译:Two-stream convolutional networks for action recognition in videos
该篇文章为视频识别十分经典的一篇论文也是入门文章,开创了比较经典的双流(时间流+空间流)神经网络,本人发现很多大神博主翻译的论文不是特别完整,故按照原文与个人理解整理完整翻译见下。
摘要:我们研究了用于训练视频中行为识别的深度卷积网络架构。这个挑战是捕捉静态帧中的外观和连续帧间的运动的互补信息。我们也旨在推广这个在数据驱动的学习框架中表现得最好的手工特征。
本文一共做出了3个贡献:首先,本文一个包含空间和时间网络的双流ConvNet体系结构。其次,我们验证了,尽管是有限的训练数据集,在多帧密集光流上训练的卷积网络仍表现良好。最后,我们展示出,应用于两个不同的动作分类数据集的多任务学习,可以同时用来增加训练数据集的数量和提高性能。
我们的架构是在标准视频动作数据集UCF-101和HMDB-51上训练的,它们在竞争中处于领先地位。它也超出了先前大部分使用深度网络对视频进行分类的方法。
1、介绍
基于视频的人体动作识别是一项具有挑战性的任务,在学术界受到越来越多的关注[11,14,17,26]。与静态的图像分类相比,视频中的时间成分为识别提供了一个额外的(且是重要的)线索,因为一些行为是基于运动信息才能够被可靠地识别出来的。此外,对于单个图像(视频帧)分类,视频提供了自然的数据增强(抖动)。
在这项工作中,我们旨在将深层卷积网络(ConvNets)[19](一种最先进的静态图像表示[15])扩展到视频数据中的动作识别上。这个任务最近得到了解决[14],我们通过将堆叠的视频帧作为输入传入网络中,但是结果明显地比最好的手工制作的特征要差得多[20,26]。我们研究了基于两个单独的识别流(空间和时间)的不同架构,然后通过后期融合合并。空间流从静态的视频帧中执行行为识别,同时训练时间流从密集光流形式的运动中以识别行为。两个流都是用卷积网络来实现的。去耦合时空网络允许我们开发大量的已注释图像数据的可用性,这些数据是通过空间网络在ImageNet数据集上预训练出来的。我们提出的架构与two-streams假设有关,根据该假设,人类视觉皮质包含两条路径:腹侧流(识别目标)和背侧流(识别运动),尽管我们在这里没有进一步研究这种联系。
本文的其他部分组织如下:在1.1部分,我们回顾了有关使用浅层的、深层的架构的行为识别的相关工作。在第2部分,我们介绍了two-stream架构,并且详细介绍了空间卷积网络。在第3部分,介绍了时间卷积网络,特别是它如何概括了1.1节中所述的先前架构。在第4部分,提出多任务学习框架,使得多个数据集上的训练数据可以容易的组合。实现细节在第5部分给出。在第6部分进行评估,并与最先进水平进行了比较。我们在两个挑战性的数据集(UCF-101和HMDB-51数据集)上的实验表明两个识别流是互补的,并且我们的深度架构比Large-scale video classification with convolutional neural networks[14]这篇论文做的要好,并且尽管是在相对较小的数据集上训练,我们的深度架构与浅层表示[20,21,26]的最先进水平相比也是有竞争力的。
1.1 相关工作
视频识别研究很大程度上受到图像识别方法的推动,通常会对其进行修改和扩展以处理视频数据。很多视频行为识别的方法是基于局部时空特征的浅层、高维编码的。例如,Learning realistic human actions from movies[17]这篇论文提出的算法在检测稀疏时空兴趣点,可以描述为使用了局部时空特征:方向梯度直方图(HOG)和光流直方图(FOG)。然后这些特征被编码为Bag Of Features (BoF)表示,它汇集在了几个时空特征网格上(类似于空间金字塔池化),并且结合了SVM分类器。在一项最近的研究工作中表明[28],局部特征的密集采样要优于稀疏的兴趣点。
