还不懂目标检测嘛?一起来看看Faster R-CNN源码解读
作者简介:秃头小苏,致力于用最通俗的语言描述问题
往期回顾:目标检测系列——开山之作RCNN原理详解 目标检测系列——Fast R-CNN原理详解 目标检测系列——Faster R-CNN原理详解
近期目标:拥有10000粉丝
支持小苏:点赞、收藏⭐、留言
文章目录
-
- Faster R-CNN源码解读
- 写在前面
- 源码解读
-
- split_data.py文件
- my_dataset.py
- transform.py✨✨✨
- rpn_function.py✨✨✨
- roi.head.py✨✨✨
- 小结
- 总结
Faster R-CNN源码解读
写在前面
这部分同样参考霹雳吧啦Wz的视频,Faster R-CNN代码链接如下:Faster R-CNN源码 先说说这篇文章该怎么用吧?——我觉得最好是这样,你先看看霹雳吧啦Wz对Faster R-CNN代码的解读,自己先理解理解,之后如果有什么不懂的再来这篇文章看能否找到你想要的答案;或者你已经基本弄明白了代码,那么可以将此篇文章当成一个速查手册。其实用视频和文字来表述问题是各有优劣的,看一段视频无疑会让你快速掌握一个知识点,视频中对某些问题的描述可能也会更清晰,让听者很直观感受到自己能力的提高;而读一篇文章则会让读者有更多的时间去思考,去理解,会形成自己的思绪。【注:写着写着发现代码解析有的部分确实难以用文字描述,故阅读此篇文章前务请大家必要先看看视频,这样才更好理解】
在阅读源码之前,你还需要对Faster R-CNN的原理较为清晰,我之前也做过从R-CNN、Fast R-CNN以及Faster R-CNN的原理讲解,对原理不清楚的请移步参考,链接如下:
- R-CNN
- Fast R-CNN
- Faster R-CNN
源码解读
我们先来看看我们代码的整体结构,如下:

接下来我们会对文件中相关代码进行解读。【注:不可能对每行代码讲解的都非常详细,只会重点谈谈一些关键的代码】
split_data.py文件
该文件是用来划分数据集的,即若我们拿到一个数据,将数据集划分成验证集和训练集。下面我们来简要的看看代码:
- 首先,输入数据的存储路径并设置验证集训练集划分比例
files_path = "./VOCdevkit/VOC2012/Annotations"
val_rate = 0.5
-
获取
"./VOCdevkit/VOC2012/Annotations"文件夹下所有.xml文件并去xml文件名前面的序号进行排序存储在files_name中files_name = sorted([file.split(".")[0] for file in os.listdir(files_path)]) files_num = len(files_name) -
随机选取验证集索引
val_index = random.sample(range(0, files_num), k=int(files_num*val_rate)) -
进行划分并保存
for index, file_name in enumerate(files_name): if index in val_index: val_files.append(file_name) else: train_files.append(file_name) try: train_f = open("train.txt", "x") eval_f = open("val.txt", "x") train_f.write("\n".join(train_files)) eval_f.write("\n".join(val_files)) except FileExistsError as e: print(e) exit(1)
最终会生成train.txt和val.txt文件。

