Hive Metastore详解大全
1、介绍
Hive所有表和分区的元数据都通过Hive Metastore进行访问。使用JPOX ORM解决方案(Data Nucleus)持久化元数据,因此它支持的任何数据库都可以被Hive使用。它支持大多数商业关系数据库和许多开放源码数据库。请参阅下面一节中支持的数据库列表。
Hive Metastore库里的表之间的拓扑关系图如下:
有2种不同的方法来设置metastore服务器和metastore数据库使用不同的Hive配置:
简单来讲就是使用本地的Derby模式的
使用远程的数据库
1.1、基本配置参数
相关配置参数如下所示。非metastore参数请参见配置Hive。也请参阅语言手册的Hive配置属性,包括Metastore和Hive Metastore安全。)
请参见配置Hive下的hivemetstore -site.xml文档。
| Configuration Parameter |
Description |
| javax.jdo.option.ConnectionURL |
用于包含元数据的数据存储的JDBC连接字符串 |
| javax.jdo.option.ConnectionDriverName |
包含元数据的数据存储的JDBC驱动程序类名 |
| hive.metastore.uris |
Hive连接到这些uri中的一个,向远端Metastore(以逗号分隔的uri列表)发送元数据请求。 |
| hive.metastore.local |
本地或远端metastore(从Hive 0.10移除:如果Hive .metastore.uri为空,则假设本地模式为远端模式) |
| hive.metastore.warehouse.dir |
本机表的默认位置的URI |
Hive metastore是无状态的,因此可以有多个实例来实现高可用性。使用hive.metastore.uri可以指定多个远程元数据连接。Hive会默认使用列表中的第一个,但会在连接失败时随机选择一个,并尝试重新连接。
1.2、其他配置参数
以下metastore配置参数是从旧文档中继承下来的,没有保证它们仍然存在。Hive当前的配置选项请参见HiveConf Java类,Metastore和Hive Metastore安全部分的语言手册的Hive配置属性的用户友好的描述Metastore参数。
| Configuration Parameter |
Description |
Default Value |
| hive.metastore.metadb.dir |
文件存储元数据基目录的位置。(在0.4.0中HIVE-143删除了该功能。) |
|
| hive.metastore.rawstore.impl |
实现org.apache.hadoop.hive.metastore.rawstore接口的类名。该类用于存储和检索原始元数据对象,如表、数据库。(Hive 0.8.1及以上版本) |
|
| org.jpox.autoCreateSchema |
如果模式不存在,则在启动时创建必要的模式。(模式包括表、列等等。)创建一次后设置为false。 |
|
| org.jpox.fixedDatastore |
数据存储模式是否固定。 |
|
| datanucleus.autoStartMechanism |
是否在启动时初始化。 |
|
| hive.metastore.ds.connection.url.hook |
用于检索JDO连接URL的钩子的名称。如果为空,则使用javax.jdo.option.ConnectionURL中的值作为连接URL。(Hive 0.6及以上版本) |
|
| hive.metastore.ds.retry.attempts |
如果出现连接错误,重试调用备份数据存储的次数。 (Hive 0.6到0.12;在0.13.0中移除-使用hive.hmshandler.retry.attempts代替。) |
1 |
| hive.metastore.ds.retry.interval |
数据存储重试之间的毫秒数。 (Hive 0.6到0.12;在0.13.0中移除-请改用hive.hmshandler.retry.interval。) |
1000 |
| hive.metastore.server.min.threads |
Thrift服务器池中工作线程的最小数量。 (Hive 0.6及以上版本) |
200 |
| hive.metastore.server.max.threads |
Thrift服务器池中的最大工作线程数。 (Hive 0.6及以上版本) |
100000 since Hive 0.8.1 |
| hive.metastore.filter.hook |
Metastore钩子类,用于在客户端进一步过滤元数据读取结果。 (Hive 1.1.0及以上版本) |
org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl |
| hive.metastore.port |
Hive metastore监听端口。 (Hive 1.3.0及以上版本) |
9083 |
1.3、数据中心自动启动
配置datanucleus。强烈推荐使用autoStartMechanism,强烈建议为数据中心配置自动启动。
datanucleus.autoStartMechanism
SchemaTable
1.4、默认配置
默认配置将设置一个自带的metastore,它将在单元测试中使用。
1.5、本地/自带 Metastore数据库(Derby)
自带的metastore数据库主要用于单元测试。一次只能有一个进程连接到metastore数据库,所以这不是一个实际的解决方案,但在单元测试中工作得很好。
对于单元测试,Metastore服务器的本地/嵌入式Metastore服务器配置与自带的数据库一起使用。