(浅层表示介绍) 最先进水平的浅层视频表征[20,21,26]利用了密集点轨迹,而不是在时空立方体上计算局部视频特征。这个方法第一次提出是在Instead of computing local video features over spatio-temporal cuboids[29]这篇论文中,这个方法调整了局部描述符支持域,他们使用了通过光流来计算的密集轨迹。基于轨迹方法的最好性能是由Motion Boundary Histogram (MBH)[8]实现的,这是一个基于梯度的特征,分别计算光流的水平和垂直分量。几个特征的结合表现出可以进一步提高性能。基于轨迹的手工特征最近的改进包括,全局摄像机动作补偿[10,16,26],和使用Fisher vector[22](in [26])编码或者是更深的变体[23](in [21])。
(深度架构介绍) 也有很多方法尝试从深度架构上进行视频识别。这些工作的大多数,网络的输入都是一堆连续的视频帧,因此,这些模型被期望能够在第一层隐式学习时空独立动作特征,这是一个困难的任务。在A biologically inspired system for action recognition[11]这篇论文中,提出了一种用于视频识别的HMAX架构,在第一层使用了预定义的时空滤波器(filter)。然后,在HMDB: A large video database for human motion recognition[16]这篇论文中,将其与空间HMAX结合,形成空间(类似于腹侧)和时间(类似于背侧)识别流。然而,这与我们的工作不同,它的流是手工制作实现的,而且是浅层(3层)的HMAX模型。在另外3篇论文中[4,18,25],一个卷积的RBM和ISA被用来无监督地学习时空特征,然后把它推入一个判别模型来进行行为分类。用于视频的卷积网络的端到端学习模型已经在论文3D convolutional neural networks for human action recognition[12]中实现,并且最近在论文Large-scale video classification with convolutional neural networks[14]中,比较了几个用于行为识别的卷积网络架构。训练是在一个非常大的Sports-1M数据集上实现的,它包含了110多万的YouTube的行为类别的视频。有趣的是,在这篇论文[14]中发现,一个在单个视频帧上运行的网络,与输入是一堆视频帧的网络的性能类似。这可能表明,学习到的时空特征不能很好的捕捉到行为信息。其学到的表示,在UCF-101数据集上微调后,其结果比手工制作的基于轨迹的表示最新技术精度低20%[20,27]。
我们的时间流卷积网络在多帧密集光流上运行,其通过解决位移场(特别是多个图像尺度)在一个能量最小化的框架中进行计算。我们使用了High accuracy optical flow estimation based on a theory for warping[2]中流行的方法,该方法基于强度及其梯度以及位移场的平滑度的恒定假设。最近,DeepFlow: Large displacement optical flow with deep matching[30]论文提出了一个图像块补丁匹配方案,这使人联想到深度卷积网络,但不包括学习。
2、用于视频识别的Two-stream架构
视频很自然的被拆解为空间和时间部分。在空间部分,以单个帧的外观形式,传递了视频描绘的场景和目标信息。在时间部分,以多帧的运动形式,传递了观察者(摄像机)和目标者的运动。我们相应地设计视频识别架构,如图1所示,将其分为两个流。每一个流都由一个深度卷积网络来实现,最后它们通过softmax进行融合。我们考虑了两种融合方法:一个是求平均; 另一个则是在多分类线性SVM上训练,使用L2正则化的softmax计算得分。
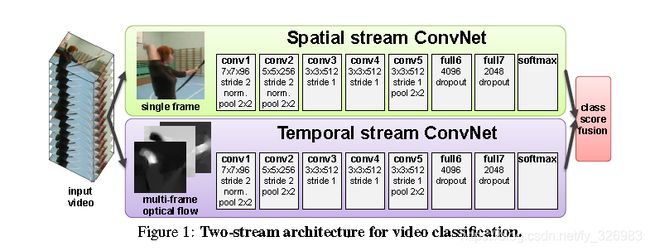
