 0.62 , − ) , ( s 3 , 0.58 , + ) , ( s 4 , 0.47 , + ) , ( s 5 , 0.47 , − ) , ( s 6 , 0.33 , − ) , ( s 7 , 0.23 , + ) , ( s 8 , 0.15 , − ) (s_1,0.77,+),(s_2,0.62,-),(s_3,0.58,+),(s_4,0.47,+),(s_5,0.47,-),(s_6,0.33,-),(s_7,0.23,+),(s_8,0.15,-) (s1,0.77,+),(s2,0.62,−),(s3,0.58,+),(s4,0.47,+),(s5,0.47,−),(s6,0.33,−),(s7,0.23,+),(s8,0.15,−)
其中, + + +和 − - −分别表示为正例和为反例,里面的数字表示学习器 f ( s ) f(s) f(s)预测该样本为正例的概率,例如对于反例 s 2 s_2 s2来说,当前学习器 f ( s ) f(s) f(s)预测它是正例的概率为 0.62 0.62 0.62。根据西瓜书上给出的绘制方法可知,首先需要对所有测试样本按照学习器给出的预测结果进行排序(上面给出的预测结果已经按照预测值从大到小排好),接着将分类阈值设为一个不可能取到的最大值,显然这时候所有样本预测为正例的概率都一定小于分类阈值,那么预测为正例的样本个数为0,相应的真正例率和假正例率也都为0,所以此时我们可以在坐标 ( 0 , 0 ) (0,0) (0,0)处打一个点。接下来我们需要把分类阈值从大到小依次设为每个样本的预测值,也就是依次设为 0.77 、 0.62 、 0.58 、 0.47 、 0.33 、 0.23 、 0.15 0.77、0.62、0.58、0.47、0.33、0.23、0.15 0.77、0.62、0.58、0.47、0.33、0.23、0.15,然后每次计算真正例率和假正例率,再在相应的坐标上打一个点,最后再将各个点用直线串连起来即可得到 ROC \text{ROC} ROC曲线。需要注意的是,在统计预测结果时,预测值等于分类阈值的样本也算作预测为正例。例如,当分类阈值为 0.77 0.77 0.77时,测试样本 s 1 s_1 s1被预测为正例,由于它的真实标记也是正例,所以此时 s 1 s_1 s1是一个真正例。为了便于绘图,我们将 x x x轴(假正例率轴)的“步长”定为 1 m − \frac{1}{m^-} m−1, y y y轴(真正例率轴)的“步长”定为 1 m + \frac{1}{m^+} m+1,这样的话,根据真正例率和假正例率的定义可知,每次变动分类阈值时,若新增 i i i个假正例,那么相应的 x x x轴坐标也就增加 i m − \frac{i}{m^-} m−i,同理,若新增 j j j个真正例,那么相应的 y y y轴坐标也就增加 j m + \frac{j}{m^+} m+j。按照以上讲述的绘制流程,最终我们可以绘制出如下图所示的 ROC \text{ROC} ROC曲线:
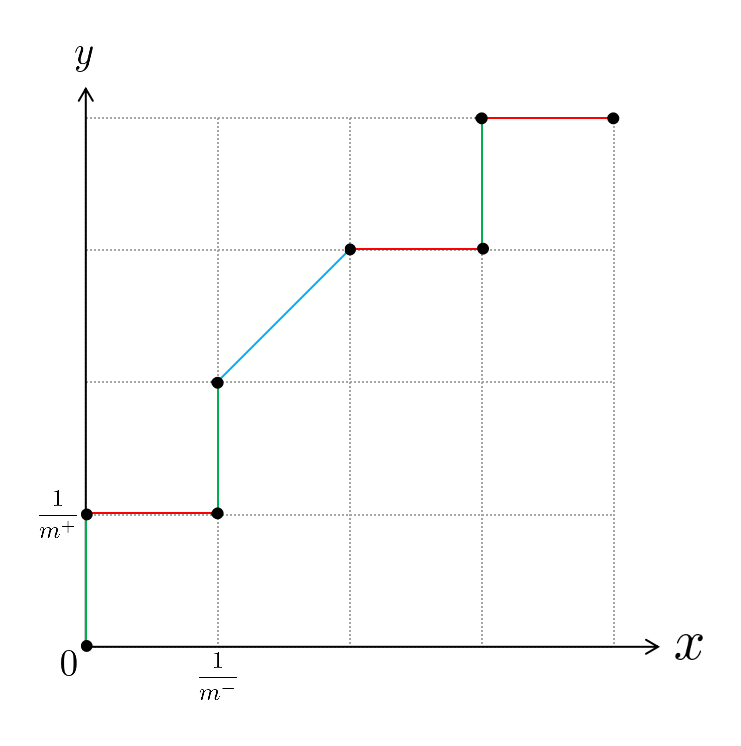
在这里我们为了能在解析公式(2.21)时复用此图所以没有写上具体地数值,转而用其数学符号代替。其中绿色线段表示在分类阈值变动的过程中只新增了真正例,红色线段表示只新增了假正例,蓝色线段表示既新增了真正例也新增了假正例。根据 AUC \text{AUC} AUC值的定义可知,此时的 AUC \text{AUC} AUC值其实就是所有红色线段和蓝色线段与 x x x轴围成的面积之和。观察上图可知,红色线段与 x x x轴围成的图形恒为矩形,蓝色线段与 x x x轴围成的图形恒为梯形,但是由于梯形面积公式既能算梯形面积,也能算矩形面积,所以无论是红色线段还是蓝色线段,其与 x x x轴围成的面积都能用梯形公式来计算,也即
1 2 ⋅ ( x i + 1 − x i ) ⋅ ( y i + y i + 1 ) \frac{1}{2}\cdot(x_{i+1} - x_i)\cdot(y_i + y_{i+1}) 21⋅(xi+1−xi)⋅(yi+yi+1)
其中 ( x i + 1 − x i ) (x_{i+1} - x_i) (xi+1−xi)表示“高”, y i y_i yi表示“上底”, y i + 1 y_{i+1} yi+1表示“下底”。那么
∑ i = 1 m − 1 [ 1 2 ⋅ ( x i + 1 − x i ) ⋅ ( y i + y i + 1 ) ] \sum_{i=1}^{m-1}\left[\frac{1}{2}\cdot(x_{i+1} - x_i)\cdot(y_i + y_{i+1})\right] i=1∑m−1[21⋅(xi+1−xi)⋅(yi+yi+1)]
表示的便是对所有红色线段和蓝色线段与 x x x轴围成的面积进行求和,此即为 AUC \text{AUC} AUC。
(2)排序中的loss函数定义(公式2.21)
ℓ r a n k = 1 m + m − ∑ x + ∈ D + ∑ x − ∈ D − ( I ( f ( x + ) < f ( x − ) ) + 1 2 I ( f ( x + ) = f ( x − ) ) ) \ell_{rank}=\frac{1}{m^+m^-}\sum_{\boldsymbol{x}^+ \in D^+}\sum_{\boldsymbol{x}^- \in D^-}\left(\mathbb{I}\left(f(\boldsymbol{x}^+)
