vue+flask制作一个网易严选商品评论爬虫可视化系统
文章目录
-
- 1、数据获取
-
- 1.1爬取评论信息
- 1.2 爬取评论标签
- 2、数据保存策略
- 3、数据处理
-
- 3.1 基于情感词典进行情感分析,词频统计
- 4、数据可视化
-
- 4.1 TOP积极词汇
- 4.2 TOP消极词汇
- 4.3 词云图
- 4.4 评论类型占比
- 4.5界面快速访问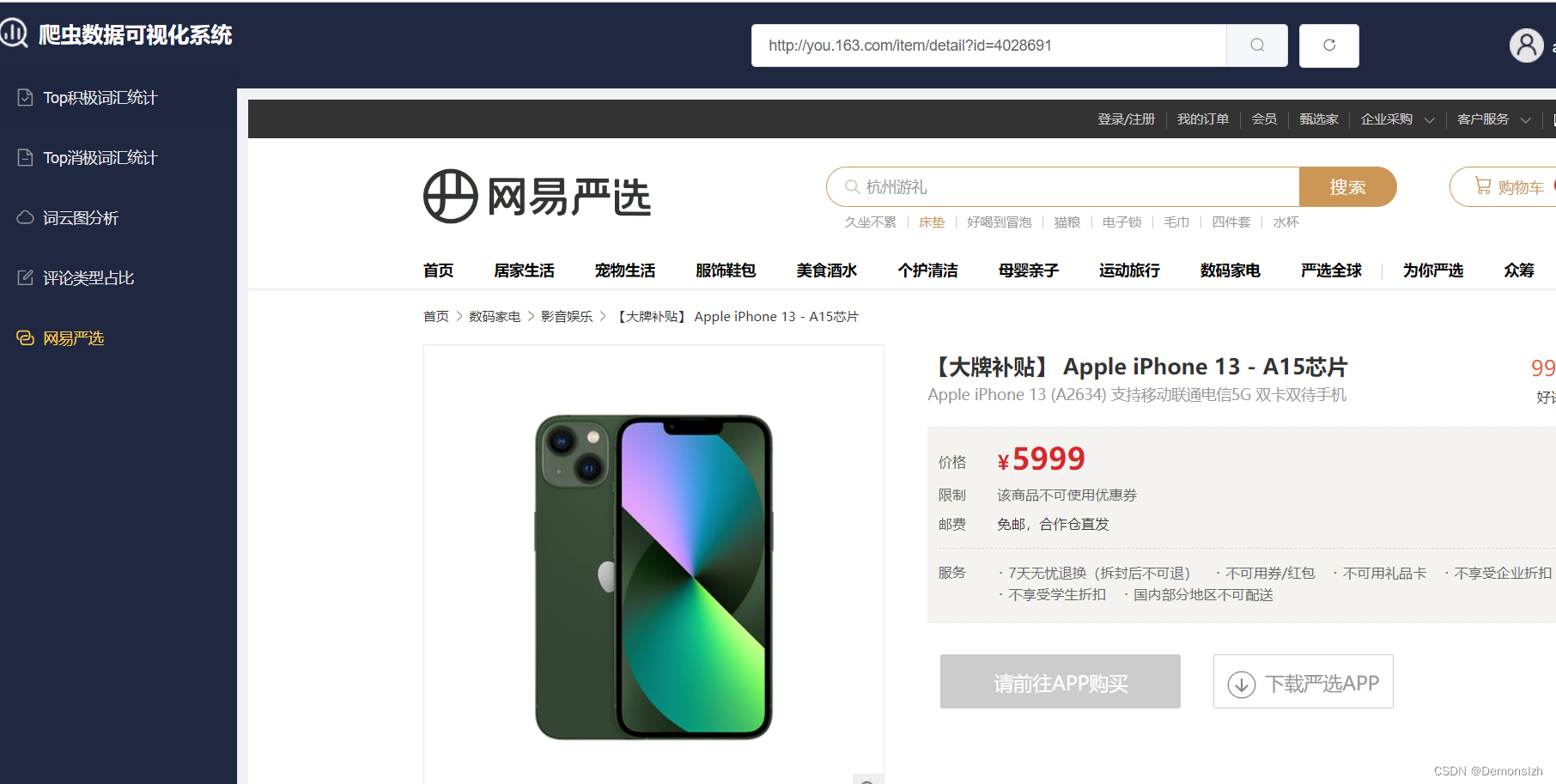
- 5、编写flask后端接口
- 6、vue界面
- 7、源码获取
之前有粉丝私信希望帮忙做一个爬虫可视化系统,能够爬取商品评论信息以及可视化展示。这里就分享下这个项目的具体思路以及完整代码。
1、数据获取
我们决定爬取的是网易严选的数据,严选的商品评论数据可以直接通过api去获取。
第一步就是获取评论数据了,直接通过如下接口就可以爬取。
api如下 https://you.163.com/xhr/comment/listByItemByTag.json?__timestamp={}&itemId={}&size=20&page={}&orderBy=0
由此看到我们需要着重关注的参数是界面访问链接中的id作为我们数据接口的itemid进行传参