my_dataset.py
在上节描述代码时,我想要考虑到一个文件的完整性,想要尽可能全的把一个py文件的内容都描述进来,但我感觉这样做是很难的,也抓不住重点,效果好像并不好。因此后面我只会对我认为一些较难理解或比较重要的点进行描述。
-
初始化,主要获取一些数据集的路径,还是非常好理解的
def __init__(self, voc_root, year="2012", transforms=None, txt_name: str = "train.txt"): assert year in ["2007", "2012"], "year must be in ['2007', '2012']" self.root = os.path.join(voc_root, "VOCdevkit", f"VOC{year}") self.img_root = os.path.join(self.root, "JPEGImages") self.annotations_root = os.path.join(self.root, "Annotations") # read train.txt or val.txt file txt_path = os.path.join(self.root, "ImageSets", "Main", txt_name) assert os.path.exists(txt_path), "not found {} file.".format(txt_name) with open(txt_path) as read: self.xml_list = [os.path.join(self.annotations_root, line.strip() + ".xml") for line in read.readlines() if len(line.strip()) > 0] # check file assert len(self.xml_list) > 0, "in '{}' file does not find any information.".format(txt_path) for xml_path in self.xml_list: assert os.path.exists(xml_path), "not found '{}' file.".format(xml_path) # read class_indict json_file = './pascal_voc_classes.json' assert os.path.exists(json_file), "{} file not exist.".format(json_file) json_file = open(json_file, 'r') self.class_dict = json.load(json_file) json_file.close() self.transforms = transforms -
将xml文件变换成字典格式
xml_path = self.xml_list[idx] with open(xml_path) as fid: xml_str = fid.read() xml = etree.fromstring(xml_str) data = self.parse_xml_to_dict(xml)["annotation"] img_path = os.path.join(self.img_root, data["filename"]) image = Image.open(img_path)
我们可以重点关注一下parse_xml_to_dict方法,该方法会递归遍历xml文件,将其转换成一个字典,我们可以设置断点看看data中的数据,如下图所示:

-
目标检测transforms后bbox位置需要改变
class RandomHorizontalFlip(object): """随机水平翻转图像以及bboxes""" def __init__(self, prob=0.5): self.prob = prob def __call__(self, image, target): if random.random() < self.prob: height, width = image.shape[-2:] image = image.flip(-1) # 水平翻转图片 bbox = target["boxes"] # bbox: xmin, ymin, xmax, ymax bbox[:, [0, 2]] = width - bbox[:, [2, 0]] # 翻转对应bbox坐标信息 target["boxes"] = bbox return image, target
使用的是水平翻转,翻转后的图和原图关系如下,我们可以看到翻转后图像的bbox左上角横坐标应为 图像宽度- X m a x X_{max} Xmax,bbox右下角横坐标为图像宽度- x m i n x_{min} xmin。bbox的纵坐标没有变化。

transform.py✨✨✨
我们先来看看前文得到了什么,从前面两个py文件的介绍中可知,我们主要就是构建了我们的数据集,即有了图像数据image和和标注信息target。那么这个transform.py文件的作用就是将图像数据和标注信息进行标准化等一系列处理,使数据输入到网络中具有相同的形式。
这里我想先介绍对原始的数据都做了哪些操作,然后再贴出代码,这样或许就好理解了。首先我们现在有了一堆图片数据和对应的target信息。【注意:target最主要是对里面的bbox进行一些调整】 那么接下来我们需要做什么呢,首先我们会对图片进行标准化处理,这部分代码也很简单啦,如下:

需要注意的是mean和std我们采用的是IMagenet数据集的均值和方差。
做好标准化后我们需要将图片缩放到统一尺寸,还记得我们在R-CNN理论部分是怎么进行缩放的嘛?是的,R-CNN中我们进行了强制缩放到统一大小,很明显这样的效果是不理想的,我们来看看代码中采用的是什么方法。首先我们设置一个最大边长和最小边长,假设最大边长为1000,最小边长为500。对于一张尺寸为250*400的图片,我们先将图片短边缩放到500,然后计算出缩放比例为500/250=2,那么这时再将图片长边乘缩放比例即400*2=800,也即resize后图像尺寸变成了500*800。大致过程如下图所示:

上述过程的相关代码如下:这样resize不会让图片产生畸变。

我们知道一个batch会有多张图片,且这些图片的尺寸需要相同。很明显通过上文resize操作得到的图片尺寸是不一致的,无法打包成一个batch。这该怎么办呢,其实也很简单,比如我们一个batch有8张图片,那么我们先找出这一个batch中所有图片的最大的高和宽,比如最大高为1000,最大宽为2000,先创建出一个像素都是0的1000*2000大小图像,然后将8张图片都填入进行。可以结合下图进行理解:

上述过程相关代码如下:

这时候我们已经能够把数据打包成一个个batch,这样就可以作为网络的输入了。但是这里还有一个细节不能忘掉喔,就是我们在缩放图片尺寸的时候,我们也需要对图片中的bbox进行相应的缩放,这很好理解,图片小了,图片中的物体当然也小啦,这部分的代码如下:

好了,这部分就介绍到这里了,其实代码中还是有很多细节滴,大家可以调试看看每步的结果。【注:调试时应该将断点设置在transform.py文件中,而调试运行的是train_res50_fpn.py文件】
rpn_function.py✨✨✨
同样的,我们先来看看我们前文得到了什么。经过transform.py的操作,我们已经打包好了一组组的图片,这样就可以输入Backbone网络中得到对应的特征图了,即现在我们已经有了特征图。【注:特征提取这部分我不在介绍,很简单】下面就要进行RPN层了,这一部分非常重要,所以篇幅可能有点长,还请耐心阅读。
首先我们来看看RPN部分的结构图,如下:

先来看看RPNHead部分,这部分就非常简单啦,主要就是一些卷积的操作,代码如下:
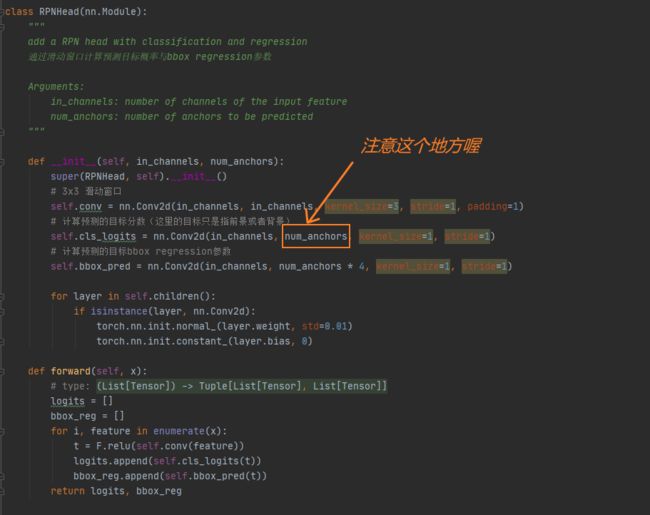
代码中值得注意的地方就只有上图黄框部分,在我们的Faster R-CNN的原理讲解中,我们说分类时输出通道数为anchors(num_anchors)的2倍,那么这里应该是num_anchors*2,但是代码中没有乘2,这是什么原因呢?其实呀,这是由于使用损失函数的差异导致的,一个使用的是多分类交叉熵损失,一个使用的是二值交叉熵损失,这部分的相关介绍可观看视频 第20分钟了解详情。
接下来再来看看AnchorsGenerator部分,这部分的作用是用来在原图上生成一系列anchors的。首先是初始化,这部分主要设置了生成anchors的尺寸和比例。需要注意的是,在Faster R-CNN论文中我们仅仅设置了三种尺寸和三种比例一共9种anchors;而在这部分代码中,我们传入了五种尺寸三种比例一共15中anchors。可以看到主要是增加32*32和64*64这两类尺寸anchors,这样的好处是什么呢?很容易想到,这样会对图片中小物体的检测更加有效,当然这样做的代价就是计算量变大啦。

接着我们再来看看正向传播过程,如下图,这里将会重点谈谈黄框和篮框中的内容。

黄框部分是根据尺寸(size)和高宽比(aspect_ratios)生成15个anchors模板。我们进入函数内部来看看是怎么实现的。

其实最主要的是上图的右半部分,首先我们由高宽比(aspect_ratios)来求出比列因子,即h_ratios和w_ratios,计算公式如下:【注:为什么采用这个公式计算出比列因子我也不清楚,可能是某些数学上的问题吧。因为我们可以从最后生成的anchors结果可以发现,这样的比列因子可以产生5种尺度三种比列的anchors】
h_ratios = torch.sqrt(aspect_ratios)
w_ratios = 1.0 / h_ratios
那么下面就来验证一下上文注解中的表述,看看我们最后的anchors是否是5种尺度三种比列的。先来看看h_ratios、w_ratios和scales的值:

