原文链接:http://tecdat.cn/?p=11161
原文出处:拓端数据部落公众号
概率编程使我们能够实现统计模型,而不必担心技术细节。这对于基于MCMC采样的贝叶斯模型特别有用。

R语言中RStan贝叶斯层次模型分析示例
stan简介
Stan是用于贝叶斯推理的C ++库。它基于No-U-Turn采样器(NUTS),该采样器用于根据用户指定的模型和数据估计后验分布。使用Stan执行分析涉及以下步骤:
使用Stan建模语言指定统计模型。通过专用的_.stan_ 文件完成此操作 。
准备要提供给模型的数据。
使用该
stan函数从后验分布中采样 。分析结果。
在本文中,我将通过两个层次模型展示Stan的用法。我将使用第一个模型讨论Stan的基本功能,并使用第二个示例演示更高级的应用。
学校数据集
我们要使用的第一个数据集是 学校的数据集 。该数据集衡量了教练计划对大学入学考试(在美国使用的学业能力测验(SAT))的影响。 数据集如下所示:
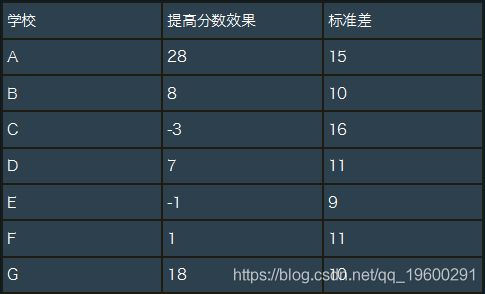
正如我们所看到的:对于八所学校中的大多数,短期教练计划的确提高了SAT分数 。对于此数据集,我们有兴趣估算与每所学校相关的真实教练计划效果大小。我们考虑两种替代方法。首先,我们可以假设所有学校彼此独立。但是,这将难以解释,因为学校的后验区间由于高标准差而在很大程度上重叠。第二,假设所有学校的真实效果都相同,则可以汇总所有学校的数据。但是,这也是不合理的,因为该计划有针对学校的不同效果(例如,不同的老师和学生应该有不同的计划)。
因此,需要另一个模型。分层模型的优点是可以合并来自所有八所学校的信息,而无需假定它们具有共同的真实效果。我们可以通过以下方式指定层次贝叶斯模型:
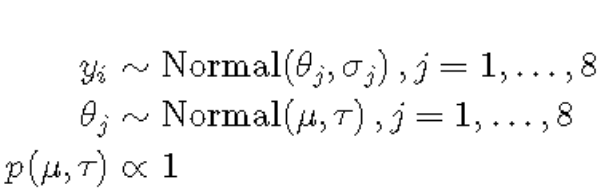
根据该模型,教练的效果遵循正态分布,其均值是真实效果θj,其标准偏差为σj(从数据中得知)。真正的影响θj遵循参数μ和τ的正态分布。
定义Stan模型文件
在指定了要使用的模型之后,我们现在可以讨论如何在Stan中指定此模型。在为上述模型定义Stan程序之前,让我们看一下Stan建模语言的结构。
变量
在Stan中,可以通过以下方式定义变量:
int n; # 下界是0
int n; # 上限是5
int n; # n 的范围是 \[0,5\] 注意,如果先验已知变量,则应指定变量的上下边界。
多维数据可以通过方括号指定:
vector\[n\] numbers; // 长度为n的向量
real\[n\] numbers; // 长度为n的浮点数组
matrix\[n,n\] matrix; // n乘n矩阵程序
Stan中使用以下程序 :
_data_:用于指定以贝叶斯规则为条件的数据
_转换后的数据_:用于预处理数据
参数 (必填):用于指定模型的参数
_转换后的参数_:用于计算后验之前的参数处理
模型 (必填):用于指定模型
_生成数量_:用于对结果进行后处理

对于 模型 程序块,可以两种等效方式指定分布。第一个,使用以下统计符号:
y ~ normal(mu, sigma); # y 服从正态分布第二种方法使用基于对数概率密度函数(lpdf)的程序化表示法:
target += normal_lpdf(y | mu, sigma); # 增加正态对数密度Stan支持大量的概率分布。通过Stan指定模型时,该 lookup 函数会派上用场:它提供从R函数到Stan函数的映射。考虑以下示例:
library(rstan) # 加载stan包
lookup(rnorm)## StanFunction Arguments ReturnType Page
## 355 normal_rng (real mu, real sigma) real 494在这里,我们看到R中的rnorm 等价于 Stan的 normal_rng 。
模型
现在,我们了解了Stan建模语言的基础知识,我们可以定义模型,并将其存储在一个名为的文件中 schools.stan:
注意,θ 永远不会出现在参数中。这是因为我们没有显式地对θ进行建模,而是对η(各个学校的标准化效果)进行了建模。然后, 根据μ,τ和η在_变换后的参数_部分构造θ 。此参数化使采样器更高效。
准备数据进行建模
在拟合模型之前,我们需要将输入数据编码为一个列表,其参数应与Stan模型的数据部分相对应。对于学校数据,数据如下:
schools.data <- list(
n = 8,
y = c(28, 8, -3, 7, -1, 1, 18, 12),
sigma = c(15, 10, 16, 11, 9, 11, 10, 18)
)从后验分布抽样
我们可以使用stan 函数从后验分布中采样,函数执行以下三个步骤:
它将模型规范转换为C ++代码。
它将C ++代码编译为共享对象。
它根据指定的模型,数据和设置从后验分布中采样。
如果 rstan_options(auto_write = TRUE),则相同模型的后续调用将比第一次调用快得多,因为该 stan 函数随后跳过了前两个步骤(转换和编译模型)。此外,我们将设置要使用的内核数:
options(mc.cores = parallel::detectCores()) # 并行化
rstan\_options(auto\_write = TRUE) # 存储编译的stan模型现在,我们可以从后验中编译模型和样本。
模型解释
我们将首先对模型进行基本解释,然后研究MCMC程序。
基本模型解释
要使用拟合模型执行推断,我们可以使用 print 函数。
print(fit1) # 可选参数:pars,probs## Inference for Stan model: schools.
