梯度下降与一元线性回归
梯度下降
基本概念
梯度下降法(gradient descent),又名最速下降法(steepest descent)是求解无约束最优化问题最常用的方法。它是一种迭代方法,每一步主要的操作是求解目标函数的梯度向量,将当前位置的负梯度方向作为搜索方向(因为在该方向上目标函数下降最快)
方向导数:方向导数是在函数定义域的点对某一方向求导得到的导数。
梯度:梯度是一个向量,函数在该点处沿着该方向(此梯度的方向)变化最快。
公式为: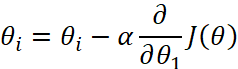

算法流程
(1)随机初始参数
(2)确定学习率
(3)求出损失函数对参数梯度
(4)按照公式更新参数
(5)重复(3)(4)直到满足终止条件(如:损失函数或参数更新变化值小于某个阈值,或者训练次数达到设定阈值)
例:假设损失函数为:![]() ,采用梯度下降法求损失函数的极值,写出在
,采用梯度下降法求损失函数的极值,写出在
![]() =0,
=0, =0.05下,两轮迭代参数
=0.05下,两轮迭代参数![]() 的变化过程。
的变化过程。
解:(1)初始化: ![]() =0,=0.05
=0,=0.05
(2)计算 ![]() =0的梯度: 2(
=0的梯度: 2(![]() -3)=-6
-3)=-6
(3)修改 ![]() =0-0.05*(-6)=0.3
=0-0.05*(-6)=0.3
(4)abs(0-0.3)>0.0001,转向(2)
(5)计算 ![]() =0.3的梯度:2(
=0.3的梯度:2(![]() -3)=2(0.3-3)=-5.4
-3)=2(0.3-3)=-5.4
(6)修改 ![]() =0.3-0.05*(-5.4)=0.57
=0.3-0.05*(-5.4)=0.57
实例:用代码实现梯度下降
1.单元函数求最低点
计算函数
 的最低点
的最低点
(1)手工推导

(2)代码实现
import numpy as np
import matplotlib.pyplot as plt
# f的函数
def f(x):
return x ** 2 * 0.5 - 2 * x + 3
def d_f(x):
return x - 2
#定义梯度下降法
def gradient_descent():#gradient梯度
times = 100#迭代数
alpha = 0.1#学习率
x = 10#设置的初始值
x_axis = np.linspace(-10,10)#设定x轴的坐标系
fig = plt.figure(1,figsize=(5,5))#设定画布的大小
ax = fig.add_subplot(1,1,1)#设定画布内只有一个图
ax.set_xlabel('X',fontsize=14)
ax.set_ylabel('Y',fontsize=14)
ax.plot(x_axis,f(x_axis))#作图
#进行迭代
for i in range(times):
x1 = x
y1 = f(x)
print("第%d次迭代:x=%f,y=%f" % (i+1,x,y1))
x = x - alpha * d_f(x)#更新x
y = f(x)
ax.plot([x1,x],[y1,y],'ko',lw=1,ls='-',color='coral')
plt.show()
if __name__ == "__main__":
gradient_descent()对if __name__ == "__main__"的理解 参考:https://blog.csdn.net/xiaoxik/article/details/78749361
代码运行结果:

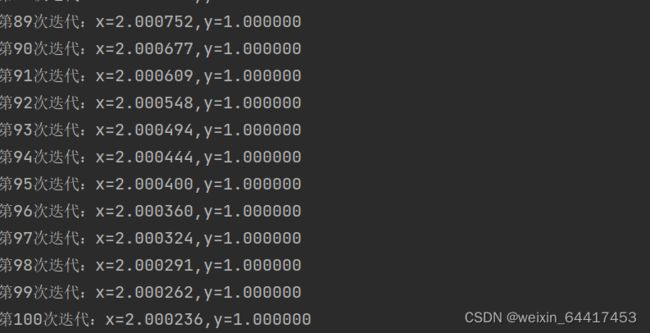
2.多元函数求最低点
计算函数![]() 的最低点
的最低点
(1)手工推导

(2)代码实现:
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
def f(x,y):
return (x - 10)**2 + (y - 10)**2
def d_fx(x,y):
return 2 * (x - 10)
def d_fy(x,y):
return 2 * (y - 10)
def gradient_descent():
times=100
alpha=0.1
x=20
y=20
fig = Axes3D(plt.figure())
x_axis = np.linspace(0,20,100)
y_axis = np.linspace(0,20,100)
x_axis, y_axis = np.meshgrid(x_axis, y_axis)#将数据转化为网格数据
z = f(x_axis,y_axis)
fig.set_xlabel('X',fontsize=14)
fig.set_ylabel('Y',fontsize=14)
fig.set_zlabel('Z',fontsize=14)
fig.view_init(elev=60,azim=300)#设置3D图的俯视角度,方便查看梯度下降曲线
fig.plot_surface(x_axis,y_axis,z,rstride=1,cstride=1,cmap=plt.get_cmap('rainbow'))#作出底图
#计算极值
for i in range(times):
x1 = x
y1 = y
z1 = f(x,y)
print("第%d次迭代:x=%f,y=%f,z=%f" %(i+1,x1,y1,z1))
x = x - alpha * d_fx(x,y)
y = y - alpha * d_fx(x,y)
z= f(x,y)
fig.plot([x1,x],[y1,y],[z1,z],'ko',lw=2,ls='-')
plt.show()
if __name__ == "__main__":
gradient_descent()代码运行结果:

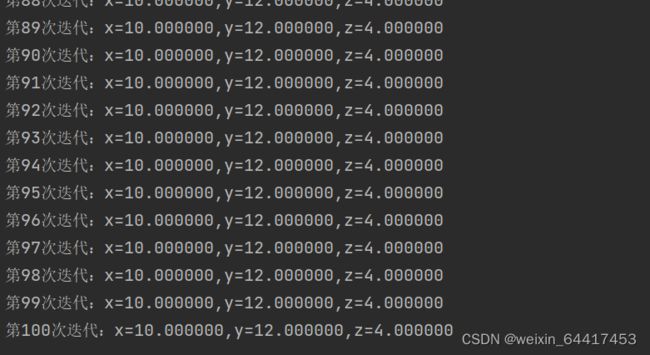
批量梯度下降(BGD)
批量梯度下降算法需要计算整个训练集的梯度,即:
![]()
其中为学习率,用来控制更新的“力度/步长”。
优点:对于凸目标函数,可以保证全局最优;对于非凸目标函数,可以保证一个局部最优。
缺点:速度慢;数据量大时不可行;无法在线优化(即无法处理动态产生的新样本)。
随机梯度下降(SGD)
随机梯度下降算法,仅计算 某个样本的梯度,即针对某一个训练样本xi及其label yi 更新及其参数:![]()
逐步减小学习率,SGD表现得同BGD很相似,最后都可以有不错的收敛。
优点:更新频次快,优化速度更快;可以在线优化(可以处理动态产生的新样本);一定的随机性导致有几率跳出局部最优(随机性来自于用一个样本的梯度去代替整体样本的梯度)。
缺点:随机性可能导致收敛复杂化,即使到达最优点仍然会进行过度优化,因此SGD的优化过程相比BGD充满动荡。
一元线性回归
线性回归概念
回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析;如果回归分析中包括两个或者两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
一元线性回归其实就是从一堆训练集中去算出一条直线,使数据集到直线之间的距离差最小。
最简单的模型如图所示:![]()
下面两个模型都是线性回归模型

原理引入
唯一特征x,共有m=500个数据数量,Y是实际结果,要从中找到一条直线,使数据集到直线之间的距离差最小,如下图所示:

那要如何完成这个操作呢?
思路如下:
先假设一条直线:
![]()
可以将特征X中每一个![]() 都带入其中,得到对应的
都带入其中,得到对应的![]() ,定义可以将损失定义为
,定义可以将损失定义为![]() 和
和![]() 之间的差值平方的和:
之间的差值平方的和:
![]()
为了之后的计算将其改为:

接下来只需求出![]() 的最小值即可
的最小值即可
实例:
波士顿房价

使用梯度下降求解线性回归(求![]() ,
,![]() )
)
![]()
代码如下:
import matplotlib.pyplot as plt
import matplotlib
from math import pow
from random import uniform
import random
x0 = [150,200,250,300,350,400,600]
y0 = [6450,7450,8450,9450,11450,15450,18450]
#为了计算方便,将所有数据缩小100倍
x = [1.5,2,2.5,3,3.5,4,6]
y = [64.5,74.5,84.5,94.5,114.5,154.5,184.5]
#线性回归函数为y=theta0 + theta1*x
#参数定义
theta0 = 0.1#对theta赋值
theta1 = 0.1#对theta赋值
alpha = 0.1#学习率
m = len(x)
count0 = 0
theta0_list = []
theta1_list = []
#使用批量梯度下降法
for num in range(10000):
count0 +=1
diss = 0#误差
deriv0 = 0
deriv1 = 0
#求导
for i in range(m):
deriv0 +=(theta0+theta1*x[i]-y[i])/m
deriv1 +=((theta0+theta1*x[i]-y[i])/m)*x[i]
#更新theta0和theta1
for i in range(m):
theta0 = theta0 - alpha*(theta0+theta1*x[i]-y[i])/m
theta1 = theta1 - alpha*((theta0+theta1*x[i]-y[i])/m)*x[i]
#求损失函数J()
for i in range(m):
diss = diss + (1/(2*m))*pow((theta0+theta1*x[i]-y[i]),2)
theta0_list.append(theta0*100)
theta1_list.append(theta1)
#如果误差已经很小,则退出循环
if diss<=100:
break
theta0 = theta0*100#前面所有数据缩小了100倍,所以求出来的theta0需要放大100倍,theta1不用变
#使用随机梯度下降法
theta2 = 0.1
theta3 = 0.1
count1 = 0
theta2_list = []
theta3_list = []
for num in range(10000):
count1 += 1
diss = 0 # 误差
deriv2 = 0
deriv3 = 0
# 求导
for i in range(m):
deriv2 += (theta2 + theta3 * x[i] - y[i]) / m
deriv3 += ((theta2 + theta3 * x[i] - y[i]) / m) * x[i]
# 更新theta2和theta3
for i in range(m):
theta2 = theta2 - alpha * (theta2 + theta3 * x[i] - y[i]) / m
theta1 = theta1 - alpha * ((theta2 + theta3 * x[i] - y[i]) / m) * x[i]
# 求损失函数J()
rand_i = random.randint(0,m)
diss = diss + (1 / (2 * m)) * pow((theta2 + theta3 * x[i] - y[i]), 2)
theta2_list.append(theta2 * 100)
theta3_list.append(theta3)
# 如果误差已经很小,则退出循环
if diss <= 0.001:
break
theta2 = theta2 * 100
print("批量梯度下降最终得到theta0={},theta1={}".format(theta0,theta1))
print("得到的回归函数是:y={}+{}*x".format(theta0,theta1))
print("随机梯度下降最终得到theta0={},theta1={}".format(theta2,theta3))
print("得到的回归函数是:y={}+{}*x".format(theta2,theta3))
#画原始数据和函数图
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(x0,y0,'bo',label='数据',color='black')
plt.plot(x0,[theta0+theta1*x for x in x0],label='批量梯度下降',color='red')
plt.plot(x0,[theta2+theta3*x for x in x0],label='随机梯度下降',color='blue')
plt.xlabel('x(面积)')
plt.ylabel('y(价格)')
plt.legend()
plt.show()
plt.scatter(range(count0),theta0_list,s=1)
plt.scatter(range(count0),theta1_list,s=1)
plt.xlabel('上方为theta0,下方为theta1')
plt.show()
plt.scatter(range(count0),theta2_list,s=3)
plt.scatter(range(count0),theta3_list,s=3)
plt.xlabel('上方为theta0,下方为theta1')
plt.show()
运行结果如下:

参考:https://blog.csdn.net/hcxddd/article/details/116396611?spm=1001.2014.3001.5501