Derby是自带的metastore的默认数据库。
| Config Param |
Config Value |
Comment |
| javax.jdo.option.ConnectionURL |
|
Derby数据库位于hive/trunk/build… |
| javax.jdo.option.ConnectionDriverName |
|
Derby自带了JDBC驱动类 |
| hive.metastore.warehouse.dir |
file://${user.dir}/../build/ql/test/data/warehouse |
单元测试数据放在本地文件系统中 |
如果您希望将Derby作为网络服务器运行,以便可以从多个节点访问metastore,请参阅Hive Using Derby in server Mode。
1.6、远程Metastore数据库
在此配置中,您将使用传统的独立RDBMS服务器。下面的示例配置将在MySQL服务器中设置一个metastore。建议实际使用metastore数据库的这种配置。
| Config Param |
Config Value |
Comment |
| javax.jdo.option.ConnectionURL |
|
元数据存储在MySQL服务器中 |
| javax.jdo.option.ConnectionDriverName |
|
MySQL JDBC 驱动类 |
| javax.jdo.option.ConnectionUserName |
|
连接MySQL服务的用户名 |
| javax.jdo.option.ConnectionPassword |
|
连接MySQL服务的密码 |
1.7、本地/自带 Metastore服务
在本地/内嵌的metastore安装中,metastore服务器组件像Hive Client中的库一样被使用。每个Hive Client将打开一个连接到数据库,并对它进行SQL查询。确保执行Hive查询的机器可以访问数据库,因为这是一个本地存储。还要确保JDBC客户端库在Hive client的类路径中。这个配置通常在HiveServer2中使用(仅在HiveServer2中添加“——hiveseconf hive.metastore”)。uris=' '",或者使用hiveserver2-site.xml (Hive 0.14中提供)。
| Config Param |
Config Value |
Comment |
| hive.metastore.uris |
not needed because this is local store |
|
| hive.metastore.local |
|
这是本地存储(在Hive 0.10中移除,参见配置描述部分) |
| hive.metastore.warehouse.dir |
|
指向HDFS中非外部Hive表的默认位置。 |
1.8、远程Metastore服务
在远程metastore设置中,所有的Hive客户端将连接到一个metastore服务器,反过来查询数据存储(在这个例子中是MySQL)的元数据。Metastore服务器和客户端使用Thrift协议进行通信。从Hive 0.5.0开始,可以执行以下命令启动Thrift服务器:
hive --service metastore在Hive 0.5.0之前的版本中,需要通过直接执行Java来运行Thrift服务器:$JAVA_HOME/bin/java -Xmx1024m -Dlog4j.configuration=file://$HIVE_HOME/conf/hms-log4j.properties -Djava.library.path=$HADOOP_HOME/lib/native/Linux-amd64-64/ -cp $CLASSPATH org.apache.hadoop.hive.metastore.HiveMetaStore
如果直接执行Java,那么JAVA_HOME, HIVE_HOME, HADOOP_HOME必须正确设置;CLASSPATH应该包含Hadoop、Hive (lib和auxlib)和Java jar。
1.8.1、服务端配置参数
下面以Remote Metastore数据库为例。
| Config Param |
Config Value |
Comment |
| javax.jdo.option.ConnectionURL |
|
metadata is stored in a MySQL server |
| javax.jdo.option.ConnectionDriverName |
|
MySQL JDBC driver class |
| javax.jdo.option.ConnectionUserName |
|
user name for connecting to MySQL server |
| javax.jdo.option.ConnectionPassword |
|
password for connecting to MySQL server |
| hive.metastore.warehouse.dir |
|
默认hive表路径 |
| hive.metastore.thrift.bind.host |
|
Host name to bind the metastore service to. When empty, "localhost" is used. This configuration is available Hive 4.0.0 onwards. |
从Hive 3.0.0 (Hive -16452)开始,metastore数据库存储了一个GUID,可以通过Thrift API get_metastore_db_uuid被metastore客户端查询,以识别后端数据库实例。HiveMetaStoreClient可以通过getMetastoreDbUuid()方法访问这个API。