空间流卷积网络在单个视频帧上执行,能有效地在静止图像中进行动作识别。其静态外观本身就是一个有用的线索,因为有些动作是与特定对象紧密相关。 事实上,如第6部分所述,静态帧(空间识别流)的动作识别相对其自身是有竞争力的。由于空间流卷积网络本质上是一个图像分类架构,我们可以依赖于最近的ImageNet classification with deep convolutional neural networks[15]论文中提出的大型图像识别方法,在大型图像分类数据集上(例如ImageNet挑战数据集)预训练网络。细节在第5部分给出,接下来我们描述一个时间流卷积网络,其开发了运动信息,明显地提高了准确率。
3、光流卷积网络
在这一部分,我们描述一个卷积网络模型,该模型形成了我们提出的two-stream架构(见第二部分)中的时间识别流。不同于1.1中回顾的卷积网络模型,我们模型的输入是几个相邻帧之间叠加的光流位移场。这样的输入准确地描述了视频帧之间的运动信息,这使得识别更加容易,并且网络不需要估计隐式的运动。我们考虑了几个基于光流输入的变体,如下描述所示。

图2:光流
- (a)(b):一对连续视频帧,用青色矩阵画出移动手的区域。
- (c):在大部分区域的密集光流的特写。
- (d):位移矢量场(强度高相当于正值,强度低相当于负值)的水平分量dx。
- (e):垂直分量dy。
注意d和e是如何突出移动的手和弓。卷积网络的输入包含了多个流(见3.1部分)。
3.1 卷积网络的输入配置
光流叠加。 一个密集光流可以看作是在连续的帧t和帧t+1之间的一组位移矢量场dt。我们用dt(u,v)表示在帧t的位置(u,v)的位移矢量,它表示移动到下一个帧t+1相对应的点。矢量场的水平和垂直部分分别是dtx和dty,可以视为图像的通道(如图2所示),十分适合使用卷积网络来识别。为了表示一系列帧之间的运动,我们叠加了L个连续帧的光流通道dtx和dty,形成了2L长度的输入通道。更正式的说,设定w和h是视频的宽和高,对于任意帧τ,卷积网络输入容量:
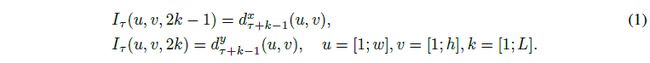
对于任意点(u.v),通道Iτ(u,v,c),c = [1; 2L]编码该点的运动在一系列L帧上(如图3左所示)。
轨迹叠加。 受轨迹描述子的启发[29],另一个可供选择的运动表示代替了光流叠加,沿着运动轨迹,在几个帧的相同位置采样。在这个情形下,与帧τ对应的输入容量Iτ,采取下列形式:

其中pk是沿着轨迹的第k个点,开始于帧τ的(u,v)位置,并且用以下递归方式定义:
![]()
比较于输入容量表示(1),其通道Ιτ(u,v,c)存储了(u,v)位置的位移矢量,而在输入容量(2)中,则存储了沿着轨迹(如图3右图所示)在位置pk抽样的矢量。
图3: 卷积网络从多帧光流中的输入。左:光流叠加在连续多帧的同一个位置的采样位置矢量。右:轨迹叠加沿着轨迹采样矢量。帧和与之相对应的位移矢量都用相同的颜色表示。

双向光流。 光流表示1和2处理了正向光流,也就是帧t的位移场dt指定了在下一帧t+1处像素的位置。自然地扩展到双向光流,通过在相反的位置计算一个额外的位移场集合来获得。我们接着构建了输入容量Ιτ,通过叠加帧τ到帧τ+L/2之间共L/2个前向流和帧τ-L/2到帧τ至今的L/2个后向流。输入Ιτ因此与之前的通道(2L)有相同的数量。光流可以使用方法1和方法2中其中任一个来表示。
减去平均光流。 这有利于处理中心为0的网络输入,允许模型更好的处理纠正非线性。在我们的案例中,位移矢量场分量可以同时具有正值和负值,自然地集中在各种各样的运动中,一个方向上的运动与相反的运动。然而,对给定一对框架,它们之间的光流可以由特定的位移来控制,例如由相机的运动引起。摄像机运动补偿的重要性已经在先前的论文[10,26]中明显地提出过,从密集光流中估计并减去全局运动分量。在我们的案例中,我们考虑一个更简单的方法:在每一个位移场d中都减去它的均值矢量。
架构。上面我们描述了不同的方法来结合多种光流位移场到单个容量 。考虑到卷积网络要求固定尺寸的输入,我们从Ιτ中采样了224x224x2L个副容量,并将其传递给网络作为输入。隐藏层的配置大部分保留了空间卷积中使用的配置,如图1所示。测试也类似于空间卷积网络,细节在第5部分给出。
