CenterNet2:CenterNet再升级,原作者提出基于概率解释的两阶段目标检测
论文地址:https://arxiv.org/abs/2103.07461
GitHub地址:https://github.com/xingyizhou/CenterNet2
说明:本文是CenterNet(Objects as Points)原作者基于概率解释提出的两阶段目标检测框架,包括多个版本,其中以CenterNet为第一阶段的版本即为CenterNet2.
目录
0、摘要
1、引言
2、相关工作
3、预备知识
4、两阶段检测的概率解释
5、构造一个概率的两阶段检测器
6、结果
7、结论
0、摘要
开发了一个两阶段目标检测的概率性解释,并表明:这种概率解释可以激发许多常见的经验性训练实践,并建议对两阶段检测pipeline进行改造。具体来说,第一阶段推断出目标-背景的似然性,第二阶段得到具体分类得分。标准RPN不能很好地推断这种似然性,但很多SOTA一阶段检测器可以。我们展示了如何从任意的SOTA一阶段检测器构造出一个概率性的两阶段检测器,而且所构造的检测器比起构造它的一阶段、二阶段检测器来说也更快、更强。我们的检测器在COCO上达到单尺度56.4 mAP的性能,超出了目前已有的研究成果。而使用一个轻量的backbone,我们的检测器可以在COCO上达到49.2mAP、33FPS,比YOLOv4更强。
1、引言
目标检测的目的是从一张图中找出所有的目标并确定其位置及其所属类别的概率。一阶段目标检测器将定位和分类联合了起来,放入一个概率上合理的框架中;其被训练以最大化标注GT目标的对数似然,并在推理时预测一个合适的似然分数。两阶段目标检测器首先在第一阶段枚举所有潜在的目标及其位置,然后在第二阶段对这些潜在目标进行分类;第一阶段被设计用于最大化召回率,而第二阶段用于在第一阶段过滤的区域上最大化分类目标;第二阶段有概率性解释,而两个阶段的结合却没有。
本文开发了一个两阶段目标检测的概率性解释。在标准两阶段检测器训练的基础上,提出一个简单的改进:对两个阶段联合概率目标的下界进行优化。通过概率性的处理,建议对两阶段检测器进行改进,具体的,第一阶段需要推断出校准的目标似然。目前两阶段检测器中的RPN是为了最大化proposal的召回而设计的,因此其不具备产生准确似然的能力。不过,功能完备的一阶段检测器却可以。
我们在SOTA一阶段检测器基础上,构造了一个概率性的两阶段检测器。在第一阶段,我们的模型使用一阶段检测器提取区域级别的特征并对其分类;在第二阶段使用Faster RCNN或者一个级联分类器。这两个阶段一起训练,最大化GT目标的对数似然。在推理时,我们的检测器使用最终的对数似然作为检测得分。
一个概率性的两阶段检测器,比起它的组成部分(一阶段检测器、二阶段检测器)更快、准确率更高。相比两阶段anchor-based检测器,我们的第一阶段更加准确,且允许检测器在ROI head上使用更少的proposal(256 vs 1K),这使得我们的检测器整体上更准确、更快。相比于一阶段检测器,我们的第一阶段使用了一个更精简的head设计,并只有一个输出类别用于密集图像级预测。由于类别个数急剧减少所带来的的加速,远远超出了由于增加第二阶段所带来的成本。我们第二阶段利用了多年来两阶段检测的进展,与一阶段baseline相比,检测准确率显著提升。它也能轻松扩展到大词汇量(类别)检测上。
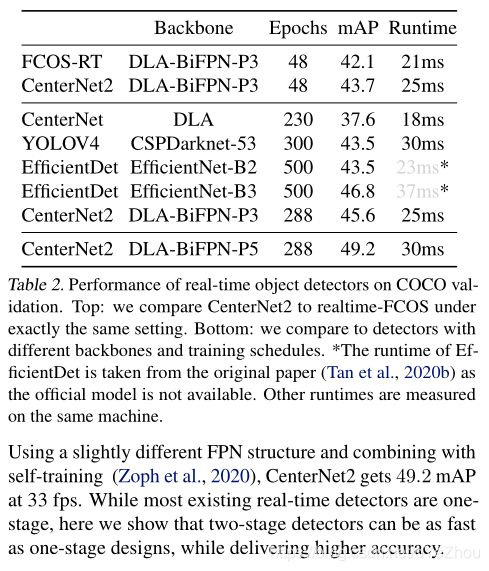