## 4 chains, each with iter=2000; warmup=1000; thin=1;
## post-warmup draws per chain=1000, total post-warmup draws=4000.
##
## mean se\_mean sd 2.5% 25% 50% 75% 97.5% n\_eff Rhat
## mu 7.67 0.15 5.14 -2.69 4.42 7.83 10.93 17.87 1185 1
## tau 6.54 0.16 5.40 0.31 2.52 5.28 9.05 20.30 1157 1
## eta\[1\] 0.42 0.01 0.92 -1.47 -0.18 0.44 1.03 2.18 4000 1
## eta\[2\] 0.03 0.01 0.87 -1.74 -0.54 0.03 0.58 1.72 4000 1
## eta\[3\] -0.18 0.02 0.92 -1.95 -0.81 -0.20 0.45 1.65 3690 1
## eta\[4\] -0.03 0.01 0.92 -1.85 -0.64 -0.02 0.57 1.81 4000 1
## eta\[5\] -0.33 0.01 0.86 -2.05 -0.89 -0.34 0.22 1.43 3318 1
## eta\[6\] -0.20 0.01 0.87 -1.91 -0.80 -0.21 0.36 1.51 4000 1
## eta\[7\] 0.37 0.02 0.87 -1.37 -0.23 0.37 0.96 2.02 3017 1
## eta\[8\] 0.05 0.01 0.92 -1.77 -0.55 0.05 0.69 1.88 4000 1
## theta\[1\] 11.39 0.15 8.09 -2.21 6.14 10.30 15.56 30.22 2759 1
## theta\[2\] 7.92 0.10 6.25 -4.75 4.04 8.03 11.83 20.05 4000 1
## theta\[3\] 6.22 0.14 7.83 -11.41 2.03 6.64 10.80 20.97 3043 1
## theta\[4\] 7.58 0.10 6.54 -5.93 3.54 7.60 11.66 20.90 4000 1
## theta\[5\] 5.14 0.10 6.30 -8.68 1.40 5.63 9.50 16.12 4000 1
## theta\[6\] 6.08 0.10 6.62 -8.06 2.21 6.45 10.35 18.53 4000 1
## theta\[7\] 10.60 0.11 6.70 -0.94 6.15 10.01 14.48 25.75 4000 1
## theta\[8\] 8.19 0.14 8.18 -8.13 3.59 8.01 12.48 25.84 3361 1
## lp__ -39.47 0.07 2.58 -45.21 -41.01 -39.28 -37.70 -34.99 1251 1
##
## Samples were drawn using NUTS(diag_e) at Thu Nov 29 11:17:50 2018.
## For each parameter, n_eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor on split chains (at
## convergence, Rhat=1).在此,行名称表示估计的参数:mu是后验分布的平均值,而tau是其标准偏差。eta和theta的条目分别表示矢量η和θ的估计值。这些列表示计算值。百分比表示置信区间。例如,教练计划的总体效果的95%可信区间μ为[-1.27,18.26]。由于我们不确定平均值,因此θj的95%置信区间也很宽。例如,对于第一所学校,95%置信区间为[−2.19,32.33]。
我们可以使用以下plot 函数来可视化估计中的不确定性 :