3.2 时间卷积网络架构与先前表示的关系
在这一部分,我们将我们的时间卷积网络架构放在1.1部分回顾的先前技术的环境下,并与视频表示形式进行连接。基于特征编码的方法[17,29]结合了几个时空局部特征。这种特征是通过光流计算的,并由我们的时间卷积网络来推广。事实上,HOF和MBH局部描述子是基于光流方向或者梯度的直方图,可以通过位移场的输出由单个卷积层(包含对方向敏感的滤波器)来获得,接下来是正则化和池化层。运动学上的特征(散度、旋度和裁剪)也可以通过光流梯度来计算,同样,也可以通过卷积模型来捕获。最后,轨迹特征通过叠加沿着轨迹的位移矢量计算获得,相当于轨迹叠加。在3.3部分,我们可视化了从时间网络第一层学到的卷积滤波器。这提供了进一步的证据,表明我们的表示具有手工制作的特征。
就深度网络而言,HMDB: A large video database for human motion recognition[16]论文中一个two-stream视频识别架构包含了两个HMAX模型,这些模型是手工制作的,并且比我们的判别式训练模型的深度要浅一点。这可以看多是HMAX一个可学习的概括。另外两篇论文中[12,14],并没有分离时间和空间识别流,而是依赖于从数据中学到的运动敏感卷积滤波器。在我们的案例中,运动被明确表示使用光流位移场来表示,该场基于亮度不变性的假设和光的平滑性来计算的。将这些假设纳入ConvNet框架中,也许能够提高基于端到端基于ConvNet的方法的性能,这是未来研究一个有趣的方向。
3.3学习卷积滤波器的可视化

图4:从10个堆叠的光流中获悉的第一层卷积滤波器。 可视化分为96列和20行:每列对应一个过滤器,每行–输入渠道。
在图4中,我们可视化了在UCF-101数据集上经过训练的时间ConvNet第一层的卷积滤波器。 96个滤镜中的每个滤镜都有7×7像素的空间接收场,并且具有20个输入通道,对应于水平(dx)和垂直(dy)10个堆叠的组件光流位移场d。
可以看出,一些过滤器计算光流的空间导数,捕获运动随图像位置的变化,从而概括了基于导数的手工描述符(例如MBH)。 其他过滤器计算时间导数,以捕获运动随时间的变化。
4、多任务学习
不同于空间流卷积网络,它可以在大量静止图像数据集(例如ImageNet数据集)上进行预训练,时间卷积网络需要在视频数据集上训练,对于视频动作识别可用的数据集非常少。在我们的实验(第6部分)中,在UCF-101和HMDB-51数据集上训练,分别只有9500和3700个视频。为了减少过拟合,考虑将两个数据集结合成一个,然而由于类集之间的交集,这并不简单。一个选项(稍后我们将对此进行验证)是从类别中添加没有出现在原始数据集的图像。然而,这要求对每个类别进行人工检索,并且限制了可训练数据的数量。
一个更强的结合数据集的方法是基于多任务学习。它旨在学习(视频)表示法,不仅可以适用于有关任务(例如HMDB-51分类),也适用于其他任务(如UCF-101分类)。额外的任务充当规则者,并允许利用额外的训练任务。在我们的案例中,对ConvNet架构进行了修改,在最后一层全连接层的顶部有两个softmax分类层,一个softmax计算HMDB-51分类的分数,另一个计算UCF-101的分数。每一层都配有自己的损失函数,只在各自数据集的视频数据上操作。总体的训练损失被计算为单个任务损失的总和,通过后向传播计算网络权重。
5、实现细节
卷积网络配置。 我们的空间和时间卷积网络的每一层配置如图1所示。它对应于Return of the devil in the details: Delving deep into convolutional nets[3]论文中的CNN-M-2048架构,类似于Visualizing and understanding convolutional networks[31]论文中的网络。 所有隐藏的权重层都使用了RELU激励函数;池化层使用最大池化,窗口为3X3,步长为2;局部反应归一化使用如ImageNet classification with deep convolutional neural networks[15]论文中的设置。在空间和时间卷积网络中唯一不同的配置是我们去除了时间网络中第二次归一化,以便减少内存消耗。