[解析]:按照我们上述对公式(2.20)的解析思路, ℓ r a n k \ell_{rank} ℓrank可以看作是所有绿色线段和蓝色线段与 y y y轴围成的面积之和,但是公式(2.21)很难一眼看出其面积的具体计算方式,因此我们需要将公式(2.21)进行恒等变形
ℓ r a n k = 1 m + m − ∑ x + ∈ D + ∑ x − ∈ D − ( I ( f ( x + ) < f ( x − ) ) + 1 2 I ( f ( x + ) = f ( x − ) ) ) = 1 m + m − ∑ x + ∈ D + [ ∑ x − ∈ D − I ( f ( x + ) < f ( x − ) ) + 1 2 ⋅ ∑ x − ∈ D − I ( f ( x + ) = f ( x − ) ) ] = ∑ x + ∈ D + [ 1 m + ⋅ 1 m − ∑ x − ∈ D − I ( f ( x + ) < f ( x − ) ) + 1 2 ⋅ 1 m + ⋅ 1 m − ∑ x − ∈ D − I ( f ( x + ) = f ( x − ) ) ] = ∑ x + ∈ D + 1 2 ⋅ 1 m + ⋅ [ 2 m − ∑ x − ∈ D − I ( f ( x + ) < f ( x − ) ) + 1 m − ∑ x − ∈ D − I ( f ( x + ) = f ( x − ) ) ] \begin{aligned} \ell_{rank}&=\frac{1}{m^+m^-}\sum_{\boldsymbol{x}^+ \in D^+}\sum_{\boldsymbol{x}^- \in D^-}\left(\mathbb{I}\left(f(\boldsymbol{x}^+)
根据公式(2.20)中给出的 ROC \text{ROC} ROC曲线图可知,在变动分类阈值的过程当中,如果有新增真正例,那么相应地就会增加一条绿色线段或蓝色线段,所以上式中的 ∑ x + ∈ D + \sum\limits_{\boldsymbol{x}^+ \in D^+} x+∈D+∑可以看作是在遍历所有绿色和蓝色线段,那么相应地 ∑ x + ∈ D + \sum\limits_{\boldsymbol{x}^+ \in D^+} x+∈D+∑后面的那一项便是在求绿色线段或者蓝色线段与 y y y轴围成的面积,也即
1 2 ⋅ 1 m + ⋅ [ 2 m − ∑ x − ∈ D − I ( f ( x + ) < f ( x − ) ) + 1 m − ∑ x − ∈ D − I ( f ( x + ) = f ( x − ) ) ] \frac{1}{2}\cdot\frac{1}{m^+}\cdot\left[\frac{2}{m^-}\sum_{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)
同公式(2.20)中的求解思路一样,不论是绿色线段还是蓝色线段,其与 y y y轴围成的图形面积都可以用梯形公式来进行计算,所以上式表示的依旧是一个梯形的面积求解公式。其中 1 m + \frac{1}{m^+} m+1即为梯形的“高”,中括号中的那一项便是“上底+下底”,下面我们来分别推导一下“上底”(较短的那个底)和“下底”。由于在绘制 ROC \text{ROC} ROC曲线的过程中,每新增一个假正例时 x x x坐标也就新增一个单位,所以对于“上底”,也就是绿色或者蓝色线段的下端点到 y y y轴的距离,它就等于 1 m − \frac{1}{m^-} m−1乘以预测值比 x + \boldsymbol{x^+} x+大的假正例的个数,也即
1 m − ∑ x − ∈ D − I ( f ( x + ) < f ( x − ) ) \frac{1}{m^-}\sum\limits_{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)
而对于“下底”,它就等于 1 m − \frac{1}{m^-} m−1乘以预测值大于等于 x + \boldsymbol{x^+} x+的假正例的个数,也即
1 m − ( ∑ x − ∈ D − I ( f ( x + ) < f ( x − ) ) + ∑ x − ∈ D − I ( f ( x + ) = f ( x − ) ) ) \frac{1}{m^-}\left(\sum_{\boldsymbol{x}^- \in D^-}\mathbb{I}\left(f(\boldsymbol{x}^+)
(3)假设检验中的置信度(公式2.27)
ϵ ‾ = min ϵ s.t. ∑ i = ϵ × m + 1 m ( m i ) ϵ 0 i ( 1 − ϵ 0 ) m − i < α \overline{\epsilon}=\min \epsilon\quad\text { s.t. } \sum_{i=\epsilon\times m+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) \epsilon_0^{i}(1-\epsilon_0)^{m-i}<\alpha ϵ=minϵ s.t. i=ϵ×m+1∑m(mi)ϵ0i(1−ϵ0)m−i<α