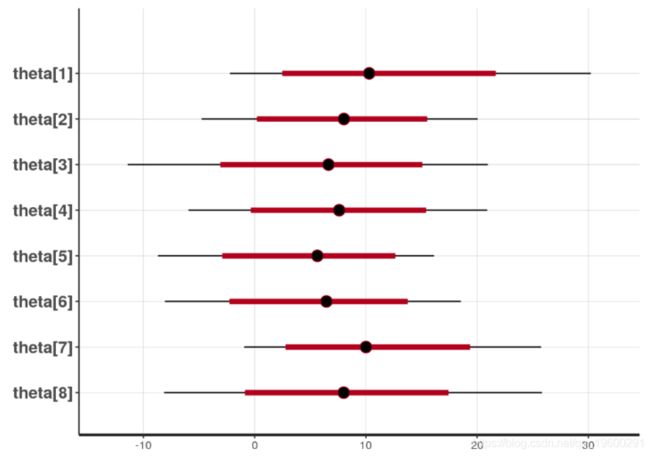
黑线表示95%的间隔,而红线表示80%的间隔。圆圈表示平均值的估计。
我们可以使用以下extract 函数获取生成的样本 :
# 获取样本
samples <- extract(fit1, permuted = TRUE) # 每个参数1000个样本MCMC诊断
通过绘制采样过程的轨迹图,我们可以确定采样期间是否出了问题。例如,链条在一个位置停留的时间过长或在一个方向上走了太多步,就会有问题。我们可以使用traceplot 函数绘制模型中使用的四个链的轨迹 :
# 诊断: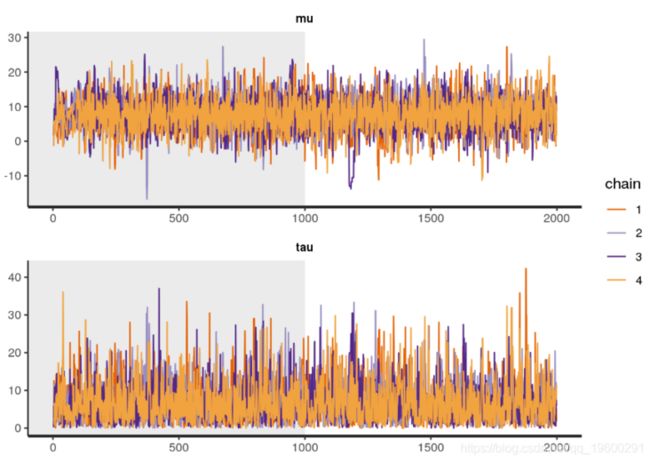
要从各个马尔可夫链中获取样本,我们可以extract 再次使用函数:
## parameters
## chains mu tau eta\[1\] eta\[2\] eta\[3\] eta\[4\]
## chain:1 1.111120 2.729124 -0.1581242 -0.8498898 0.5025965 -1.9874554
## chain:2 3.633421 2.588945 1.2058772 -1.1173221 1.4830778 0.4838649
## chain:3 13.793056 3.144159 0.6023924 -1.1188243 -1.2393491 -0.6118482
## chain:4 3.673380 13.889267 -0.0869434 1.1900236 -0.0378830 -0.2687284
## parameters
## chains eta\[5\] eta\[6\] eta\[7\] eta\[8\] theta\[1\]
## chain:1 0.3367602 -1.1940843 0.5834020 -0.08371249 0.6795797
## chain:2 -1.8057252 0.7429594 0.9517675 0.55907356 6.7553706
## chain:3 -1.5867789 0.6334288 -0.4613463 -1.44533007 15.6870727
## chain:4 0.1028605 0.3481214 0.9264762 0.45331024 2.4657999
## parameters
## chains theta\[2\] theta\[3\] theta\[4\] theta\[5\] theta\[6\] theta\[7\]
## chain:1 -1.208335 2.482769 -4.31289292 2.030181 -2.147684 2.703297
## chain:2 0.740736 7.473028 4.88612054 -1.041502 5.556902 6.097494
## chain:3 10.275294 9.896345 11.86930758 8.803971 15.784656 12.342510
## chain:4 20.201935 3.147213 -0.05906019 5.102037 8.508530 16.541455
## parameters
## chains theta\[8\] lp__
## chain:1 0.8826584 -41.21499
## chain:2 5.0808317 -41.17178
## chain:3 9.2487083 -40.35351
## chain:4 9.9695268 -36.34043为了对采样过程进行更高级的分析,我们可以使用该 shinystan 软件包 。使用该软件包,可以通过以下方式启动Shiny应用程序来分析拟合模型:
library(shinystan)