训练。 训练流程可以视为是对ImageNet classification with deep convolutional neural networks[15]相对于视频帧的一个改动,并且对时间和空间网络都是相同的。使用mini-batch随机梯度下降(其动量为0.9)学习网络权重。在每个迭代中,一个mini-batch含有256个样本,通过采样256个训练视频(对每个类别都一致)获得,其中的单个帧都是随机选择的。在空间网络训练时,从选择的帧中随机截取224x224的子图;然后对其进行随机水平翻转和RGB抖动。视频事先经过调整,因此帧最小的边等于256。我们与ImageNet classification with deep convolutional neural networks不同,子图是从整个帧中采样的,而不是选取了256x256的中心。在时间网络训练时,我们对在第3部分描述的每一个选择的训练帧,计算了光流容量Ι。从这个容量中,随机裁剪和翻转一个固定尺寸224x224x2L的输入。学习速率初始化为0.01,然后根据固定的顺序减少,在所有的训练集上都保持相同。也就是说,当从头训练一个卷积网络时,在5万次迭代后速率给变为0.001,在7万次迭代后速率变为0.0001,最终在8万次迭代后训练停止。在微调阶段,在14000次迭代后速率变为0.001,在2万次迭代后训练停止。
测试。 在测试时,对于给定视频,我们采样了固定数量(在我们的实验中是25)的帧,这些帧之间的时间间隔相等。对于其中的每个帧,通过裁剪和翻转帧的四个角和中心,我们获得了卷积网络的10个输入[15]。对于整个视频的类别分数,通过计算每个帧和翻转后的帧的分数平均来得到。
在ImageNet ILSVRC-2012上预训练。当预训练空间卷积网络时,我们使用与向前描述同样的数据增加方式(裁剪、翻转、RGB抖动)。在ILSVRC-2012验证数据集上获得了13.5%的top5误差,在Visualizing and understanding convolutional networks[31]论文中类似的网络得到了16%的误差。我们相信改进的主要原因是卷积网络的采样输入是来自于整个图像,而不是仅从其中心采样ConvNet输入。
多GPU训练。 我们是在公共工具CAFFE上实现的[13],但包含许多重大修改,包括在多个GPU上并行训练,而不是在一个系统下训练。我们利用数据并行性,将每个SGD批处理为多个GPU。训练单个时间卷积网络,在一个有4个NVIDIA显卡的系统上要花费1天,这比单GPU的训练快了3.2倍。
光流。 使用opencv工具中现成的GPU来实现计算[2]。尽管计算时间很快(每对帧0.06秒),但在实际运行时仍然是一个瓶颈,因此我们在训练前提前计算了光流。为了避免存放位移场为浮点,光流的水平和垂直分量呈线性扩展到[0,255]的范围(解压缩后,对流进行重新缩放回到原始范围),并使用了JPEG进行了压缩。这将UCF-101数据集光流的大小从1.5TB减少到了27GB。
6、验证
数据集和验证协议。 验证是在UCF-101[24]和HMDB-51[16]的动作识别基准进行的,这是最大的可用注释视频数据集1之一。UCF-101包含了13000个视频(每个视频平均有180帧),被分为101个类别。HMDB-51数据集包含了6800个视频,共51个类别。两个数据集的验证协议是相同的:组织者将数据集分成了3个分片,训练数据、测试数据和计算平均分类正确度的性能的分片。每一个UCF-101分片都包含了9500个训练视频;一个HMDB-51分片包含3700个训练视频。我们首先在UCF-101数据集的第一个分片上比较了不同的架构。对于与先进水平的比较,我们遵循标准的验证协议,各自在UCF-101和HMDB-51的3个分片上计算了平均准确度。