具体推导过程如下:由西瓜书中的上下文可知,对 ϵ ≤ ϵ 0 \epsilon\leq\epsilon_0 ϵ≤ϵ0进行假设检验,等价于附录①中所述的对 p ≤ p 0 p\leq p_0 p≤p0进行假设检验,所以在西瓜书中求解最大错误率 ϵ ‾ \overline{\epsilon} ϵ等价于在附录①中求解事件最大发生频率 C ‾ m \frac{\overline{C}}{m} mC。由附录①可知
C ‾ = min C s.t. ∑ i = C + 1 m ( m i ) p 0 i ( 1 − p 0 ) m − i < α \overline{C}=\min C\quad\text { s.t. } \sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i}(1-p_0)^{m-i}<\alpha C=minC s.t. i=C+1∑m(mi)p0i(1−p0)m−i<α
所以
C ‾ m = min C m s.t. ∑ i = C + 1 m ( m i ) p 0 i ( 1 − p 0 ) m − i < α \frac{\overline{C}}{m}=\min \frac{C}{m}\quad\text { s.t. } \sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i}(1-p_0)^{m-i}<\alpha mC=minmC s.t. i=C+1∑m(mi)p0i(1−p0)m−i<α
将上式中的 C ‾ m , C m , p 0 \frac{\overline{C}}{m},\frac{C}{m},p_0 mC,mC,p0等价替换为 ϵ ‾ , ϵ , ϵ 0 \overline{\epsilon},\epsilon,\epsilon_0 ϵ,ϵ,ϵ0可得
ϵ ‾ = min ϵ s.t. ∑ i = ϵ × m + 1 m ( m i ) ϵ 0 i ( 1 − ϵ 0 ) m − i < α \overline{\epsilon}=\min \epsilon\quad\text { s.t. } \sum_{i=\epsilon\times m+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) \epsilon_0^{i}(1-\epsilon_0)^{m-i}<\alpha ϵ=minϵ s.t. i=ϵ×m+1∑m(mi)ϵ0i(1−ϵ0)m−i<α
(4)对期望泛化误差进行分解(公式2.41)
E ( f ; D ) = E D [ ( f ( x ; D ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) + f ˉ ( x ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y D ) 2 ] + E D [ + 2 ( f ( x ; D ) − f ˉ ( x ) ) ( f ˉ ( x ) − y D ) ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y + y − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y ) 2 ] + E D [ ( y − y D ) 2 ] + 2 E D [ ( f ˉ ( x ) − y ) ( y − y D ) ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + ( f ˉ ( x ) − y ) 2 + E D [ ( y D − y ) 2 ] \begin{aligned} E(f ; D)=& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})+\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}\right] \\ &+\mathbb{E}_{D}\left[+2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y_{D}\right)\right] \\ =& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y+y-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)^{2}\right]+\mathbb{E}_{D}\left[\left(y-y_{D}\right)^{2}\right]\\ &+2 \mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)\left(y-y_{D}\right)\right]\\ =& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\left(\bar{f}(\boldsymbol{x})-y\right)^{2}+\mathbb{E}_{D}\left[\left(y_{D}-y\right)^{2}\right] \end{aligned} E(f;D)=======ED[(f(x;D)−yD)2]ED[(f(x;D)−fˉ(x)+fˉ(x)−yD)2]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]+ED[+2(f(x;D)−fˉ(x))(fˉ(x)−yD)]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y+y−yD)2]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y)2]+ED[(y−yD)2]+2ED[(fˉ(x)−y)(y−yD)]ED[(f(x;D)−fˉ(x))2]+(fˉ(x)−y)2+ED[(yD−y)2]
