sparkstreaming实时接收rabbitmq的数据(包含scala以及pyspark版本)
目录
背景
1:scala版本
2:pyspark版本
注意:以下都是采坑点
RabbitMQ启用MQTT功能
背景
平常我们会实时监听kafka的数据,并且与流处理框架比如sparkstreaming和flink进行连接进行消费处理,这一套非常成熟且有官方工具包。但是目前有业务场景需要接收rabbitmq的数据,这就比较麻烦了,因为不想kafka有直接的kafkautils能创建流。
在sspark1.6以前的版本有mqtt这个模块,里面有MQTTutils这个工具类是可以直接创建rabbitmq数据流的
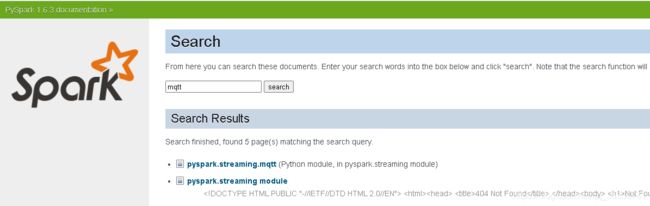
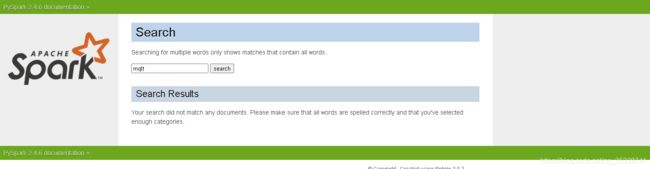
现有的spark版本已经不支持直接创建rabbit数据流。所以想要实现该功能可以降低spark版本,或者采用方案2
1:scala版本
maven依赖如下,spark版本为1.6.3
com.stratio.receiver
spark-rabbitmq_1.6
0.4.0
连接spark代码如下
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("1")
conf.setMaster("local[2]")
val ssc = new StreamingContext(conf,Duration(3000))
val stream = RabbitMQUtils.createStream(ssc,Map(
"hosts"-> "localhost",
"port" -> "5672",
"queueName" -> "hello",
"exchangeName" -> "",
"userName" -> "guest",
"password" -> "guest",
"durable"-> "false"
))
stream.print()
ssc.start()
ssc.awaitTermination()
}
2:pyspark版本
brokerUrl = "tcp://localhost:1883"
topic = "11" # all messages
env = EnvUtil.getEnv()
ssc = None
sparkSession = SparkSession.builder.master("local[2]").appName(
"test").getOrCreate()
ssc = StreamingContext(sparkSession.sparkContext,3)
if ssc is not None:
mqttStream = MQTTUtils.createStream(ssc, brokerUrl, topic,"guest","guest")
records = mqttStream.map(lambda line:line)
records.pprint()
ssc.start()
ssc.awaitTermination()
ssc.stop()
注意:以下都是采坑点
此处pyspark版本为2.4.6,按理说是没有mqtt模块的,没有MQTTUtils这个工具类,所以需要手工导入两个包
1:到maven仓库下载这两个包放到anaconda的安装目录下D:\setup\Anaconda\Lib\site-packages\pyspark\jars(这是我的anaconda安装pyspark目录)


2:在mqtt的包里面有一个工具类
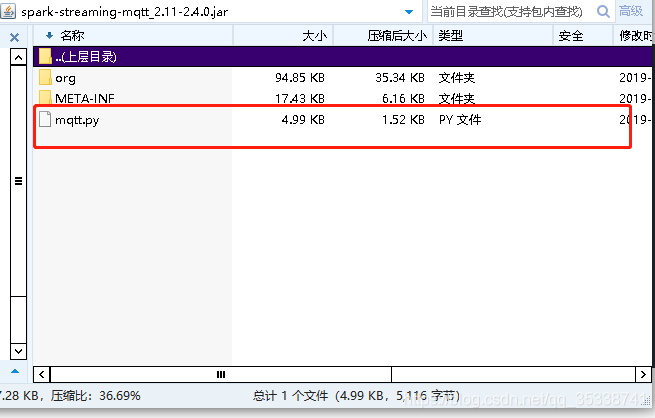
把这个代码拷出来放到项目里,然后就可以使用其中的mqttutils
3:还有就是rabbitmq的默认端口是5672为啥上面的brokerurl是
brokerUrl = "tcp://localhost:1883"是因为这个实时数据监听走的是mqtt协议所以要以tcp一些,因为安装在本地所以是localhost。至于为什么是1883,看下面介绍
RabbitMQ启用MQTT功能
RabbitMQ启用MQTT功能,需要先安装然RabbitMQ然后再启用MQTT插件。
- 首先我们需要安装并启动RabbitMQ
- 接下来就是启用RabbitMQ的MQTT插件了,默认是不启用的,使用如下命令开启即可;
rabbitmq-plugins enable rabbitmq_mqtt- 开启成功后,查看管理控制台,我们可以发现MQTT服务运行在
1883端口上了。

4:exchange只能发送到amq.topic不然监听不到,生产者代码如下
import pika
import random
# 新建连接,rabbitmq安装在本地则hostname为'localhost'
hostname = 'localhost'
parameters = pika.ConnectionParameters(hostname)
connection = pika.BlockingConnection(parameters)
# 创建通道
channel = connection.channel()
#exchange只能发送到amq.topic不然监听不到
channel.exchange_declare(exchange='amq.topic', exchange_type='topic', durable=True)
# 声明一个队列,生产者和消费者都要声明一个相同的队列,用来防止万一某一方挂了,另一方能正常运行
channel.queue_declare(queue='11')
number = random.randint(1, 1000)
body = '66'
# 交换机; 队列名,写明将消息发往哪个队列; 消息内容
# routing_key在使用匿名交换机的时候才需要指定,表示发送到哪个队列
channel.basic_publish(exchange='amq.topic', routing_key="11",body=body)
print(" [x] Sent %s" % body)
connection.close()