冯诺依曼体系结构_存算一体:突破冯诺依曼架构瓶颈的希望?
01
—
冯·诺依曼架构的瓶颈
传统的计算机采用冯·诺依曼体系结构,在这种体系结构中计算和存储功能是分离的,分别由中央处理器CPU 和存储器完成。CPU 和存储器通过总线互连通信,CPU 从存储器读出数据,完成计算,然后将结果写回存储器。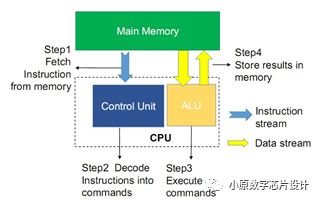
Fig. 1. 冯·诺依曼架构示意图
随着半导体产业的发展和需求的差异,处理器和存储器二者之间走向了不同的工艺路线。面向用户对处理器的高性能需求,半导体厂商通过减小器件尺寸,使用更多的金属布线层来降低互连线延迟,不断提高处理器的性能。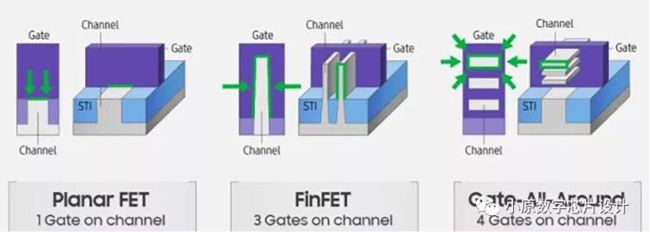
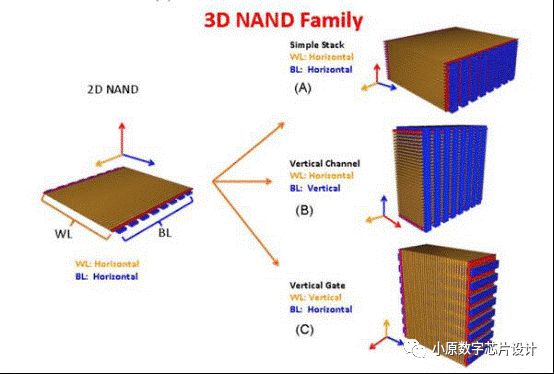
Fig. 3. 3D NAND Flash Memory
处理器与存储器需求不同,工艺不同,封装不同,导致二者在工业生产层面无法完美兼容,且二者之间的性能差距越来越大。当前主流的商用微处理器主频已达3GHz以上,存储总线主频仅400MHz;处理器速度每年增长60%,存储器存取延迟每年仅改善7%。处理器性能远远大于DRAM。由通信带宽和延迟构成的“存储墙(Memory wall)”成为提高系统性能的最大障碍。以Intel i9-7980XE 18 核 36 线程CPU为例,其配合超频过的 DDR4 3200MHz 的内存,测试出的内存读取速度为 90GB/S。再看图中的 L1 Cache,3.7TB/S。这颗 CPU 最大睿频 4.4GHz,就是说 CPU 执行一个指令需要的时间是0.22ns(纳秒),而内存的延迟是 68.1ns。换句话说,只要去内存里取一个字节,就需要 CPU 等待 300 个周期。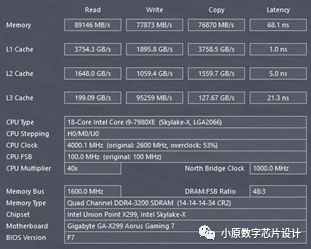
Fig. 4. CPU and cache memory speed mismatch
存储与计算模块的分离带来的问题还有功耗墙(power wall)。随着半导体工艺的演进,数据迁移的效率却没有显著提高,导致数据迁移所消耗的能量与数据计算所消耗的能量之间的功耗比越来越大。根据研究显示,数据搬运消耗的能耗是浮点计算的4到1000倍,而且随着半导体工艺的进步,虽然总体功耗下降,但是数据搬运的功耗占比越来越大。Intel的研究显示,工艺到了7nm时代,访存功耗达到25pJ/bit(45.5%)通信功耗达到10pJ/bit(18.2%)数据传输和访问功耗占比达到了63.7%。
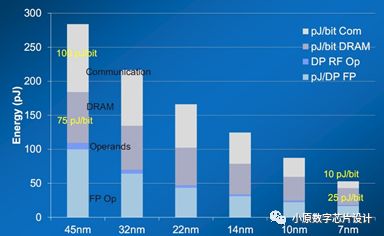
Fig. 5. 不同工艺节点下的energy consumption
02
—
存算一体
学术界与产业界都希望尽快寻找到一种新的架构,来解决现在面临的问题。尤其随着5G商用和云计算需求的迅猛增长,建设新一代适用各类AI场景的大规模数据中心成为各大互联网巨头的重要目标。于 是存算一体(In-memory Computing)作为一项极有前景的技术开始崭露头角。存算一体芯片技术,旨在把传统以计算为中心的架构转变为以数据为中心的架构,其直接利用存储器进行数据处理,从而把数据存储与计算融合在同一个芯片当中,可以彻底消除冯·诺依曼架构瓶颈。