1.1爬取评论信息
下面展示的功能函数中的username是我们可视化系统的用户名,并不是构造爬取请求所必须的。
def parse_comments(username, product_id, page_limit=20):
"""
爬取评论数据
username: 用户名
product_id: 产品名称
page_limit: 爬取页数,这里默认最大设置为20
"""
comments_url = "https://you.163.com/xhr/comment/listByItemByTag.json?__timestamp={}&itemId={}&size=20&page={}&orderBy=0".format(
time.time() * 1000, product_id, 1)
res = requests.get(comments_url, headers=headers).json()
if res:
pages = res.get("data", {}).get("pagination", {}).get("totalPage", 1)
# 我们这里最多只爬取page_limit页,一次爬多容易触发反爬虫机制
pages = pages if pages <= page_limit else page_limit
for page in range(1, pages + 1):
comments_url = "https://you.163.com/xhr/comment/listByItemByTag.json?__timestamp={}&itemId={}&size=20&page={}&orderBy=0".format(
time.time() * 1000, product_id, page)
res = requests.get(comments_url, headers=headers).json()
for item in res.get("data", {}).get("commentList", []):
try:
comment = item.get("content", "")
update_time = item.get("createTime", -1)
sql = """insert into tb_comments(username,url,product_id,comment,update_time)
values ('{}','{}','{}','{}',{});""".format(username,comments_url,product_id, comment, update_time)
dbutil().insert(sql)
except Exception as e:
traceback.print_exc(e)
1.2 爬取评论标签
此外,在评论界面可以看到评论标签,把这部分数据获取后用以做扇形图的可视化

2、数据保存策略
为了避免数据的反复爬取,后台会将每次爬取的数据保存在数据库,每次搜索是根据id匹配,当数据库查询不到对应的数据,再进行实时爬取。

3、数据处理
数据获取之后我们需要对评论数据进行清洗。依次进行去停用词、再通过jieba进行分词。

3.1 基于情感词典进行情感分析,词频统计
分词完成后,这里我是使用的BosonNLP_sentiment_score.txt作为情感词典进行的评分。如果在情感词典中不存在的词汇,默认赋值为0。
对所有的词语评分完成后,根据评分降序排序。那么结果列表中的前10个值则作为我们的TOP10积极词汇。列表中的最后10个词语自然而然地就是我们TOP10的消极词汇了。
def get_top_positive_negative_frequency(data, top=10):
"""
获取top n个消极词汇与积极词汇以及词频
:param data: 评论数据
:param top:
:return:
"""
senti_dict = sentiment_dict(os.path.join(os.path.abspath("."),'text_analysis\\BosonNLP_sentiment_score.txt'))
content_seg = movestopwords(data["comments"])
scores = {}
frequency = {}
for word in content_seg:
scores[word] = senti_dict.get(word, 0)
if frequency.get(word):
frequency[word] += 1
else:
frequency[word] = 1
scores = sorted(scores.items(), key=lambda x: x[1], reverse=True)
frequency = dict(sorted(frequency.items(), key=lambda x: x[1], reverse=True))
positive = dict(scores[0:top])
negative = dict(scores[-top:])
return {
"positive": positive,
"negative": negative,
"frequency": frequency
}
4、数据可视化
数据可视化使用echarts,具体的可视化效果如下
4.1 TOP积极词汇

4.2 TOP消极词汇

4.3 词云图

4.4 评论类型占比

4.5界面快速访问
5、编写flask后端接口
由于界面的接口相对较少,一共三个接口,分别为登录login、注册regist和数据获取display。
数据获取接口每次根据url获取商品id,获得数据后进行实时处理,完毕返回给前端展示。具体逻辑如下
# encoding:utf-8
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from text_analysis.code import get_top_positive_negative_frequency
from utils import get_data,get_db_config
app = Flask(__name__)
# 连接数据库
config = get_db_config()
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://{}:{}@{}:3306/{}'.format(config["user"],config["password"],config["host"],config["database"])
# 实例化orm框架的操作对象,后续数据库操作,都要基于操作对象来完成
db = SQLAlchemy(app)
# 声明模型类
class User(db.Model):
__tablename__ = "tb_user" # 设置表名
id = db.Column(db.INTEGER, primary_key=True)
username = db.Column(db.String(16), nullable=False)
password = db.Column(db.String(16), nullable=False)
@app.route('/')
def hello_world():
return 'Hello World!'
@app.route("/login", methods=["post"])
def login():
"""登录"""
code, msg = 200, "success"
username = request.json.get("username")
password = request.json.get("password")
if not username or not password:
code, msg = 500, "用户名或者密码不能为空"
if not User.query.filter_by(username=username, password=password).first():
code, msg = 500, "密码错误"
return jsonify({"msg": msg, "code": code})
@app.route("/regist", methods=["post"])
def regist():
"""注册"""
code, msg = 200, "success"
username = request.json.get("username")
password = request.json.get("password")
if username and password:
if User.query.filter_by(username=username).first():
msg = "用户%s已存在" % username
else:
new_user = User(username=username, password=password)
db.session.add(new_user)
db.session.commit()
return jsonify({"msg": msg, "code": code})
@app.route("/display", methods=["post"])
def display():
"""
获取绘图数据
:return:
"""
code, msg = 200, "success"
url = request.json.get("url","http://you.163.com/item/detail?id=4028691")
username = request.json.get("username")
top = request.json.get("top", 10)
product_id = url.split('id=')[-1] if url.split('id=') else url
data = get_data(username, product_id)
data.update(get_top_positive_negative_frequency(data, top))
data.pop("comments")
return jsonify({"msg": msg, "code": code, "data": data})
if __name__ == '__main__':
db.create_all()
app.run(host="0.0.0.0")
6、vue界面
vue源码放在项目static目录下。
主要分为登录界面和数据展示界面。

7、源码获取
获取源码请在微信公众号搜索一颗程序树关注后发送关键字0100获取代码下载地址。