[解析]:
- 第1-2步:减一个 f ˉ ( x ) \bar{f}(\boldsymbol{x}) fˉ(x)再加一个 f ˉ ( x ) \bar{f}(\boldsymbol{x}) fˉ(x),属于简单的恒等变形;
- 第2-3步:首先将中括号里面的式子展开
E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 + ( f ˉ ( x ) − y D ) 2 + 2 ( f ( x ; D ) − f ˉ ( x ) ) ( f ˉ ( x ) − y D ) ] \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}+\left(\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}+2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y_{D}\right)\right] ED[(f(x;D)−fˉ(x))2+(fˉ(x)−yD)2+2(f(x;D)−fˉ(x))(fˉ(x)−yD)]
然后根据期望的运算性质: E [ X + Y ] = E [ X ] + E [ Y ] \mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y] E[X+Y]=E[X]+E[Y]可将上式化为
E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y D ) 2 ] + E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ( f ˉ ( x ) − y D ) ] \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}\right] +\mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y_{D}\right)\right] ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]+ED[2(f(x;D)−fˉ(x))(fˉ(x)−yD)] - 第3-4步:再次利用期望的运算性质将第3步得到的式子的最后一项展开
E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ( f ˉ ( x ) − y D ) ] = E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ f ˉ ( x ) ] − E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ y D ] \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y_{D}\right)\right] = \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] - \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y_{D}\right] ED[2(f(x;D)−fˉ(x))(fˉ(x)−yD)]=ED[2(f(x;D)−fˉ(x))⋅fˉ(x)]−ED[2(f(x;D)−fˉ(x))⋅yD]- 首先计算展开后得到的第一项
E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ f ˉ ( x ) ] = E D [ 2 f ( x ; D ) ⋅ f ˉ ( x ) − 2 f ˉ ( x ) ⋅ f ˉ ( x ) ] \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] = \mathbb{E}_{D}\left[2f(\boldsymbol{x} ; D)\cdot\bar{f}(\boldsymbol{x})-2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x})\right] ED[2(f(x;D)−fˉ(x))⋅fˉ(x)]=ED[2f(x;D)⋅fˉ(x)−2fˉ(x)⋅fˉ(x)]
由于 f ˉ ( x ) \bar{f}(\boldsymbol{x}) fˉ(x)是常量,所以由期望的运算性质: E [ A X + B ] = A E [ X ] + B \mathbb{E}[AX+B]=A\mathbb{E}[X]+B E[AX+B]=AE[X]+B(其中 A , B A,B A,B均为常量)可得