今年年初阿里达摩院发布了2020年十大科技趋势,它认为存算一体是突破AI算力瓶颈的关键技术。因为利用存算一体技术,设备性能不仅能够得到提升,其成本也能够大幅降低。为了推动这项技术的发展,近两年的芯片设计顶会ISSCC已经为其设立了专门的议程,同时2019年电子器件领域顶级会议IEDM有三个专门的议程共二十余篇存内计算相关的论文。 其实存内计算的核心思想很简单,就是把带权重加乘计算的权重部分存在内存单元中,然后在内存的核心电路上做修改,从而让读出的过程就是输入数据和权重在模拟域做点乘的过程,相当于实现了输入的带权重累加,即卷积运算。而同时,由于卷积运算是深度学习算法中的核心组成部分,因此存内计算非常适合AI,对未来AI芯片的存算一体和算力突破都有帮助。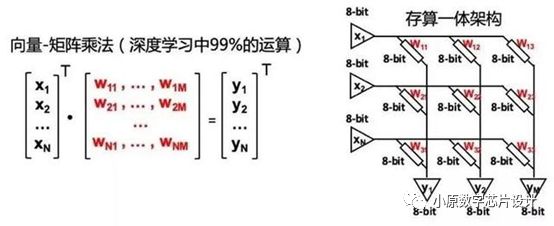
Fig. 6. 向量-矩阵乘法与存算一体架构[4]
随着物联网、人工智能等大数据应用的兴起,存算一体技术得到国内外学术界与产业界的广泛研究与应用。在2017年微处理器顶级年会(Micro 2017)上,包括英伟达、英特尔、微软、三星、苏黎世联邦理工学院与加州大学圣塔芭芭拉分校等都推出了他们的存算一体系统原型[1-3]。根据存储器件的存储易失性分类,计算型存储/存算一体的实现主要聚焦在两类存储上:
(1)基于易失性的SRAM或DRAM构建 基于SRAM的存内计算芯片目前可支持无进位乘法运算的计算型cache,相关厂商在2018年还发布了面向深度学习算法的神经Cache,并在逻辑操作基础上实现了加法、乘法和减法操作;2017年,业界基于成熟DRAM存储器件实现了卷积神经网络的计算功能,实验数据表明,针对整数运算,与GPU相比,新架构可以获得7.7倍的性能提升和15倍的能效提升。 (2)基于非易失性的相变存储器PCM、阻变存储器/忆阻器ReRAM、浮栅器件和闪存FLASH构建 近年来非易失性存储器技术,例如闪存(Flash)、忆阻器(阻变存储器 RRAM)、相变存储器(PCM)与自旋磁存储器(MRAM)等[4-8],为存算一体芯片的高效实施带来了新的曙光。这些非易失性存储器的电阻式存储原理可以提供固有的计算能力,因此可以在同一个物理单元地址同时集成数据存储与数据处理功能。此外,非易失性可以让数据直接存储在片上系统中,实现即时开机/关机,而不需要额外的片外存储器。惠普实验室的Williams教授团队在2010年就提出并验证利用忆阻器实现简单布尔逻辑功能[9]。随后,一大批相关研究工作不断涌现。2016年,美国加州大学圣塔芭芭拉分校(UCSB)的谢源教授团队提出利用RRAM构建基于存算一体架构的深度学习神经网络(简称为PRIME[10]),受到业界的广泛关注。测试结果表明,相比基于冯诺依曼计算架构的传统方案,PRIME可以实现功耗降低约20倍、速度提高约50倍[11]。这种方案可以高效地实现向量-矩阵乘法运算,在深度学习神经网络加速器领域具有巨大的应用前景。
