spark读取hive表异常,处理WARN HiveExternalCatalog: The table schema given by Hive metastore
文章目录
- 1 问题概述
-
- 1.1 数据库表状况
- 1.2 问题背景
- 2 报错场景
-
- 2.1 修改Hive元数据信息
- 2.2 报错信息
- 2.3 其他现象
- 2.4 查看表结构时的发现
- 2.5 报错分析
- 2.6 尝试MSCK REPAIR TABLE及过程详解(一次不成功的尝试,但也学到了一些知识)
-
- 2.6.1 MSCK REPAIR TABLE命令详解
- 2.5.2 MSCK REPAIR TABLE报OOM错误的解决方法
- 3 报错分析及修复方法
- 4 本例中的修复过程和自动化生成参数的Python脚本
-
- 4.1 参数设置——spark schema的数据类型转换
- 4.2 参数设置——spark schema的参数数量
- 4.3 实用工具——批量化地自动生成spark schema的参数信息
- 5 文内链接推荐阅读文章及资源集合
- 参考文章
1 问题概述
1.1 数据库表状况
大数据环境下有一张hdfs表,analytics.tracking_log_base。该表是外部表,存储格式为parquet,有220多个字段,大概2.1万个分区,约6.01TB。存储了2019年9月开始的一系列广告监测数据,考虑到parquet的压缩效率较高,达到这个数据大小,说明这张表的数据量非常大。
1.2 问题背景
因为原表的字段注释有问题,需要更改字段注释,所以用alter命令把大量字段都做了更新。然而更新之后出现了两个问题:
- 用Spark查询这张Hive表时,会报警告WARN HiveExternalCatalog:The table schema given by Hive metastore…,大意就是Spark无法使用Hive存储的元数据,需要从所有分区表中读取元数据信息。之后Spark任务会卡在Listing leaf files这一步。详细的报错场景会再下一章节说明。本文主要讨论的就是如何一步步定位问题并尝试解决改问题的过程。
- 在修改元数据的过程中,不小心将原本为int、bigint类型的列转换为了string类型,导致spark在读parqet文件时报列格式错误。关于这一问题的修复,详见另一篇文章:Hive表字段类型转换错误解决:Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
2 报错场景
2.1 修改Hive元数据信息
我对该表的元数据做了更改,具体是:将原来注释都是???的非分区字段替换成了正常的中文注释。例如下图所示这样的字段注释:
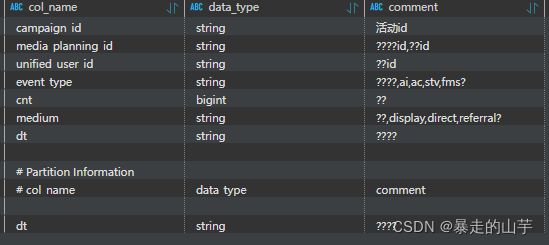
2.2 报错信息
观察Sparksql的执行过程,我发现我只选取这张表某一个dt分区的数据,但是在Listing leaf files这一步,对这张表的所有分区都进行了扫描,如下图1。同时在执行日志里出现了警告,如下图2。


2.3 其他现象
- 读表异常只在spark-sql运行时出现, 而使用hive-sql可以正常运行;
- 表的分区很多数据量很大时才出现。
2.4 查看表结构时的发现
执行show create table table_name或desc format table_name语句后,可以查看到表的各种字段、表属性等信息。
以一个网上看到的show create table的结果举例,
CREATE EXTERNAL TABLE table_name (
server_time bigint COMMENT ‘服务器接收时间’,
ip string COMMENT ‘客户端ip’,
)
COMMENT ‘测试athena通用dwd’
PARTITIONED BY (
dt string COMMENT ‘’
ROW FORMAT SERDE
‘org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe’
STORED AS INPUTFORMAT
‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat’
OUTPUTFORMAT
‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat’
LOCATION
‘s3_path’
TBLPROPERTIES (
‘last_modified_by’=‘houyuan.sheng’,
‘last_modified_time’=‘1637478001’,
‘lifecycle’=‘-1’,
‘owner’=‘houyuan.sheng’,