有了这些值之后,执行下面的代码:
ws = (w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h_ratios[:, None] * scales[None, :]).view(-1)
这部分代码是做什么的呢,其实就是做了一个矩阵乘法,其中w_ratios[:, None]可理解为把w_ratios变成了行向量,scales[None, :]可理解为把scales变成了列向量。接下来就是将这两个向量相乘,如下图所示:

乘完后进行展平得到输出ws,其值如下:
![]()
同理,可以得到hs:
![]()
最后生成模板,以(0,0)为中心,代码如下:
base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2
最终生成的base_anchors值如下:可以看到共有15组值,即生成了15个anchors。
下面简单分析一下以上数据,看看是否满足5种尺度三种比列,如下:
从上图可以看出结果base_anchors满足上述所说条件。
接着我们再来讲讲正向传播蓝框中的内容:这部分主要是将每张预测特征图映射回原图得到anchors坐标信息。
先来描述一下这部分的大致过程,我们首先会计算出所有anchors在原图上的偏移量,然后再和anchors模板进行结合。最后的大致过程如下。
总之,通过这一步我们在原图上会生成非常多的anchors,来看一下我们在一张图片上生成了14250个anchor。
![]()
至此,我们已经由RPNHead部分得到了分类和回归结果,由AnchorsGenerator部分得到了一系列anchors。接下来我们要做的就是结合这两部的结果来生成候选框(proposals),并对候选框进行过滤筛选,得到符合条件的候选框。

先来看看如何由RPNHead生成的边界框回归参数和AnchorsGenerator产生的anchors得到新的proposal,即利用边界框回归参数对anchors进行微调。其实这部分很好理解,我之前在R-CNN中有讲过如何由回归参数和anchors得到预测的候选框的公式,如下图所示:

需要注意的是,上图是针对R-CNN边界框的调整,这里是针对RPN网络的边界框调整,其实公式是一致的。有了这个公式,我们来看看代码就很好理解了。

在上述代码中,我们得到了修改后边界框中心点的坐标和高度及宽度,之后我们还需要将其变换乘边界框的左上和右下点的坐标,代码如下:

接下来就要对得到的候选框进行相应的过滤了。首先我们会根据RPNHead得到的物体预测分数进行排序,选取预测概率排前的anchors,代码中选取了2000。

然后通过切片的方式选取候选框,进行完这步后,每张图片的候选框就只剩2000个了。
![]()
之后又会进行一系列操作来过滤候选框,如调整越界边界框的坐标、删除宽度高度小的候选框和删除小概率的边界框及NMS操作等等。

经过这些操作后,可以发现每张图片的候选框个数又少了,如图:【注:下图只展示了一张图片的候选框个数,即1747个】
![]()
最后我们来简单谈谈在训练过程中RPN网络的损失计算。大致过程如下图所示,会利用AnchorsGenerator生成的anchors以及标注信息targets信息计算分类损失和回归损失。

这部分我建议大家还是观看视频进行学习,特别是在计算anchors于哪个gt (ground truth)最匹配时,视频中写有例子,表述的非常清楚。这里我就总结一下计算loss的步骤:
- 计算每个anchors最匹配的gt,并将anchors进行分类,前景,背景以及废弃的anchors
- 结合anchors以及对应的gt,计算regression参数
- 根据预测的概率(objectness)、预测的bbox regression(pred_bbox_deltas)、真实的标签(labels)和真实的bbox regression(regression_targets)计算分类损失和回归损失
- 将分类损失和回归损失存储在字典中
相关代码如下:

roi.head.py✨✨✨
通过上一节我们已经把rpn网络讲完啦,大家学的怎么样呢?这里我还是要强调一下,大家看我推荐的视频或者这篇文章其实都是不够的,视频是带你入门,文章是帮你整理思路,进行总结,你更多的时间应该还是花在代码的调试上。谈到调试,我这里再多说一嘴,就是我在调试train_mobilenetv2.py脚本时,总是会出现调试中断的情况,大家若出现和我一样的情况,可以试试train_res50_fpn.py脚本,调试这个脚本目前没有遇到这种情况,但是这个脚本会稍微慢一点,可以适当缩小batch_size进行调试。
下面就来介绍roi.head部分,这部分包括下图中的结构,这么一看,会感觉这部分也太多了。但是呢,这部分其实都比较好理解,而且很多内容都和RPN层非常的相似,就让我们一起来看看吧。