空间卷积网络。 首先,我们测量了空间流卷积网络的准确性。考虑以下3个情境:(1)在UCF-101数据集上从头训练。(2)在ILSVRC-2012预训练后,在UCF-101上进行微调。(3)保持预训练网络固定,只训练最后一层(分类)。对于每一个设置,我们都通过dropout正则化率0.5到0.9进行了实验。结果展现在表1(a)中,很明显,单独的在UCF-101数据集上训练导致了过拟合(即使是很高的dropout),并且要差于在ILSVRC-2012数据集上的预训练。有趣的是,微调整个网络仅比训练最后一层稍微好那么一点。在下面的实验中,我们选择只训练预训练卷积网络前的最后一层。

时间卷积网络。 在已经验证了空间卷积网络的变体之后,我们现在转向时间网络架构,评定了如3.1部分描述的输入配置的影响。特别地,我们计算了以下效果:使用多个(L={5,10})叠加光流;轨迹叠加;平均位移差;使用双向光流。架构在UCF-101数据集上从头训练,因此我们使用了dropout正则化率0.9来提高泛化能力,结果在表1(b)中显示。首先,我们可以推断,在输入中叠加多个(L>1)位移场是非常有效的,因为它提供给网络长远的动作信息,比一个帧对(L=1)的光流更有区别性。输入流的数量从5提高到10导致了一个较小的改进,因此我们在接下来的实验中将L固定为10。第二,我们发现平均消去是有用的,它减少了帧间的全局动作的影响, 我们在接下来的实验中默认使用。不同叠加技术上的区别是较小的;结果是光流叠加比轨迹叠加的效果要好,并且使用双向光流要比使用单向前向光流好一点点。最后,我们注意到,时间卷积网络明显优于空间卷积网络(表1a),这证实了在动作识别中运动信息的重要性。
我们还实现了[14]的“慢融合”架构,这相当于运用了一组RGB帧到卷积网络中(本例中为11帧)。当从头训练UCF-101数据集时,实现了56.4%的准确率,这比从头训练单帧架构要好(52.3%),但距离光流从头开始训练的网络仍然相距甚远。这表明了多帧信息的重要性,同样重要的是以一种合理的方式呈现给卷积网络。
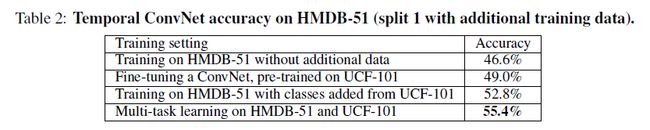
时间卷积网络的多任务学习。由于训练集较小,在UCF-101数据集上训练时间卷积网络是比较有挑战性的。一个更大的挑战是在HMDB-51数据集上训练卷积网络,每个训练片比UCF-101小了2.6倍。这里,我们验证了用于增加HMDB-51的有效训练集大小不同的选项:(1)微调在UCF-101上预训练的时间网络;(2)从UCF-101中添加78个通过手工筛选的类别,因此,这些类与本机HMDB-51类之间不会有交集;(3)使用多任务规划(第4部分所述),以学习视频表示形式,在UCF-101和HMDB-51分类任务上共享。结果展示在表2中。如预期的那样,使用全部的(所有分片结合)UCF-101数据来训练(不管是借用图像还是隐式地预训练)是有用的。 多任务学习表现最佳,因为它允许训练过程中利用所有可用的训练数据。
我们还通过训练网络对UCF-101数据集进行了多任务学习实验
同时对完整的HMDB-51数据(所有分片结合)和UCF-101数据(单个分片)进行分类。在UCF-101的第一个分片上,准确率为81.5%,之前同样的设置实现了81.0%,但无需执行其他HMDB分类任务(表1b)。
Two-stream卷积网络。 这里我们验证了完整的two-stream模型,其结合了两个识别流。结合网络的一个方法是,在两种网络的6层或7层后,训练一个全连接层共同的叠加。然而在我们的情境下这样是不可行的,会导致过拟合。因此,我们使用平均或线性SVM融合Softmax分数。从表3中我们可以得出结论: (1)时间和空间识别流是互补的,他们的融合明显的提高了彼此(时间网络上提高了6%,空间网络上提高了14%)。(2)基于SVM的softmax计分融合要比平均融合做的要好。(3)使用双向流对于卷积网络的情况没有益处。(4)使用多任务训练的时间卷积网络要比单独或者是融合一个空间网络的性能都要好。