1.8.2、客户端配置参数
| Config Param |
Config Value |
Comment |
| hive.metastore.uris |
|
Thrift metastore服务器的主机和端口。如果指定了hive.metastore.thrift.bind.host, host应该与该配置相同。在动态服务发现配置参数中了解更多信息。 |
| hive.metastore.local |
|
Metastore是远程的。注意:从Hive 0.10开始不再需要。设置hive.metastore.uri就足够了。 |
| hive.metastore.warehouse.dir |
|
指向HDFS中非外部Hive表的默认位置。 |
如果使用MySQL作为元数据的数据存储,在启动Hive Client或HiveMetastore Server之前,请将MySQL jdbc库放在HIVE_HOME/lib目录下。
1.9、支持的Metastore数据库类型
| Database |
Minimum Supported Version |
Name for Parameter Values |
See Also |
| MySQL |
5.6.17 |
|
|
| Postgres |
9.1.13 |
postgres | |
| Oracle |
11g |
|
hive.metastore.orm.retrieveMapNullsAsEmptyStrings |
| MS SQL Server |
2008 R2 |
|
Hive现在会记录metastore数据库中的模式版本,并验证metastore的模式版本是否与将要访问metastore的Hive二进制文件兼容。注意,默认情况下,用于隐式创建或修改现有模式的Hive属性是禁用的。Hive不会试图隐式改变metastore模式。当对旧模式执行Hive查询时,将无法访问metastore。
要抑制模式检查并允许metastore隐式修改模式,您需要在hive-site.xml中将配置属性hive.metastore.schema.verification设置为false。
从0.12版开始,Hive还包括一个离线模式工具来初始化和升级metastore模式。
2、元数据库表详解
在第一章节的时候有介绍过metastore里面的库表之间的关系图
2.1、表详解
掌握如下几个常用的表,就能够基本上玩转Metastore里的内容了。
附一段,根据表名,利用如下几个表查出这个表的重要信息的SQL语句
SELECT concat(a2.name,a1.tbl_name,a4.integer_idx) AS primary_key
,a1.tbl_id
,a1.db_id
,a1.owner AS create_table_auth
,a1.sd_id
,a2.name AS database_name
,a5.param_value AS table_comments
,a1.tbl_name AS TABLE_NAME
,a1.tbl_type AS table_type
,a4.comment AS column_comments
,a4.column_name
,a4.type_name
,a3.location
,a3.input_format
,a3.output_format
,a4.integer_idx
FROM (
SELECT tbl_id
,db_id
,OWNER
,sd_id
,tbl_name
,tbl_type
FROM tbls
WHERE tbl_name = 'table_name'
) a1
LEFT JOIN dbs a2
ON a1.db_id = a2.db_id LEFT
JOIN sds a3
ON a1.sd_id = a3.sd_id
LEFT JOIN columns_v2 a4
ON a3.cd_id = a4.cd_id LEFT
JOIN table_params a5
ON a1.tbl_id = a5.tbl_id
AND a5.param_key = 'comment'
WHERE a2.name <> 'default'2.1.1、 TBLS(表的表头信息)表解释

| 英文名 |
类型 |
中文注释 |
| TBL_ID |
bigint(20) |
全表唯一主键 |
| CREATE_TIME |
int(11) |
表创建时间,格式是到秒的时间戳 |
| DB_ID |
bigint(20) |
DBS 表的id |
| LAST_ACCESS_TIME |
int(11) |
|
| OWNER |
varchar(767) |
创建表的用户名 |
| OWNER_TYPE |
varchar(10) |
|
| RETENTION |
int(11) |
|
| SD_ID |
bigint(20) |
|
| TBL_NAME |
varchar(256) |
表名 |
| TBL_TYPE |
varchar(128) |
类型: EXTERNAL_TABLE 外部表 MANAGED_TABLE内部表 VIRTUAL_VIEW 试图 |
| VIEW_EXPANDED_TEXT |
mediumtext |
如果是试图的话,试图的SQL语句 |
| VIEW_ORIGINAL_TEXT |
mediumtext |
|
| IS_REWRITE_ENABLED |
bit(1) |
2.1.2、 DBS(表db信息)表解释
| 英文名 |
类型 |
中文注释 |
| DB_ID |
bigint(20) |
唯一主键id |
| DESC |
Varchar(4000) |
|
| DB_LOCATION_URI |
varchar(4000) |
表所属db的路径地址 |
| NAME |
varchar(128) |