首先,我们由上一步RPN网络提取到了很多候选框,但是这些候选框我们并不是都用于FastRCNN的训练,而是先会删选一定数量的候选框进行训练,代码如下:

我就不带大家进入函数内部一行行看了,这个和RPN中正负样本的选取非常类似,我们可以来看一下运行完这行前后poposals的变化,如下图所示:执行完这句后每张图片的poposals数量由2000变成了512,即每张图片选取了512个候选框用来训练fastRCNN。

接着我们会利用所选取的候选框和backbone提取到的特征图,得到每个候选框对应于特征图的部分,然后分别送入ROIpooling层。
代码如下:
同样的,我也只会提供执行此条语句特征图的变化,如下图所示:可以看到这个生成的box_feature的size为(1024,256,7,7)。我来解释一下这个维度代表的含义:1024表示有1024个候选框,我们在上一步划分正负样本时每张图片选取了512个候选框,batch_size设置为2,512*2=1024。256为通道数,(7,7)表示生成特征图的高和宽。

继续来看图5.1,现在我们需要将上一步得到的box_feature送入Two MLPHead,这部分就更简单了,就是两个全连接层,代码如下:

执行此代码后特征图的尺寸变化如下:第一个1024表示1024个候选框,第二个1024表示全连接层的输出节点个数为1024。
![]()
经Two MLPHead层后,会分别计算预测目标类别和回归参数,相关代码如下:
这部分也就是并行进入了两个全连接层,需要注意分类结果=num_classes,回归结果输出结果个数=num_classes\*4【在voc数据集中num_classes=21,包括1个背景和20个前景】
这部分最后一部分是分类和回归损失的计算,代码如下:【注:训练模式计算损失,预测给出框的位置标签以及分数,即对应图5.1中的postprocess_detections】

通过前文叙述,我们的Faster R-CNN基本完成了。但是在预测过程中,我们目前得到的边界框参数还是我们图片经过resize后的数值,因此我们想要在原图上显示边界框还需要还原到原图像尺寸上,相关代码如下:【注意:这部分要调试的话需要调试的是predict.py脚本】

小结
Faster RCNN的源码至此就全部讲完了,希望大家都能够有所收获吧
这里我再简单的说一下如何训练自己的数据集。确实也非常简单,首先我们得有图片文件和标注文件,然后分别放入JPEGImages和Annotations文件,如下图所示:

接下来我们需要在pascal_voc_classes.json中将要识别的物体种类换成自己的。

最后我们执行split_data.py文件划分训练集和验证集,此时会在faster_rcnn文件夹下生成train.txt文件和val.txt文件,此外我们需要复制这两个文件到faster_rcnn\VOCdevkit\VOC2012\ImageSets\Main文件夹下。

上面的工作做完,就可以开始训练了,如运行train_res50_fpn.py脚本。有需要的大家快去试试吧!!!
【注:上述的这种方式是直接把自己的数据集放到VOC数据集的文件夹中,这样就不需要另外修改代码。如果大家不想这样做,那么就自己定义自己的数据集目录结构,但是这样需要对代码的路径做相应的修改。】
总结
如果大家都能够看到最后,不管是视频或者文章,都应该给自己鼓个掌目标检测的代码真的不是和物体分类一个量级,但是应用场景更加广泛。之前看唐宇迪博士的视频,他就说过,他招的新人要求一个月啥也不干,就啃RCNN的三个系列,足以见其重要性。其实对于代码中的很多点自己也还不是很清楚,所以说还是得时常回来啃一啃,补充补充能量。最后的最后,送给大家我最近看到的一句鸡汤:你所做的一切并不会立即给你想要的一切,但可以让你逐渐成为你想成为的那一种人望共勉!!!
如若文章对你有所帮助,那就
咻咻咻咻~~duang~~点个赞呗