E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ f ˉ ( x ) ] = 2 f ˉ ( x ) ⋅ E D [ f ( x ; D ) ] − 2 f ˉ ( x ) ⋅ f ˉ ( x ) \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] = 2\bar{f}(\boldsymbol{x})\cdot\mathbb{E}_{D}\left[f(\boldsymbol{x} ; D)\right]-2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x}) ED[2(f(x;D)−fˉ(x))⋅fˉ(x)]=2fˉ(x)⋅ED[f(x;D)]−2fˉ(x)⋅fˉ(x)
由公式(2.37)可知: E D [ f ( x ; D ) ] = f ˉ ( x ) \mathbb{E}_{D}\left[f(\boldsymbol{x} ; D)\right]=\bar{f}(\boldsymbol{x}) ED[f(x;D)]=fˉ(x),所以
E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ f ˉ ( x ) ] = 2 f ˉ ( x ) ⋅ f ˉ ( x ) − 2 f ˉ ( x ) ⋅ f ˉ ( x ) = 0 \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] = 2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x})-2\bar{f}(\boldsymbol{x})\cdot\bar{f}(\boldsymbol{x})=0 ED[2(f(x;D)−fˉ(x))⋅fˉ(x)]=2fˉ(x)⋅fˉ(x)−2fˉ(x)⋅fˉ(x)=0 - 接着计算展开后得到的第二项
E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ y D ] = 2 E D [ f ( x ; D ) ⋅ y D ] − 2 f ˉ ( x ) ⋅ E D [ y D ] \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y_{D}\right]=2\mathbb{E}_{D}\left[f(\boldsymbol{x} ; D)\cdot y_{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}_{D}\left[y_{D}\right] ED[2(f(x;D)−fˉ(x))⋅yD]=2ED[f(x;D)⋅yD]−2fˉ(x)⋅ED[yD]
由于噪声和 f f f无关,所以 f ( x ; D ) f(\boldsymbol{x} ; D) f(x;D)和 y D y_D yD是两个相互独立的随机变量,所以根据期望的运算性质: E [ X Y ] = E [ X ] E [ Y ] \mathbb{E}[XY]=\mathbb{E}[X]\mathbb{E}[Y] E[XY]=E[X]E[Y](其中 X X X和 Y Y Y为相互独立的随机变量)可得
E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ y D ] = 2 E D [ f ( x ; D ) ⋅ y D ] − 2 f ˉ ( x ) ⋅ E D [ y D ] = 2 E D [ f ( x ; D ) ] ⋅ E D [ y D ] − 2 f ˉ ( x ) ⋅ E D [ y D ] = 2 f ˉ ( x ) ⋅ E D [ y D ] − 2 f ˉ ( x ) ⋅ E D [ y D ] = 0 \begin{aligned} \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y_{D}\right]&=2\mathbb{E}_{D}\left[f(\boldsymbol{x} ; D)\cdot y_{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}_{D}\left[y_{D}\right] \\ &=2\mathbb{E}_{D}\left[f(\boldsymbol{x} ; D)\right]\cdot \mathbb{E}_{D}\left[y_{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}_{D}\left[y_{D}\right] \\ &=2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}_{D}\left[y_{D}\right]-2\bar{f}(\boldsymbol{x})\cdot \mathbb{E}_{D}\left[y_{D}\right] \\ &= 0 \end{aligned} ED[2(f(x;D)−fˉ(x))⋅yD]=2ED[f(x;D)⋅yD]−2fˉ(x)⋅ED[yD]=2ED[f(x;D)]⋅ED[yD]−2fˉ(x)⋅ED[yD]=2fˉ(x)⋅ED[yD]−2fˉ(x)⋅ED[yD]=0
所以