与最先进水平的对比。 通过在UCF-101和HMDB-51的3个分片上进行了与最先进水平的比较,总结了实验的验证。我们使用了一个在ILSVRC预训练的空间网络,其最后一层是在UCF或HMDB上训练的。时间网络是在UCF或HMDB上使用多任务训练的,输入是使用平均消去的单向光流叠加计算的。两个网络的softmax分数会使用平均或者SVM来计算。在表4中可以看到,我们单独的的空间和时间网络都比另外两篇论文[14,16]中的深度网络要大幅度提高很多。两个网络的结合进一步提高了结果(与上面在单个分片上的结果一致),堪比最近最先进水平的手工制作模型。

混合矩阵和每类UCF-101分类的召回率。在图5中,我们显示了使用我们的两流模型进行UCF-101分类的融合矩阵,在第一个数据集拆分上(表3的最后一行)其准确度达到87.0%。 我们还可视化了图6中相应的每类召回。最差的召回类别对应于Hammering类别,后者与Head Massage和Brushing Teeth类。 我们发现这是由于两个原因。 首先,空间卷积网络弄混了Hammering 和 Head Massage,这可能是由于在两个类中人脸的大量存在造成的。 其次,时空的卷积网络将Hammering与Brushing Teeth混淆了,因为两者动作包含重复的动作模式(手向上和向下移动)。

7、结论和改进方向
我们提出一个深度视频识别模型,其性能具有竞争性,它分别由基于卷积网络的时间和空间识别流组成。目前,在光流上训练时间卷积网络要比在原始连续帧上训练要好的多[14]。后者或许更具有挑战性,可能需要更改架构(比如,与DeepFlow: Large displacement optical flow with deep matching[30]论文的深度匹配方法结合)。尽管使用光流作为输入,我们的时间模型并不需要大量的手工制作,因为光流可以使用基于通用的不变性假设和平滑性来计算得到。
正如我们所展示的,额外的训练数据对我们的时间卷积网络是有益的,因此我们计划在大型数据集上训练它,例如Large-scale video classification with convolutional neural networks[14]论文最近发布的数据集。然而,由于这是一个庞大的数据集(TB以上)所以是一个巨大的挑战。
我们的网络仍然错过了一些最先进水平的浅层表示的有用材料[26]。最突出的一个就是,以轨迹为中心,在时空管道上的局部特征池化。即使是输入(2)沿着轨迹捕捉了光流,在我们的网络中空间池化并没有将轨迹考虑在内。另一个潜在的改进可能是摄像机运动的明确处理,在我们的实验中使用了平均位移消去法进行了补偿。

参考文献
[1] A. Berg, J. Deng, and L. Fei-Fei. Large scale visual recognition challenge (ILSVRC), 2010. URL
http://www.image-net.org/challenges/LSVRC/2010/.
[2] T. Brox, A. Bruhn, N. Papenberg, and J. Weickert. High accuracy optical flflow estimation based on a theory for warping. In Proc. ECCV, pages 25–36, 2004.
[3] K. Chatfifield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC., 2014.
[4] B. Chen, J. A. Ting, B. Marlin, and N. de Freitas. Deep learning of invariant spatio-temporal features from video. In NIPS Deep Learning and Unsupervised Feature Learning Workshop, 2010.