PCM具有与RRAM类似的多比特特性,可以基于类似的原理实现向量-矩阵乘法运算。对于MRAM而言,由于其二值存储物理特性,难以实现基于交叉点阵列的向量-矩阵乘法运算,因此基于MRAM的存算一体通常采用布尔逻辑的计算范式[12-14]。

Fig. 7. 存算一体技术的发展路线
但由于技术/工艺的成熟度等问题,迄今基于相变存储器、阻变存储器与自旋存储器的存算一体芯片尚未实现产业化。与此同时,基于Nor Flash的存算一体芯片技术近期受到产业界的格外关注,自2016年UCSB发布第一个样片以来,多家初创企业在进行研发,例如美国的Mythic, Syntiant,国内的知存科技等,并受到国内外主流半导体企业与资本的产业投资。相比较而言,Nor Flash在技术/工艺成熟度与成本方面在端侧AIoT领域具有优势。
03
—
前景与挑战
不同于传统的数字电路计算,存内计算是用模拟电路做计算,这对存储器本身和存内计算的设计者都是一个全新的、需要探索的领域。与传统芯片相比,该芯片在成本和功耗上有非常显著的改进,包括存储与计算模块之间的通信成本也大大降低了。从目前的实现方式看,存算一体分成了两个路线:基于成熟的易失性存储和不成熟的非易失性存储。无论是哪种路线,都存在一定的挑战。 基于成熟的易失性存储:这种方式下的计算型存储/存内计算/存算一体需要融合处理器工艺和存储器工艺。但由于目前处理器与存储器的制造工艺不同,若要在处理器上实现存储器的功能,则可能会降低存储器的存储密度;若要在存储器上实现处理器的功能,则可能会影响处理器的运行速度。很难在性能和容量上有一个很好的折衷。 基于不成熟的非易失性存储:非易失性存储对存储和计算的天然融合特定是构建计算型存储/存内计算/存算一体的最佳器件。但是,由于目前厂商和工艺均未成熟,存算一体芯片的研发与制备都存在巨大大的挑战。特别是基于新型存储介质的存算一体技术,器件物理原理、行为特性、集成工艺都不尽相同,需要跨层协同来实现性能(精度、功耗、时延等)与成本的最优。 无论基于哪种实现方式,存算一体都是可以彻底解决冯·诺依曼瓶颈的一项非常有前景的技术,相信随着学术界与产业界的研究发展,该技术可以为社会带来新的变革,创造出更大的价值。 Reference:[1] S. Li, D. Niu, K. T. Malladi, B.Brennan, and Y. Xie, “DRISA: A DRAM-based Reconfigurable In-Situ Accelerator,”in IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 288-301,Apr. 2017.
[2] V. Seshadri, D. Lee, T. Mullins, H.Hassan, A. Boroumand, J. Kim, M. A. Kozuch, O. Mutlu, P. Gibbons, and T. Mowry,“Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAMTechnology,” in IEEE/ACM International Symposium on Microarchitecture (MICRO),pp. 273-287, Oct. 2017.