E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ( f ˉ ( x ) − y D ) ] = E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ f ˉ ( x ) ] − E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ⋅ y D ] = 0 + 0 = 0 \begin{aligned} \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\left(\bar{f}(\boldsymbol{x})-y_{D}\right)\right] &= \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot\bar{f}(\boldsymbol{x})\right] - \mathbb{E}_{D}\left[2\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})\right)\cdot y_{D}\right] \\ &= 0+0 \\ &=0 \end{aligned} ED[2(f(x;D)−fˉ(x))(fˉ(x)−yD)]=ED[2(f(x;D)−fˉ(x))⋅fˉ(x)]−ED[2(f(x;D)−fˉ(x))⋅yD]=0+0=0
- 首先计算展开后得到的第一项
- 第4-5步:同第1-2步一样,减一个 y y y再加一个 y y y,属于简单的恒等变形;
- 第5-6步:同第2-3步一样,将最后一项利用期望的运算性质进行展开;
- 第6-7步:因为 f ˉ ( x ) \bar{f}(\boldsymbol{x}) fˉ(x)和 y y y均为常量,所以根据期望的运算性质可知,第6步中的第2项可化为
E D [ ( f ˉ ( x ) − y ) 2 ] = ( f ˉ ( x ) − y ) 2 \mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)^{2}\right]=\left(\bar{f}(\boldsymbol{x})-y\right)^{2} ED[(fˉ(x)−y)2]=(fˉ(x)−y)2
同理,第6步中的最后一项可化为
2 E D [ ( f ˉ ( x ) − y ) ( y − y D ) ] = 2 ( f ˉ ( x ) − y ) E D [ ( y − y D ) ] 2\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)\left(y-y_{D}\right)\right]=2\left(\bar{f}(\boldsymbol{x})-y\right)\mathbb{E}_{D}\left[\left(y-y_{D}\right)\right] 2ED[(fˉ(x)−y)(y−yD)]=2(fˉ(x)−y)ED[(y−yD)]
由于此时假设噪声的期望为零,也即 E D [ ( y − y D ) ] = 0 \mathbb{E}_{D}\left[\left(y-y_{D}\right)\right]=0 ED[(y−yD)]=0,所以
2 E D [ ( f ˉ ( x ) − y ) ( y − y D ) ] = 2 ( f ˉ ( x ) − y ) ⋅ 0 = 0 2\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y\right)\left(y-y_{D}\right)\right]=2\left(\bar{f}(\boldsymbol{x})-y\right)\cdot 0=0 2ED[(fˉ(x)−y)(y−yD)]=2(fˉ(x)−y)⋅0=0
三、概率统计基础知识
3.1 二项分布参数 p p p的检验
设某事件发生的概率为 p p p, p p p未知,作 m m m次独立试验,每次观察该事件是否发生,以 X X X记该事件发生的次数,则 X X X服从二项分布 B ( m , p ) B(m,p) B(m,p),现根据 X X X检验如下假设:
H 0 : p ≤ p 0 H 1 : p > p 0 \begin{aligned} H_0:p\leq p_0\\ H_1:p > p_0 \end{aligned} H0:p≤p0H1:p>p0
由二项分布本身的特性可知: p p p越小, X X X取到较小值的概率越大。因此,对于上述假设,一个直观上合理的检验为
φ : 当 X ≤ C 时接受 H 0 , 否则就拒绝 H 0 \varphi:\text{当}X\leq C\text{时接受}H_0,\text{否则就拒绝}H_0 φ:当X≤C时接受H0,否则就拒绝H0
其中, C ∈ N C\in N C∈N表示事件最大发生次数。此检验对应的功效函数为
β φ ( p ) = P ( X > C ) = 1 − P ( X ≤ C ) = 1 − ∑ i = 0 C ( m i ) p i ( 1 − p ) m − i = ∑ i = C + 1 m ( m i ) p i ( 1 − p ) m − i \begin{aligned} \beta_{\varphi}(p)&=P(X>C)\\ &=1-P(X\leq C) \\ &=1-\sum_{i=0}^{C}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p^{i} (1-p)^{m-i} \\ &=\sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p^{i} (1-p)^{m-i} \\ \end{aligned} βφ(p)=P(X>C)=1−P(X≤C)=1−i=0∑C(mi)pi(1−p)m−i=i=C+1∑m(mi)pi(1−p)m−i
