Hadoop系列(二)——YARN总结
二、YARN–资源管理
1、Hadoop Yarn简介
Apache Hadoop YARN (Yet Another Resource Negotiator)
在古老的 Hadoop1.0 中,MapReduce 的 JobTracker 负责了太多的工作,包括资源调度,管理众多的 TaskTracker 等工作。这自然是不合理的,于是 Hadoop 在 1.0 到 2.0 的升级过程中,便将 JobTracker 的资源调度工作独立了出来,而这一改动,直接让 Hadoop 成为大数据中最稳固的那一块基石。,而这个独立出来的资源管理框架,就是 Yarn 。
在详细介绍 Yarn 之前,我们先简单聊聊 Yarn ,Yarn 的全称是 Yet Another Resource Negotiator,意思是“另一种资源调度器”,这种命名和“有间客栈”这种可谓是异曲同工之妙。这里多说一句,以前 Java 有一个项目编译工具,叫做 Ant,他的命名也是类似的,叫做 “Another Neat Tool”的缩写,翻译过来是”另一种整理工具“。
Yarn 是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。

如上图所示,MapReduce、Tez、HBase、Storm、Spark等等高层计算框架都是建立在YARN的基础上的。
YARN的好处:
- 提高集群利用率,资源统一管理,方便数据共享。
2、架构

我们主要围绕上面这张图展开,不过在介绍图中内容时,需要先了解 Yarn 中的 Container 的概念,然后会介绍图中一个个组件,最后看看提交一个程序的流程。
2.1 Container
Container:
- 封装了CPU、Memory等等资源的一个容器
- 是一个任务运行环境的抽象Maptask,Reducetask
- 在这里面运行
容器(Container)这个东西是 Yarn 对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn 对资源的管理也是用到了这种思想。

如上所示,Yarn 将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
- 容器由 NodeManager 启动和管理,并被它所监控。
- 容器被 ResourceManager 进行调度。
NodeManager 和 ResourceManager 这两个组件会在下面讲到。
2.2 三个主要组件
再看最上面的图,我们能直观发现的两个主要的组件是 ResourceManager 和 NodeManager ,但其实还有一个 ApplicationMaster 在图中没有直观显示。我们分别来看这三个组件。
(1)ResourceManager
- 整个集群同一时间提供服务的只有一个,负责集群资源的统一管理和调度。
- 处理客户端的请求,提交一个进程或杀死一个进程等。
- 监控我们的NodeManager,一旦某个NodeManager挂掉,那么该NM上运行的任务需要告诉我们的ApplicationMaster如何进行处理。
我们先来说说上图中最中央的那个 ResourceManager(RM)。从名字上我们就能知道这个组件是负责资源管理的,整个系统有且只有一个 RM ,来负责资源的调度。它也包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
- 定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当 Client 提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
- 应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理 Client 用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
(2)NodeManager
- 整个集群中有多个NM,负责自己本身节点的资源管理和使用
- 定时向ResourceManager汇报本节点的资源使用情况
- 接受并处理来自ResourceManager的各种命令
- 处理来自ApplicationManager的命令
- 单个节点的资源调度
NodeManager 是 ResourceManager 在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler 提供这些资源使用报告。
(3)ApplicationMaster
- 每个应用程序对应一个ApplicationMaster
- 为应用程序向ResourceManager申请资源(core、memory)分配给内部task
- 需要与NodeManager通信:启动、停止task,task是运行在container里面,AM也是运行在container里面的
- ApplicationMaster相当于RM和NM之间的中介,必须经过他进行调度,通过任意一个NodeManager启动,RM向他分配任务,AM分配给各个NM
每当 Client 提交一个 Application 时候,就会新建一个 ApplicationMaster 。由这个 ApplicationMaster 去与 ResourceManager 申请容器资源,获得资源后会**将要运行的程序发送到容器上启动,然后进行分布式计算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话山不过来,我就过去。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是**大数据分布式计算**的思路。
3、提交一个 Application 到 Yarn 的流程

这张图简单地标明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程。
- Client 向 Yarn 提交 Application,这里我们假设是一个 MapReduce 作业。
- ResourceManager 向 NodeManager 通信,为该 Application 分配第一个容器。并在这个容器中运行这个应用程序对应的 ApplicationMaster(只有一个,在第一个分配的容器中运行,负责向RM申请资源、启动停止NM中的任务)。
- ApplicationMaster 启动以后,对 作业(也就是 Application) 进行拆分,拆分 task 出来,这些 task 可以运行在一个或多个容器中。然后向 ResourceManager 申请要运行程序的容器,并定时向 ResourceManager 发送心跳。
- 申请到容器后,ApplicationMaster 会去和容器对应的 NodeManager 通信,而后将作业分发到对应的 NodeManager 中的容器去运行,这里会将拆分后的 MapReduce 进行分发,对应容器中运行的可能是 Map 任务,也可能是 Reduce 任务。
- 各个容器中运行的任务会向 ApplicationMaster 发送心跳,汇报自身情况。当程序运行完成后, ApplicationMaster 再向 ResourceManager 注销并释放容器资源。
以上就是一个作业的大体运行流程。
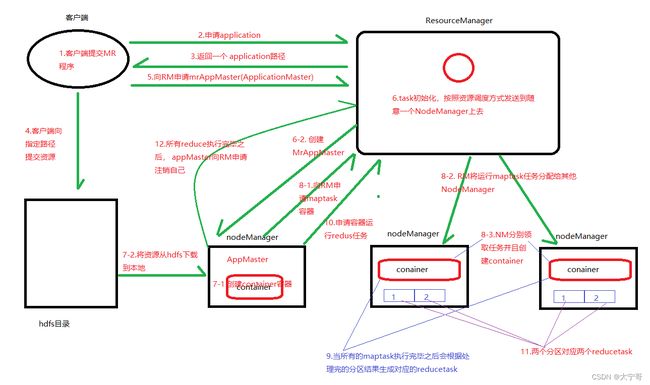
4、YARN运行机制:
- yarn并不清楚用户提交的程序的运行机制
- yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
- yarn中的主管角色叫ResourceManager
- yarn中具体提供运算资源的角色叫NodeManager
- yarn与运行的用户程序完全解耦,意味着yarn上可以运行各种类型的分布式运算程序,比如mapreduce、storm,spark,tez……等运算框架都可以整合在yarn上运行,只要他们各自的框架中有符合yarn规范的资源请求机制即可。
- yarn成为一个通用的资源调度平台。企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享。
Hadoop(hdfs, yarn, mapreduce)理论详解_大宁哥的博客-CSDN博客
HDFS读写流程(史上最精炼详细)_bw_233的博客-CSDN博客_hdfs 读取
HDFS读写数据流程 - CoderZZZ - 博客园 (cnblogs.com)
深入浅出 Hadoop YARN - 知乎 (zhihu.com)
hadoop之mapreduce详解(基础篇) - 一寸HUI - 博客园 (cnblogs.com)
Hadoop生态之Mapreduce_小滴杂货铺的博客-CSDN博客
Hadoop中的MapReduce是什么?体系结构|例 (guru99.com)
MapReduce shuffle过程详解!_<一蓑烟雨任平生>的博客-CSDN博客_mapreduce shuffle过程详解
MapReduce shuffle过程详解_xidianycy的博客-CSDN博客_mapreduce shuffle