'parquet.compress'='snappy', 'spark.sql.create.version'='2.2 or prior', 'spark.sql.sources.schema.numPartCols'='1', 'spark.sql.sources.schema.numParts'='1', 'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"server_time","type":"long","nullable":true,"metadata":{"comment":"服务器接收时间"}},{"name":"dt","type":"string","nullable":true,"metadata":{"comment":""}}]}', 'spark.sql.sources.schema.partCol.0'='dt'
)
注意: 只有spark向hive表写入数据或刷新表的元数据后, 加粗字体的属性才会出现。
2.5 报错分析
- 原因1:用hive命令修改元数据后, 导致hive表的元数据信息和spark-SQL的schema不一致。
(Spark-sql的schema是其内部数据类型Dataframe的表结构信息,和Hive的元数据有相似的功能。关于spark内部数据结构的解析,可以查看这篇文章:Spark DataFrame理解和使用之概念理解) - 原因2:spark启用了自动推测机制, 分区过多导致了内存溢出。
(关于Spark的自动推测机制,可以查看这篇文章:spark的spark.sql.hive.caseSensitiveInferenceMode参数含义)
于是我想可能是需要修复Hive表的元数据,就根据以往的经验,执行了MSCK REPAIR TABLE table_name。
2.6 尝试MSCK REPAIR TABLE及过程详解(一次不成功的尝试,但也学到了一些知识)
然而,我在查询官方文档和若干资料后了解到:
- MSCK REPAIR TABLE table_name并不适用于本场景,该语句是用于当直接向HDFS中添加分区文件,而没有同步到Hive元数据时使用的。
- 本表虽然是外部表,但是分区和文件数过多,因此执行MSCK REPAIR TABLE时会报OOM(超内存)的错误。虽然Hive官方文档和资料均称有参数可以解决OOM问题,但是笔者发现该参数只能通过修改XML文件来实现,故没有使用。
现对以上两点进行详细说明:
2.6.1 MSCK REPAIR TABLE命令详解
msck repair table 作用是检查HDFS目录下存在(不存在)但表的metastore中不存在(存在)的元数据信息,更新到metastore中。
每次执行msck repair这个命令,都会检查所有分区的目录是否在元数据中存在,如果是每次新增一个分区的任务(daily的),那么使用这个语句将会越来越耗费时间,建议使用ALTER TABLE ADD PARTITION 命令。MSCK适合一次导入很多分区,需要将这些分区都更新到元数据信息中。
Spark官方文档中关于MSCK命令的解释(需要后访问)
此处粘贴一部分官方文档中的解释,了解详情可以查看官方文档
MSCK REPAIR TABLE 恢复表目录中的所有分区并更新 Hive 元存储。 使用 PARTITIONED BY 子句创建表时,会生成分区并在 Hive 元存储中注册。 但是,如果分区表是从现有数据创建的,则分区不会自动注册到 Hive 元存储中。 用户需要运行 MSCK REPAIR TABLE 来注册分区。 不存在的表或没有分区的表上的 MSCK REPAIR TABLE 会引发异常。 恢复分区的另一种方法是使用 ALTER TABLE RECOVER PARTITIONS。
对于msck repair table的命令解析,还可以查看这篇文章:refresh table 和 msck repair table 的区别
2.5.2 MSCK REPAIR TABLE报OOM错误的解决方法
OOM错误详情信息
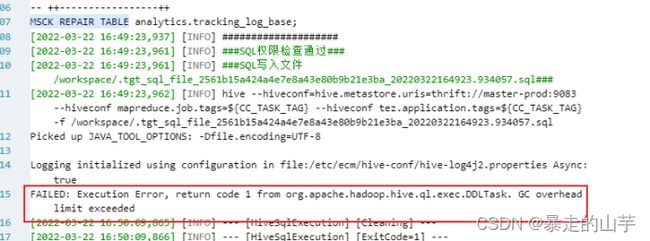
如果要解决,需要设置这两个参数:
set hive.msck.repair.batch.size=1000;
set hive.msck.path.validation=ignore;
第一个参数是设置每次插入到metaStore 分区的批量大小,假如有10000个待修复的分区 那么这里就是10000/1000 共计十个批次,默认如果不设置此参数会把所有数据全部发送到metastore 中执行插入操作。Hive更新日志中的说明(需后查看)
第二个参数的意义为:从 Hive 1.3 开始,如果在 HDFS 上发现分区值中包含不允许字符的目录,MSCK 将抛出异常。 可以使用客户端上的 hive.msck.path.validation 设置来更改此行为; “skip”将简单地跳过目录。 “ignore”无论如何都会尝试创建分区(1.3以前的默认操作)。Hive官方Manual文档中的说明(需后查看) ;
特别需要注意的是,有可能以下两种情况都会失败:
- 在sql最开始以set形式设置参数;
- 在提交Hive任务时通过hiveconf来设置参数。
那么此时,需要在hive 配置文件 hive-site.xml中添加或修改参数。并且在修改参数之后,需要重启Hive服务才能使参数生效。
<property>
<name>hive.msck.repair.batch.sizename>
<value>1000value>
property>
<property>
<name>hive.msck.path.validationname>