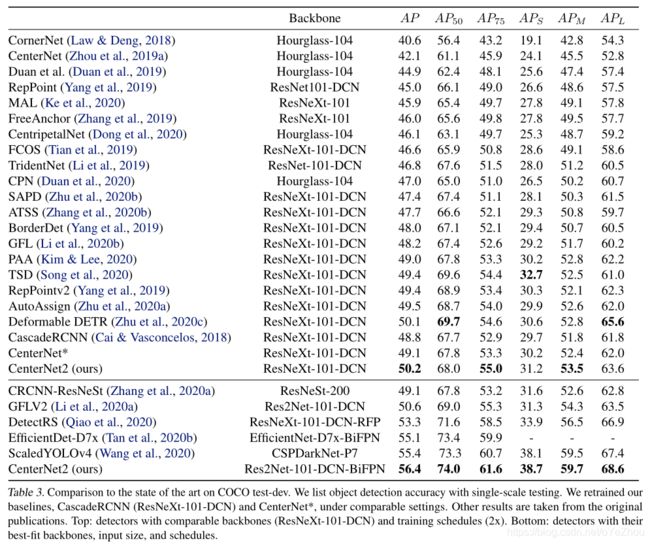
在COCO、LVIS、Objects 365上的实验表明,我们的概率性两阶段框架能够使Cascade RCNN的mAP提升1-3个点,且速度有所提升。使用以标准ResNeXt-101-DCN为backbone的CenterNet作为第一阶段,可以在COCO上达到50.2mAP。使用强大的Res2Net-101-DCN-BiFPN作为backbone并进行自训练,可以在单尺度测试上达到56.4mAP,这个结果超出了目前所有的公开成果。使用小的DLA-BiFPN作为backbone并降低输入分辨率,使用Titan Xp显卡在COCO上可以达到49.2mAP、33FPS,这个结果优于YOLOv4模型 (43.5 mAP at 33 fps)。
所提出的基于概率性解释的两阶段检测器示意如图1所示:

2、相关工作
一阶段检测器联合了预测输出类别和目标定位。RetinaNet对一组预定义的滑动anchor boxes进行分类,并通过调整输出的损失大小来对前景-背景进行平衡;FCOS和CenterNet消除了每个像素点对多anchor的需求,并通过位置对前景-背景分类;ATSS和PAA通过改变前景-背景的定义进一步改进了FCOS;GFL和Autoassign将前景-背景的硬分配方式改为了加权软分配;AlignDet在输出之前使用了一个可变形卷积层来获取用于分类和回归的更精细的特征;RepPoint和DenseRepPoint将边界框编码为轮廓点集,并使用点集特征进行分类;BorderDet沿着边界框池化特征,以进行更好的定位。大多数一阶段检测器都有着可靠的概率性解释。
一阶段检测器达到有竞争力的性能,主要依赖于其使用了比两阶段检测器更重量级的独立分类、回归分支。事实上,如果词汇量(如目标类别集)很大(如LVIS或者Objects365数据集),这些一阶段检测器将不再比同等级的两阶段检测器更快。而且,一阶段检测器仅使用了正例区域的局部特征进行回归和分类,这有时候会导致与目标不对齐。
我们的概率性两阶段框架保留了一阶段检测器的概率性解释,但是将概率分布分解为多个阶段,对准确率和速度都有改进。
两阶段检测器首先使用RPN生成粗糙的目标proposal,然后使用专用的逐区域处理的head对这些proposals进行分类与细化。Faster RCNN使用两个全连接层作为ROI head;CascadeRCNN使用三个级联的Faster RCNN阶段,每个阶段使用不同的正例阈值以使得最后阶段更加聚焦于定位准确率;HTC使用了额外的实例和分割标注,来增强CascadeRCNN的阶段内的特征流;TSD对每个ROI的分类和定位进行了解耦。
两阶段检测器在很多设置中,仍然具备更高的准确率。目前,所有的两阶段检测器都使用了一个弱的RPN来最大化top 1K个proposals的召回,而且在测试阶段没有利用这些proposals得分。大量的proposals降低了系统速度,同时基于召回考虑的proposal 网络也没有像一阶段检测器那样直接提供一个清晰的概率解释。我们的框架解决了这个问题,并整合了一个强大的类别不可知单阶段目标检测器和一个分类阶段。我们的第一阶段使用更少但更高质量的区域,从而产生更快地推理、更高的准确率。