[5] R. Collobert and J. Weston. A unifified architecture for natural language processing: deep neural networks with multitask learning. In Proc. ICML, pages 160–167, 2008.
[6] K. Crammer and Y. Singer. On the algorithmic implementation of multiclass kernel-based vector machines. JMLR, 2:265–292, 2001.
[7] N. Dalal and B Triggs. Histogram of Oriented Gradients for Human Detection. In Proc. CVPR, volume 2, pages 886–893, 2005.
[8] N. Dalal, B. Triggs, and C. Schmid. Human detection using oriented histograms of flflow and appearance. In Proc. ECCV, pages 428–441, 2006.
[9] M. A. Goodale and A. D. Milner. Separate visual pathways for perception and action. Trends in Neurosciences, 15(1):20–25, 1992.
[10] M. Jain, H. Jegou, and P. Bouthemy. Better exploiting motion for better action recognition. In Proc. CVPR, pages 2555–2562, 2013.
[11] H. Jhuang, T. Serre, L. Wolf, and T. Poggio. A biologically inspired system for action recognition. In Proc. ICCV, pages 1–8, 2007.
[12] S. Ji, W. Xu, M. Yang, and K. Yu. 3D convolutional neural networks for human action recognition. IEEE PAMI, 35(1):221–231, 2013.
[13] Y. Jia. Caffe: An open source convolutional architecture for fast feature embedding. http://caffe. Berkeley vision.org/, 2013.
[14] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classififi- cation ith convolutional neural networks. In Proc. CVPR, 2014.
[15] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classifification with deep convolutional neural networks. In NIPS, pages 1106–1114, 2012.
10[16] H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. HMDB: A large video database for human motion recognition. In Proc. ICCV, pages 2556–2563, 2011.
[17] I. Laptev, M. Marszałek, C. Schmid, and B. Rozenfeld. Learning realistic human actions from movies. In Proc. CVPR, 2008.
[18] Q. V. Le, W. Y. Zou, S. Y. Yeung, and A. Y. Ng. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In Proc. CVPR, pages 3361–3368, 2011.
[19] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
[20] X. Peng, L. Wang, X. Wang, and Y. Qiao. Bag of visual words and fusion methods for action recognition:
Comprehensive study and good practice. CoRR, abs/1405.4506, 2014.
[21] X. Peng, C. Zou, Y. Qiao, and Q. Peng. Action recognition with stacked fifisher vectors. In Proc. ECCV, pages 581–595, 2014.
[22] F. Perronnin, J. S anchez, and T. Mensink. Improving the Fisher kernel for large-scale image classifification.
In Proc. ECCV, 2010.
[23] K. Simonyan, A. Vedaldi, and A. Zisserman. Deep Fisher networks for large-scale image classifification. In NIPS, 2013.
[24] K. Soomro, A. R. Zamir, and M. Shah. UCF101: A dataset of 101 human actions classes from videos in the wild. CoRR, abs/1212.0402, 2012.
[25] G. W. Taylor, R. Fergus, Y. LeCun, and C. Bregler. Convolutional learning of spatio-temporal features. In Proc. ECCV, pages 140–153, 2010.
[26] H. Wang and C. Schmid. Action recognition with improved trajectories. In Proc. ICCV, pages 3551–3558, 2013.
[27] H. Wang and C. Schmid. LEAR-INRIA submission for the THUMOS workshop. In ICCV Workshop on Action Recognition with a Large Number of Classes, 2013.
[28] H. Wang, M. M. Ullah, A. Kl aser, I. Laptev, and C. Schmid. Evaluation of local spatio-temporal features for action recognition. In Proc. BMVC., pages 1–11, 2009.
[29] H. Wang, A. Klaser, C. Schmid, and C.-L. Liu. Action recognition by dense trajectories. In Proc. CVPR, pages 3169–3176, 2011.
[30] P. Weinzaepfel, J. Revaud, Z. Harchaoui, and C. Schmid. DeepFlow: Large displacement optical flflow with deep matching. In Proc. ICCV, pages 1385–1392, 2013.
[31] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. CoRR, abs/1311.2901, 2013.