<value>ignorevalue>
property>
再重申一遍,MSCK REPAIR TABLE table_name并不适用于本问题的解决,以上仅做拓展学习
3 报错分析及修复方法
需要修改Hive元数据中tblproperties里的Spark缓存信息,使其和Hive元数据中的各字段信息相同。即在本案例中,将tblproperties中每个字段的注释也做更改。现有2种方法可以实现此功能:
- 表分区少时:
a. 使用spark对该表执行select或insert, 通过自动推断功能校正写入hive的schema;
b. 使用spark-sql,对表执行refresh table table_name操作。
关于refresh table和msck repair table的区别,可以查看这篇文章:refresh table 和 msck repair table 的区别 - 表分区很多时:手动修改hive元数据中spark的schema缓存属性, 其语法为:
-- Set Table Properties:添加或修改TBLPROPERTIES
ALTER TABLE table_identifier SET TBLPROPERTIES ( key1 = val1, key2 = val2, ... )
-- Unset Table Properties:删除TBLPROPERTIES
ALTER TABLE table_identifier UNSET TBLPROPERTIES [ IF EXISTS ] ( key1, key2, ... )
关于更多于hive对表做元数据修改操作的DDL语句的写法,可以查看spark的官方文档中关于DDL语句的说明,其中内容同样适用于Hive。
除了上述方法外,也可以对执行不成功的spark关闭推测功能,不过涉及到这张表的每个spark语句在提交运行时都要设置, 属于治标不治本。另外,在spark3.0中,该参数默认为不推测,详情可见前文中的文章链接。
set spark.sql.hive.caseSensitiveInferenceMode=NEVER_INFER;
因为本表的数据量太大,分区数过多。因此需要手动更新Hive表中的Spark元数据。否则Spark程序在更新元数据中的Schema信息时报错,报错信息就如文章开头所述的样子。
4 本例中的修复过程和自动化生成参数的Python脚本
Hive元数据中tblproperties里的Spark schema缓存信息中包含多个参数。
spark.sql.sources.schema.numPartCols
spark.sql.sources.schema.numParts
spark.sql.sources.schema.part.0
4.1 参数设置——spark schema的数据类型转换
Spark缓存的schema信息中,某些数据类型和Hive是不一样的。例如:Hive中的int类型,在spark中为Intege;bigint类型为long;string类型没有变化。关于Spark Schema的数据类型详解,可以查看本人的另一篇文章:Spark Schema、Hive和Python的数据类型关系,以及Pyspark数据类型详解
4.2 参数设置——spark schema的参数数量
实测,在只修改表非分区字段,没有修改表分区字段的情况下,只要修改第三个参数即可。而且观察该参数可以发现最后有part.0,这意味着还有part.1、part.2等。**笔者在实际测试之后发现,spark运行时最多读取到part.5,在part.6以后的信息不会被读取到schema信息中去。**因此手动添加或修改schema信息时要注意本限制。
4.3 实用工具——批量化地自动生成spark schema的参数信息
因为本表一共有220多个字段,而如果一个一个按指定的格式去手动写spark schema的参数信息,不仅容易写错,而且效率很低。因此笔者写了一个python脚本,用于读取字段信息并通过格式化字符串自动生成参数信息。点击链接可查看脚本详情
使用前需要使用desc命令,把查询出来的Hive表的字段信息保存到一个csv表中。本脚本是自动生成part.0~part.5共6个参数信息,如果字段较少,读者可以自行修改脚本后生成更少的参数信息。
5 文内链接推荐阅读文章及资源集合
- Hive表字段类型转换错误解决:Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
- Spark DataFrame理解和使用之概念理解
- Spark的自动推测机制解析
- Spark官方文档中关于MSCK命令的解释(需要后访问)
- refresh table 和 msck repair table 的区别
- hive.msck.repair.batch.size的官方说明(需后查看)
- hive.msck.path.validation的官方说明(需后查看)
- spark的官方文档中关于DDL语句的说明
- Spark Schema、Hive和Python的数据类型关系,以及Pyspark数据类型详解
- 【python脚本】批量化地自动生成Hive表中spark schema的参数信息
参考文章
spark读取hive表异常