其他检测器。该系列的目标检测器是通过图像中关键点来定位目标的,如:CornerNet检测的是左上、右下角点,并使用嵌入特征对这些点进行分组;ExtremeNet检测四个极值点,并使用额外的中心点对其分组;CenterNet(不是Objects as Points)检测中心点并用于改进角点分组;Corner Proposal Net使用角点对分组形成region proposal;CenterNet(Objects as Points)检测中心点并回归边框的宽高。
DETR和Deformable DETR移除了检测器中的密集预测,取而代之的是使用Transformer直接预测一个边框集。
上述几种检测器(基于点的检测器、DETR类、传统anchor-based检测器)之间的主要区别在于网络结构。基于点的检测器使用全卷积网络,通常带有对称的下采样和上采样层,并产生一个单一的小输出步幅(如4)的feature map。DETR类的检测器使用transformer作为decoder。传统的一阶段、两阶段检测器通常需要使用增加了轻量级上采样层的分类网络,并且生成多尺度特征(FPN)。
3、预备知识
目标检测器的目的是从一张预定义了 个类别的图像中预测所有目标
个类别的图像中预测所有目标 的位置
的位置![]() 以及特定类别的似然分数
以及特定类别的似然分数![]() 。其中,目标的位置
。其中,目标的位置 通常描述为轴对齐边界框的两个角点,或者通过等价的中心点+尺寸来描述。目标检测器之间的主要不同在于其对类别似然的表示,这取决于其各自的架构。
通常描述为轴对齐边界框的两个角点,或者通过等价的中心点+尺寸来描述。目标检测器之间的主要不同在于其对类别似然的表示,这取决于其各自的架构。
一阶段检测器将目标定位和分类联合在一个单一网络中。令![]() 表示目标、类别
表示目标、类别 的正例目标,令
的正例目标,令![]() 表示背景。大多一阶段检测器对没个类别使用独立的sigmoid将其类别似然参数化为伯努利分布:
表示背景。大多一阶段检测器对没个类别使用独立的sigmoid将其类别似然参数化为伯努利分布:![]() ,其中
,其中![]() 是backbone生成的特征,
是backbone生成的特征,![]() 是指定类别的权重向量。在训练时,这种概率性解释允许一阶段检测器简单地最大化对数似然
是指定类别的权重向量。在训练时,这种概率性解释允许一阶段检测器简单地最大化对数似然![]() 或者GT标注信息的focal loss。一阶段检测器在正例
或者GT标注信息的focal loss。一阶段检测器在正例![]() 和负例
和负例![]() 的定义上是不同的,有些是用anchor IOU,有些是用位置。但它们都是优化对数似然并使用类别概率来对边框打分,且都是直接回归边框坐标。
的定义上是不同的,有些是用anchor IOU,有些是用位置。但它们都是优化对数似然并使用类别概率来对边框打分,且都是直接回归边框坐标。
两阶段检测器则首先提取潜在的目标位置,称之为目标proposal,并使用了前景-背景概率![]() 。然后,对每个proposal提取特征,并分类类或者背景
。然后,对每个proposal提取特征,并分类类或者背景![]() ,其中