[3] S. R. Agrawal, S. Idicula, A. Raghavan,E. Vlachos, V. Varadarajan, and E. Sedlar, “A Many-Core Architecture forIn-Memory Data Processing,” in IEEE/ACM International Symposium onMicroarchitecture (MICRO), pp. 245-258, Oct. 2017.
[4] X. Guo, F. Bayat, M. Bavandpour, M.Klachko, M. Mahmoodi, M. Prezioso, K. Likharev, and D. Strukov, “Fast,Energy-Efficient, Robust, and Reproducible Mixed-Signal Neuromorphic ClassifierBased on Embedded NOR Flash Memory Technology,” in IEEE International ElectronDevices Meeting (IEDM), pp. 6.5.1-6.5.4, Dec. 2017.
[5] H. Wong, and S. Salahuddin, “MemoryLeads the Way to Better Computing,” Nature Nanotechnology, vol. 10, no. 3, pp.191-194, Mar. 2015.
[6] L. Wang et al., “Voltage-ControlledMagnetic Tunnel Junctions for Processing-In-Memory Implementation,” IEEEElectron Device Letters, vol. 39, no. 3, pp. 440-443, March 2018.
[7] W. Kang, Y. Zhang, Z. Wang, J. O.Klein, C. Chappert, D. R. Ravolosona, G. Wang, Y. Zhang, and W. Zhao,“Spintronics, Emerging Ultra-Low Power Circuits and Systems Beyond MOSTechnology,” ACM Journal on Emerging Technologies in Computing Systems (JETC),vol. 12, no. 2, pp. 1-42, Sep. 2015.
[8] A. Chen, “A Review of EmergingNon-Volatile Memory (NVM) Technologies and Applications,” Solid-StateElectronics, vol. 125, pp. 25-38, Nov. 2016.
[9] J. Borghetti, G. Snider, P.Kuekes, J. Yang, D. Stewart, and R. Williams, “Memristive SwitchesEnable Stateful Logic Operations via Material Implication,”Nature, vol. 464, no. 7290, pp. 873-876, Apr. 2010.
[10] P. Chi, S. Li, C. Xu, T.Zhang, J. Zhao, Y. Liu, Y. Wang, and Y. Xie, “PRIME: A NovelProcessing-in-Memory Architecture for Neural Network Computation in ReRAM-basedMain Memory,”ACM SIGARCH Computer Architecture News, vol. 44, no. 3, pp. 27-39, Jun. 2016.
[11] F. Su, W. Chen, L. Xia, C. Lo, T.Tang, Z. Wang, K. Hsu, M. Cheng, J. Li, Y. Xie, Y. Wang, M. Chang, H. Yang, andY. Liu, “A 462GOPs/J RRAM-Based Nonvolatile Intelligent Processor for EnergyHarvesting IoE System Featuring Nonvolatile Logics and Processing-in-Memory,”in Symposium on VLSI Technology, pp. C260-C261, Jun. 2017.
[12] H. Zhang, W. Kang, K. Cao, B. Wu, Y.Zhang, and W. Zhao, “Spintronic Processing Unit in Spin Transfer TorqueMagnetic Random Access Memory,” IEEE Transactions on Electron Devices, vol. 66,no. 4, pp. 2017 – 2022, Apr. 2019.
[13] H. Zhang, W. Kang, L. Wang, K. L.Wang, and W. Zhao, “Stateful Reconfigurable Logic via a Single-Voltage-GatedSpin Hall-Effect Driven Magnetic Tunnel Junction in a Spintronic Memory,” IEEETransactions on Electron Devices, vol. 64, no. 10, pp. 4295-4301, Oct. 2017.
[14] W. Kang, H. Wang, Z. Wang,Y. Zhang,and W. Zhao, “In-Memory Processing Paradigm for Bitwise Logic Operations inSTT-MRAM,” IEEE Transactions on Magnetics, vol. 53, no. 11, pp. 1-4, Nov.2017.
图片来源于网络,如有侵权请联系删除。
撰文 | YAX
编辑 | YAX