由于“ p p p越小, X X X取到较小值的概率越大”可以等价表示为: P ( X ≤ C ) P(X\leq C) P(X≤C)是关于 p p p的减函数(更为严格的数学证明参见参考文献[1]中第二章习题7),所以 β φ ( p ) = P ( X > C ) = 1 − P ( X ≤ C ) \beta_{\varphi}(p)=P(X>C)=1-P(X\leq C) βφ(p)=P(X>C)=1−P(X≤C)是关于 p p p的增函数,那么当 p ≤ p 0 p\leq p_0 p≤p0时, β φ ( p 0 ) \beta_{\varphi}(p_0) βφ(p0)即为 β φ ( p ) \beta_{\varphi}(p) βφ(p)的上确界。
又因为,根据参考文献[1]中5.1.3的定义1.2可知,检验水平 α \alpha α默认取最小可能的水平,所以在给定检验水平 α \alpha α时,可以通过如下方程解得满足检验水平 α \alpha α的整数 C C C:
α = sup { β φ ( p ) } \alpha =\sup \left\{\beta_{\varphi}(p)\right\} α=sup{βφ(p)}
显然,当 p ≤ p 0 p\leq p_0 p≤p0时:
α = sup { β φ ( p ) } = β φ ( p 0 ) = ∑ i = C + 1 m ( m i ) p 0 i ( 1 − p 0 ) m − i \begin{aligned} \alpha &=\sup \left\{\beta_{\varphi}(p)\right\} \\ &=\beta_{\varphi}(p_0) \\ &=\sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i} \end{aligned} α=sup{βφ(p)}=βφ(p0)=i=C+1∑m(mi)p0i(1−p0)m−i
对于此方程,通常不一定正好解得一个整数 C C C使得方程成立,较常见的情况是存在这样一个 C ‾ \overline{C} C使得
∑ i = C ‾ + 1 m ( m i ) p 0 i ( 1 − p 0 ) m − i < α ∑ i = C ‾ m ( m i ) p 0 i ( 1 − p 0 ) m − i > α \begin{aligned} \sum_{i=\overline{C}+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}<\alpha \\ \sum_{i=\overline{C}}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i} (1-p_0)^{m-i}>\alpha \end{aligned} i=C+1∑m(mi)p0i(1−p0)m−i<αi=C∑m(mi)p0i(1−p0)m−i>α
此时, C C C只能取 C ‾ \overline{C} C或者 C ‾ + 1 \overline{C}+1 C+1,若 C C C取 C ‾ \overline{C} C,则相当于升高了检验水平 α \alpha α,若 C C C取 C ‾ + 1 \overline{C}+1 C+1则相当于降低了检验水平 α \alpha α,具体如何取舍需要结合实际情况,但是通常为了减小犯第一类错误的概率,会倾向于令 C C C取 C ‾ + 1 \overline{C}+1 C+1。下面考虑如何求解 C ‾ \overline{C} C:易证 β φ ( p 0 ) \beta_{\varphi}(p_0) βφ(p0)是关于 C C C的减函数,所以再结合上述关于 C ‾ \overline{C} C的两个不等式易推得
C ‾ = min C s.t. ∑ i = C + 1 m ( m i ) p 0 i ( 1 − p 0 ) m − i < α \overline{C}=\min C\quad\text { s.t. } \sum_{i=C+1}^{m}\left(\begin{array}{c}{m} \\ {i}\end{array}\right) p_0^{i}(1-p_0)^{m-i}<\alpha C=minC s.t. i=C+1∑m(mi)p0i(1−p0)m−i<α
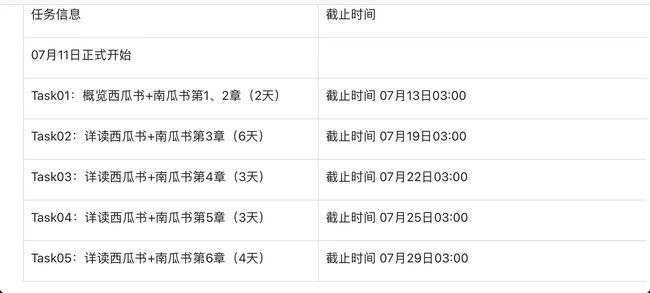
四、时间规划
Reference
[1] 陈希孺编著.概率论与数理统计[M].中国科学技术大学出版社,2009
[2] B 站视频教程:https://www.bilibili.com/video/BV1Mh411e7VU
[3] 线上南瓜书:https://datawhalechina.github.io/pumpkin-book/#/chapter1/chapter1
[4] 开源地址:https://github.com/datawhalechina/pumpkin-book
[5] 周志华《机器学习》版本空间
[6] 周志华老师《机器学习》假设空间和版本空间概念辨析