,其中![]() ,同时对目标位置进行精细调整。此外,其每个阶段都是独立监督训练的。在第一个阶段,通过RPN学习到标注目标是属于前景,而其他的boxes属于背景,这一步通常使用目标对数似然进行二分类。然而,RPN对背景的定义非常保守,任何与GT的IOU小于30%(可能更多)的预测结果都会被认为是前景。这种标签定义更倾向于提高召回(PS:RPN的目的就是尽可能召回所有的潜在目标,也即宁可错杀一千也不放过一个),而不是精确和准确的相似度估计。因此,很多不完整的目标却得到了一个很高的proposal得分。在第二阶段,一个softmax分类器学习到将一个proposal分类为某个类别或者背景。分类器使用的是对数似然目标函数,其中前景标签来自标注信息,背景标签来自第一阶段提取的高分负例(其附近没有正例)。在训练时,这种类别分布隐含在第一阶段的正例检测条件中,因为其只在这些正例上进行训练和验证。第一阶段和第二阶段都有着概率解释,且仅在其正负例定义下进行目标的对数似然或者所属类别的估计。然而,两个阶段结合起来之后就没有了这种概率解释。其结合了多种启发式和采样策略,独立训练第一、第二阶段。最终输出是一组仅由第二阶段输出的带有分类得分的boxes。
,同时对目标位置进行精细调整。此外,其每个阶段都是独立监督训练的。在第一个阶段,通过RPN学习到标注目标是属于前景,而其他的boxes属于背景,这一步通常使用目标对数似然进行二分类。然而,RPN对背景的定义非常保守,任何与GT的IOU小于30%(可能更多)的预测结果都会被认为是前景。这种标签定义更倾向于提高召回(PS:RPN的目的就是尽可能召回所有的潜在目标,也即宁可错杀一千也不放过一个),而不是精确和准确的相似度估计。因此,很多不完整的目标却得到了一个很高的proposal得分。在第二阶段,一个softmax分类器学习到将一个proposal分类为某个类别或者背景。分类器使用的是对数似然目标函数,其中前景标签来自标注信息,背景标签来自第一阶段提取的高分负例(其附近没有正例)。在训练时,这种类别分布隐含在第一阶段的正例检测条件中,因为其只在这些正例上进行训练和验证。第一阶段和第二阶段都有着概率解释,且仅在其正负例定义下进行目标的对数似然或者所属类别的估计。然而,两个阶段结合起来之后就没有了这种概率解释。其结合了多种启发式和采样策略,独立训练第一、第二阶段。最终输出是一组仅由第二阶段输出的带有分类得分的boxes。
接下来,我们开发了一种两阶段检测器的简单概率解释,并认为其两个阶段属于类别似然估计的一部分。我们展示了这种想法是如何影响第一阶段的设计,以及如何有效地训练这两个阶段。
4、两阶段检测的概率解释
对于每幅图像,我们的目的是生成包含了K个检测的边框![]() 及其对应类别分数
及其对应类别分数![]() 的结果,类别包括C类和背景。在本文工作中,保持原两阶段检测器中的边框回归不变,仅关注于类别分布。一个两阶段检测器将这种类别分布分为了两部分:第一阶段产生一个类别不可知的目标概率
的结果,类别包括C类和背景。在本文工作中,保持原两阶段检测器中的边框回归不变,仅关注于类别分布。一个两阶段检测器将这种类别分布分为了两部分:第一阶段产生一个类别不可知的目标概率![]() ,第二阶段产生具体类别的条件概率
,第二阶段产生具体类别的条件概率![]() 。在这里,
。在这里,![]() 代表第一阶段检测出的正例,为0则代表背景。当第一阶段检测结果为负例时,其类别为背景的条件概率就对应的为1:
代表第一阶段检测出的正例,为0则代表背景。当第一阶段检测结果为负例时,其类别为背景的条件概率就对应的为1:![]() 。在多阶段检测器中,分类是由多个级联阶段完成的,而两阶段检测器是由一个单一分类器来完成的。两个阶段模型的联合类别分布表示为:
。在多阶段检测器中,分类是由多个级联阶段完成的,而两阶段检测器是由一个单一分类器来完成的。两个阶段模型的联合类别分布表示为:
![]() (1)
(1)
训练目标:
我们训练检测器使用的是极大似然估计,对于标注的正例,最大化下式,其分别对第一、第二阶段的似然目标函数进行最大化:
![]() (2)
(2)
对于背景类别,其极大似然目标函数没有分离:
![]()
该目标函数在计算损失和梯度时,对第一第二阶段的概率估计进行了绑定。精确的估计需要在第二阶段对第一阶段所有输出进行密集评估。与之相反,我们对目标函数推导了两个下限,并联合进行优化。第一个下限使用了杰森不等式![]() ,其中
,其中![]() ,
,![]() ,
,![]() ,则有:
,则有:
![]() (3)
(3)
该下限针对第一阶段所有高分目标,最大化了第二阶段中背景的对数似然。它收紧于![]() 或者
或者![]() ,但是却任意松弛于
,但是却任意松弛于![]() 和
和![]() 。
。
第二个下限仅涉及到第一阶段的目标函数:
![]() (4)
(4)
其用到了![]() 以及log函数的单调性。该下限收紧于
以及log函数的单调性。该下限收紧于![]() 。一般来说,达到极限时即为公式(3)和公式(4)之和。这个下限在
。一般来说,达到极限时即为公式(3)和公式(4)之和。这个下限在![]() 范围内,见附页所示。然而,在实践中,我们发现同时优化两个边界可以更好地工作。
范围内,见附页所示。然而,在实践中,我们发现同时优化两个边界可以更好地工作。
有了下限公式(4)和正例目标公式(2),第一阶段的训练就简化为最大似然估计——在标注对象上使用正标签,在所有其他位置使用负标签。它就等价于训练一个二元一阶段检测器,或者一个带有严格负定义的、鼓励似然估计和非召回的RPN。
检测器设计:
我们的概率两阶段检测器和标准的两阶段检测器之间主要不同在于公式(1)类别不可知概率![]() 的使用。在我们的概率公式中,分类得分是和类别不可知检测得分
的使用。在我们的概率公式中,分类得分是和类别不可知检测得分![]() 相乘的。这就要求一个强一阶段检测器不仅要最大化proposal的召回,也要对每个proposal预测一个可靠的目标概率。
相乘的。这就要求一个强一阶段检测器不仅要最大化proposal的召回,也要对每个proposal预测一个可靠的目标概率。
一阶段、两阶段、概率两阶段检测器区别见图2:

在我们的实验中,使用了强大的一阶段检测器来估计该对数似然,下一节将描述之。
5、构造一个概率的两阶段检测器
概率两阶段检测器的组成主要部分是强大的第一阶段,其需要预测一个准确的目标概率用于整体预测,而不是仅仅考虑召回。本文在四种不同的一阶段检测器上进行了实验,对每一个都重点列出了设计要素。
RetinaNet和传统两阶段检测器中的RPN很像,但其有三个不同之处:更重量级的head设计(4层vsRPN的1层)、更严格的正负例定义、以及Focal Loss。这三个不同点均增加了RetinaNet产生校准的一阶段检测概率的能力。我们在第一阶段的设计中,对这三点全部采纳。另外,RetinaNet默认使用了两个分类的head,分别进行边框回归和分类,而在我们的第一阶段设计中,我们发现使用一个单一的共享head进行两个任务也是足够的,因为仅判断目标是否属于背景非常简单且对网络能力的需求更少,这也加速了推理过程。