launch_shinystan(fit1)层次回归
现在,我们对Stan有了基本的了解,我们可以深入研究更高级的应用程序:让我们尝试一下层次回归。在常规回归中,我们对以下形式的关系进行建模
![]()
此表示假设所有样本都具有相同的分布。如果只存在一组样本,那么我们就会遇到问题,因为将忽略组内和组之间的潜在差异。
另一种选择是为每个组建立一个回归模型。但是,在这种情况下,估计单个模型时,小样本量会带来问题。
层次回归是两个极端之间的折衷。该模型假设组是相似的,但存在差异。
假设每个样本都属于K组之一。然后,层次回归指定如下:

其中Yk是第k组的结果,αk是截距,Xk是特征,β(k)表示权重。层次模型不同于其中Yk分别拟合每个组的模型,因为假定参数αk和β(k)源自共同的分布。
数据集
分层回归的经典示例是 老鼠数据集。该数据集包含5周内测得的 鼠体重。让我们加载数据:
## day8 day15 day22 day29 day36
## 1 151 199 246 283 320
## 2 145 199 249 293 354
## 3 147 214 263 312 328
## 4 155 200 237 272 297
## 5 135 188 230 280 323
## 6 159 210 252 298 331让我们调查数据:
library(ggplot2)
ggplot(ddf, aes(x = variable, y = value, group = Group)) + geom\_line() + geom\_point()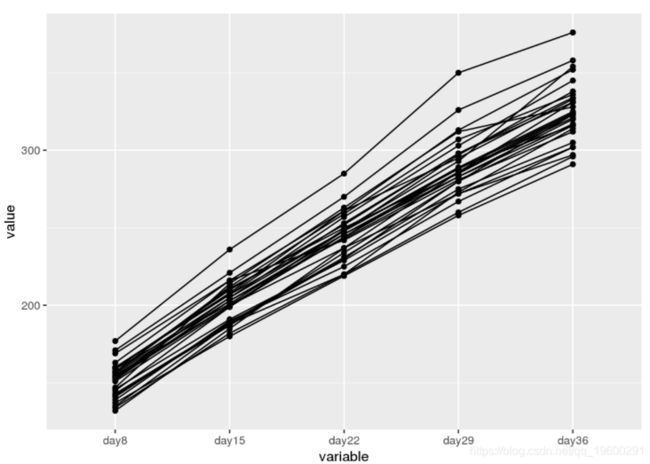
数据显示线性增长趋势对于不同的大鼠非常相似。但是,我们还看到,大鼠的初始体重不同,需要不同的截距,并且生长速度也需要不同的斜率。因此,分层模型似乎是适当的。
层次回归模型的规范
该模型可以指定如下:

第i个大鼠的截距由αi表示,斜率由βi表示。注意,测量时间的中心是x = 22,它是时间序列数据的中值测量值(第22天)。
现在,我们可以指定模型并将其存储在名为 rats.stan的文件中 :
请注意,模型代码估算的是方差( sigmasq 变量)而不是标准差。
资料准备
为了准备模型数据,我们首先将测量点提取为数值,然后将所有内容编码为列表结构:
data <- list(N = nrow(df), T = ncol(df), x = days,
y = df, xbar = median(days))拟合回归模型
现在,我们可以为老鼠体重数据集拟合贝叶斯层次回归模型:
# 模型包含截距(alpha)和斜率(beta)的估计层次回归模型的预测
在确定了每只大鼠的α和β之后,我们现在可以估计任意时间点单个大鼠的体重。在这里,我们寻找从第0天到第100天的大鼠体重。

ggplot(pred.df\[pred.df$Rat %in% sel.rats, \],
aes(x = Day, y = Weight, group = Rat,
geom_line() +
与原始数据相比,该模型的估计是平滑的,因为每条曲线都遵循线性模型。研究最后一个图中所示的置信区间,我们可以看到方差估计是合理的。我们对采样时(第8至36天)的老鼠体重充满信心,但是随着离开采样区域,不确定性会增加。

最受欢迎的见解
4.R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归