表所属db的名字 |
| OWNER_NAME |
varchar (128) |
表所属账号名字 |
| OWNER_TYPE |
varchar (10) |
|
| CTLG_NAME |
varchar(256) |
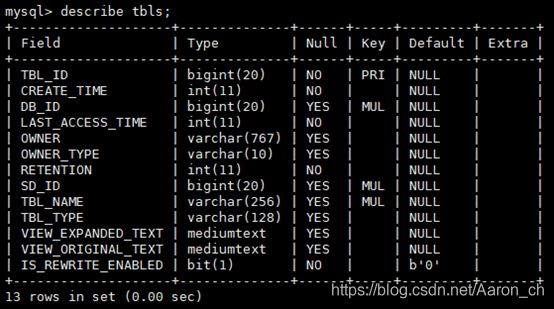
2.1.3、 SDS(表存储格式相关内容)表解释
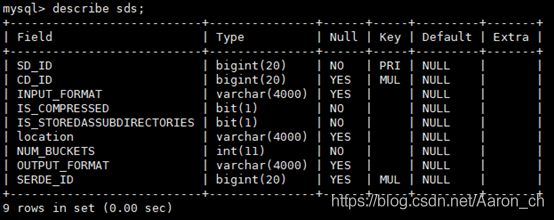
| 英文名 |
类型 |
中文注释 |
| SD_ID |
bigint(20) |
唯一主键id |
| CD_ID |
bigint(20) |
|
| INPUT_FORMAT |
varchar(4000) |
Input格式 |
| IS_COMPRESSED |
bit(1) |
|
| IS_STOREDASSUBDIRECTORIES |
bit(1) |
|
| location |
varchar(4000) |
数据存储路径 |
| NUM_BUCKETS |
Int(11) |
|
| OUTPUT_FORMAT |
varchar(4000) |
Output格式 |
| SERDE_ID |
bigint(20) |
2.1.4、 columns_v2(表字段详情)表解释
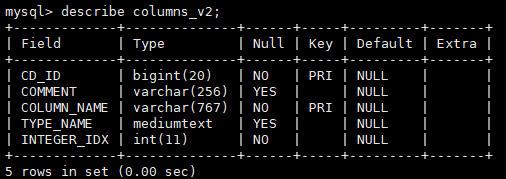
| 英文名 |
类型 |
中文注释 |
| CD_ID |
bigint(20) |
跟sds表的cd_id关联 |
| COMMENT |
varchar(4000) |
注释信息 |
| COLUMN_NAME |
bit(1) |
列名 |
| TYPE_NAME |
bit(1) |
列值类型 |
| INTEGER_IDX |
varchar(4000) |
列在表中的顺序 |
2.1.5、 table_params(表附属信息)表解释
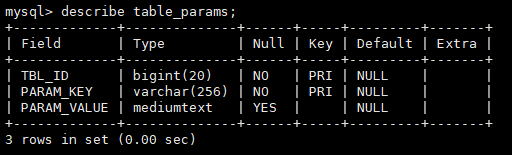
| 英文名 |
类型 |
中文注释 |
| TBL_ID |
bigint(20) |
跟tbls表的tbl_id关联 |
| PARAM_KEY |
varchar(4000) |
comment –> 表注释 EXTERNAL –> 是否是外部表 parquet.compression –> 是否压缩 transient_lastDdlTime –> 最近一次ddl时间(时间戳) |
| PARAM_VALUE |
bit(1) |
Key对的value值 |
3、元数据接口详解
3.1、接口详解
官方hive接口文档地址:https://hive.apache.org/javadocs/ ,在这个上面可以选择对应的hive版本之后再详细看里面的接口。
3.2、代码接口详解
由于接口比较多,挑选几个重要的详细说明下
//获取所有的数据库
getAllDatabases
//获取所有的表名
getAllTables
//获取分区信息
getPartition
//获取schema信息
getSchema
//获取函数信息
getFunctions3.3、代码样例
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hadoop.hive.metastore.HiveMetaStoreClient;
import org.apache.hadoop.hive.metastore.api.FieldSchema;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.metastore.api.Table;
import org.apache.thrift.TException;
import java.util.List;
public class HiveMetastoreApi {
public static void main(String[] args) {
HiveConf hiveConf = new HiveConf();
hiveConf.addResource("hive-site.xml");
HiveMetaStoreClient client = null;
try {
client = new HiveMetaStoreClient(hiveConf);
} catch (MetaException e) {
e.printStackTrace();
}
//获取数据库信息
List tablesList = null;
try {
tablesList = client.getAllTables("db_name");
} catch (MetaException e) {
e.printStackTrace();
}
System.out.print("db_name 数据所有的表: ");
for (String s : tablesList) {
System.out.print(s + "\t");
}
System.out.println();
//获取表信息
System.out.println("db_name.table_name 表信息: ");
Table table = null;
try {
table = client.getTable("db_name", "table_name");
} catch (TException e) {
e.printStackTrace();
}
List fieldSchemaList = table.getSd().getCols();
for (FieldSchema schema : fieldSchemaList) {
System.out.println("字段: " + schema.getName() + ", 类型: " + schema.getType());
}
client.close();
}
}