CenterNet通过定位目标中心点来找到目标,然后回归器边框的参数(宽和高)。原始的CenterNet在单尺度层面进行处理,而传统两阶段检测器使用了特征金字塔(FPN)。我们使用FPN对CenterNet进行升级,使之成为多尺度。具体得,我们使用RetinaNet类型的ResNet-FPN作为backbone,输出步幅为8到128(也即P3~P7)。我们对FPN所有层级应用了4层的分类分支和回归分支,来生成检测heatmap和边框回归map。在训练时,我们在固定范围内根据目标尺寸将GT中心点分配给特定的FPN层级。受GFL启发,我们将中心点的3*3邻域中也产生高质量(回归loss<0.2)边框的位置也作为正例。我们使用边界距离来表示边界框,并使用gIOU loss作为边框回归的损失函数。这种基于CenterNet设计的概率两阶段检测器命名为CenterNet*。
ATSS为每个对象使用自适应IoU阈值对一级检测器的分类可能性建模,并使用中心度校准分数。在概率两阶段检测baseline中,我们使用原始的ATSS,并对于每个proposal将其中心度和前景分类得分相乘。我们再次融合了分类和回归head,以稍微加速。
GFL使用回归之类来指导目标似然训练。在一个概率两阶段检测baseline中,为了保持一致性,我们移除了基于积分的回归并仅使用基于距离的回归并再次任何两个head。
以上几种一阶段结构都推断出了![]() ,然后都和第二阶段结合起来推断
,然后都和第二阶段结合起来推断![]() 。第二阶段选用了两种设计:Faster RCNN和Cascade RCNN。
。第二阶段选用了两种设计:Faster RCNN和Cascade RCNN。
超参:
两阶段检测器通常使用FPN的P2~P6层级(输出步幅为4~64),而大多一阶段检测器使用FPN的P3~P7层级(输出步幅为8~128)。为了兼容两者,我们使用P3~P7。我们增大了正例IOU阈值,对Faster RCNN从0.5调整为0.6(对于CascadeRCNN调整为0.6,0.7,0.8),以补偿第二阶段IOU分布的改变。我们在概率二阶段检测器中使用最多256个proposal,而在基于RPN的模型中则默认使用1K个proposal。我们在概率两阶段检测器中同样增大了NMS阈值,从0.5调整到0.7,因为我们的proposal数量更少。这些超参的改变对于概率检测器很有必要,但我们实验发现它们对于基于RPN的检测器却没有提高。
代码的实现是基于detectron2的,并在模型设置方面遵循了其标准。具体得,我们使用SGD优化器对网络迭代90K,基础学习率方法两阶段检测器为0.02、一阶段检测器为0.01,并在60K和80K迭代次数时缩小10倍。使用了多尺度训练,短边范围为[640, 800],长边最高1333。在训练阶段,我们设置一阶段检测器的损失权重为0.5,因为其学习率为0.01(相比两阶段0.02的学习率小一倍,所以损失也不能更新太多)。在测试阶段,我们设置短边固定800,长边最长1333。
我们对概率两阶段检测器实例化了四个不同的backbone。我们使用默认的ResNet50模型进行大多消融及对比实验;使用ResNeXt-32x8d-101-DCN和SOTA方法进行比拼性能;使用轻量的DLA设计实时模型;使用一些最新的技术设计一个超大backbone来获取高精度。
6、结果






7、结论
我们开发了一个两阶段目标检测的概率性解释,这种解释激发了我们使用一个强一阶段检测器来学校目标似然估计,而不是像RPN那样最大化召回。这些似然随后和第二阶段的分类得分结合,为最终的检测产生原则性概率得分。这种组合的概率两阶段检测器比起其组成部分(一阶段检测器、两阶段检测器)更快、更好。我们的工作为集成一阶段、两阶段检测器以达到速度和精度齐飞铺平了道路。