【笔记】动手学深度学习 - pytorch神经网络基础
介绍
为了实现复杂的网络,我们引入了神经网络块的概念。块可以描述单个层、由多个层组成的组件或整个模型本身。
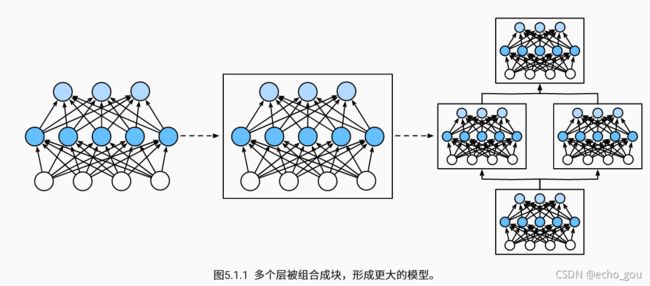
从编程的角度来看,块由类(class)表示。它的任何子类都必须定义一个将其输入转换为输出的正向传播函数(forward),并且必须存储任何必需的参数。注意,有些块不需要任何参数。
最后,为了计算梯度,块必须具有反向传播函数。幸运的是,在定义我们自己的块时,由于自动微分(在 2.5节 中引入)提供了一些后端实现,我们只需要考虑正向传播函数和必需的参数。
首先,我们回顾一下多层感知机的代码。下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接的隐藏层,然后是一个具有10个隐藏单元且不带激活函数的全连接的输出层。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)
在这个例子中,我们通过实例化nn.Sequential来构建我们的模型,层的执行顺序是作为参数传递的。简而言之,nn.Sequential定义了一种特殊的Module,即在PyTorch中表示一个块的类。
正向传播(forward)函数也非常简单:它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。注意,到目前为止,我们一直在通过net(X)调用我们的模型来获得模型的输出。这实际上是net.__call__(X)的简写。
自定义块
首先自定义块一定是继承Module的。其次必须要有__init__()和forward()方法分别用来说明网络的组成和如何前向传播。
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
def forward(self): 接下来加上层:
关于__init__()
关于forward的理解:
首先将x作为输入传入linear的hidden层中(相当于是pw+b操作),得到了n_hidden大小的输出,再将这个输出传入relu激活函数中,得到隐藏层的输出。然后将x传入预测函数得到loss值。
class Net(torch.nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden=torch.nn.Linear(n_feature,n_hidden) #可以大致理解为声明一个hidden变量,变量类型是Linear
self.predict=torch.nn.Linear(n_hidden,n_output) #输出的那层
def forward(self,x):
x=F.relu(self.hidden(x))
x=self.predict(x) #预测层一般都是输出,一般都是loss函数来进行计算,并不需要激活函数
return x
net=Net(1,10,1)
这样就搭建好了一个简单的网络
我们可以输出这个网络看看
print(net)
然后是优化函数和训练
optimizer = torch.optim.SGD(net.parameters(),lr=0.5)
loss_func=torch.nn.MSELoss()
for t in range(100): #训练100次
prediction=net(x)
loss=loss_func(prediction,y)#prediction在前
optimizer.zero_grad() #所有参数梯度降为0
loss.backward() #反向传播,计算梯度
optimizer.step() #以0.5lr来优化参数管理
首先建立一个简单的网络:
import torch
from torch import nn
net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1))
x=torch.rand(size=(2,4))relu层没有参数
print(net(x))
print(net[2].state_dict()) #net[0-2]分别是nn.Linear(4,8),nn.ReLU(),nn.Linear(8,1)
print(type(net[2].bias)) #输出类型
print(net[2].bias) #访问bias偏置
print(net[2].weight.grad) #梯度为None
一次性访问所有参数(不懂)
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])
![]()
从嵌套块收集参数:
def block1():
return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),
nn.Linear(8, 4), nn.ReLU())
def block2():
net = nn.Sequential()
for i in range(4):
# 在这里嵌套
net.add_module(f'block {i}', block1())
return net
rgnet = nn.Sequential(block2(), nn.Linear(4, 1))
rgnet(X)
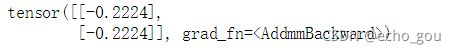
可以通过打印网络来看出网络的简单结构
print(rgnet)

内置初始化:
自定义层:
和自定义网络区别不大,因为都是module的子类
关于nn.init()
下面的代码将所有权重参数初始化为标准差为0.01的高斯随机变量,且将偏置参数设置为0。
def init_normal(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.zeros_(m.bias)
net.apply(init_normal)
net[0].weight.data[0], net[0].bias.data[0]
![]()
我们还可以将所有参数初始化为给定的常数,比如初始化为1
def init_constant(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight, 1)
nn.init.zeros_(m.bias)
net.apply(init_constant)
net[0].weight.data[0], net[0].bias.data[0]
我们还可以对某些块应用不同的初始化方法。例如,下面我们使用Xavier初始化方法初始化第一层,然后第二层初始化为常量值42。
def xavier(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
def init_42(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight, 42)
net[0].apply(xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)

读写文件
import torch
from torch import nn
from torch.nn import functional as F
x=torch.arange(4)
torch.save(x,'x-file')
x2=torch.load("x-file")
x2![]()
可以发现文件保存在了当前环境下的文件夹里。
也可存储一个张量列表:
y = torch.zeros(4)
torch.save([x, y],'x-files')
x2, y2 = torch.load('x-files')
(x2, y2)
![]()
或者字典映射
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
mydict2![]()
加载和保存模型的参数信息
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256)
self.output = nn.Linear(256, 10)
def forward(self, x):
return self.output(F.relu(self.hidden(x)))
net = MLP()
X = torch.randn(size=(2, 20))
Y = net(X)
torch.save(net.state_dict(), 'mlp.params') #保存net的参数信息(state_dict())
clone = MLP()
clone.load_state_dict(torch.load('mlp.params'))
clone.eval()