Scaled-YOLOv4: Scaling Cross Stage Partial Network 论文翻译
Scaled-YOLOv4: Scaling Cross Stage Partial Network论文翻译
-
-
- 摘要
- 1.介绍
- 2.相关工作
-
- 2.1 实时检测器
- 2.2 模型缩放
- 3.模型缩放的原则
-
- 3.1 模型缩放的常规原则
- 3.2 为低端设备缩放tiny模型
- 3.3 为高端设备缩放Large模型
- 4. Scaled-YOLOv4
-
- 4.1 CSP-ized YOLOv4
- 4.2 YOLOv4-tiny
- 4.3 YOLOv4-large
- 5.实验
-
- 5.1 CSP化模型的消融实验
- 5.2 YOLOv4-tiny的消融实验
- 5.3 YOLOv4-large的消融研究
- 5.4 用于目标检测的Scaled-YOLOv4
- 5.5 Scaled-YOLOv4 是一个简单的once-for-all 模型
- 6.结论
- 参考文献
-
论文地址:Scaled-YOLOv4: Scaling Cross Stage Partial Network
摘要
实验结果表明,基于CSP方法的YOLOv4目标检测神经网络在保持最优速度和准确率的前提下,具有向上/向下可伸缩性,可用于不同大小的网络。我们提出了一种网络缩放方法,它不仅改变深度、宽度、分辨率,而且还改变网络的结构。YOLOv4-large模型实现了SOTA的结果:在Tesla V100上,以15 FPS的速度对MS COCO数据集实现了55.4% AP (73.3% AP50),而伴随着TTA,YOLOv4-large实现了55.8% AP (73.2 AP50)。YOLOv4-tiny模型在RTX 2080Ti上以443 FPS的速度实现22.0% AP (42.0% AP50),而使用TensorRT,batch-size= 4和fp16精度YOLOv4-tiny实现1774 FPS。

1.介绍
基于深度学习的目标检测技术在我们的日常生活中有着广泛的应用。例如,医学图像分析、自动驾驶汽车、商业分析和人脸识别都依赖于对象检测。上述应用程序所需的计算设施可能是云计算设施、通用GPU、物联网集群或单个嵌入式设备。为了设计一种有效的目标探测器,模型缩放技术是非常重要的,因为它可以使目标检测器对各种类型的设备实现高精度和实时推断。
最常用的模型缩放技术是改变骨干的深度(一个CNN中卷积层的数量)和宽度(一个卷积层中卷积滤波器的数量),然后训练适合不同设备的CNN。例如ResNet[10]系列中,ResNet-152和ResNet-101经常用于云服务器gpu, ResNet-50和ResNet-34经常用于个人计算机gpu, ResNet-18和ResNet-10可以用于低端嵌入式系统。在[2]中, Cai等人尝试开发只需训练一次即可应用于各种设备网络架构的技术。它们利用解耦训练、搜索和知识蒸馏等技术对多个子网络进行解耦和训练,使整个网络和子网络能够处理目标任务。Tan等人[30]提出使用NAS技术进行复合缩放,包括在EfficientNet-b0上处理宽度、深度和分辨率。他们利用这个初始网络搜索给定计算量的最佳CNN架构,将其设为EfficientNet-B1,然后利用线性缩放技术得到EfficientNet-B2到EfficientNet-B7这样的架构。Radosavovic等[23]从浩瀚的参数搜索空间AnyNet中总结并添加约束,设计了RegNet。在RegNet中,他们发现CNN的最佳深度约为60。他们还发现,当瓶颈比设置为1,跨stage的宽度增加率设置为2.5时,性能最好。另外,最近有专门为目标检测而提出的NAS和模型缩放方法,如SpineNet[5]和EfficientDet[31]。
通过对目前最先进的目标检测器[1,3,5,22,31,36,40]的分析,我们发现YOLOv4[1]的主干CSPDarknet53几乎匹配所有通过网络架构搜索技术得到的最优架构特征。CSPDarknet53的深度、瓶颈比、跨stage宽度生长比分别为65、1和2。因此,我们开发了基于YOLOv4的模型缩放技术,提出了scale -YOLOv4。提出的缩放yolov4具有出色的性能,如图1所示。scale - yolov4的设计过程如下。首先对YOLOv4进行了重新设计,提出了YOLOv4- csp,然后在YOLOv4- csp的基础上开发了scale -YOLOv4。在提出的scale - yolov4中,我们讨论了线性缩放模型的上界和下界,并分别分析了小模型和大模型缩放时需要注意的问题。因此,我们能够系统地开发YOLOv4-large和YOLOv4-tiny模型。Scaled-YOLOv4能够在速度和精度之间实现最好的平衡,能够在15 fps、30 fps和60 fps的影片以及嵌入式系统上进行实时的检测。
我们总结了本文的工作:
- 设计了一种针对小模型的强大的模型缩放方法,系统地平衡了浅层CNN的计算代价和存储带宽;
- 设计一种简单有效的大型目标检测器缩放策略;
- 分析各模型缩放因子之间的关系,基于最优组划分进行模型缩放;
- 实验证实了FPN结构本质上是一种once-for-all结构;
- 利用上述方法研制了YOLOv4-tiny和YOLO4v4-large。
2.相关工作
2.1 实时检测器
目标检测器主要分为 one-stage目标检测器[24,25,26,18,16,20]和two-stage目标检测器[9,8,27]。只需一次CNN操作就可以得到one-stage目标检测器的输出。对于two-stage目标检测器,通常将第一阶段CNN得到的高分区域建议输入到第二阶段CNN进行最终预测。one-stage目标检测器和two-stage目标检测器的推理时间可以表示为Tone = T1st和Ttwo = T1st + mT2,其中m为置信分数高于阈值的区域建议的数量。换句话说,one-stage检测器所需的推理时间是固定的,而two-stage检测器所需的推理时间不是固定的。所以如果需要实时的检测器,它们几乎都是one-stage目标检测器。目前流行的one-stage目标检测器主要有两种:anchor-based[26,16]和anchor-free的[6,12,13,32]。在所有anchor-free方法中,CenterNet[42]非常流行,因为它不需要复杂的后处理,如非最大抑制(NMS)。目前,更准确的实时one-stage目标检测器是anchor-based的EfficientDet[31]、YOLOv4[1]、PP-YOLO[19]。在本文中,我们开发了基于YOLOv4[1]的模型缩放方法。
2.2 模型缩放
传统的模型缩放方法是改变模型的深度,即增加更多的卷积层。例如,Simonyan等人设计的VGGNet[28]在不同的阶段叠加了额外的卷积层,并使用这个概念设计了vgg11、vgg13、vgg16、vgg19架构。后续的方法通常遵循相同的模型缩放方法。对于He等人提出的ResNet[10],扩展深度可以构建非常深的网络,如ResNet-50、ResNet-101和ResNet-152。后来Zagoruyko等人[39]考虑到了网络的宽度,他们改变了卷积层核的数量来实现缩放。因此,他们设计了wide ResNet (WRN),同时保持同样的精度。虽然WRN的参数量比ResNet大,但推理速度要快得多。随后的DenseNet[11]和ResNeXt[37]也设计了一个复合缩放版本,将深度和宽度考虑在内。对于图像金字塔推理,在运行时进行增强是一种常用的方法,它取一个输入图像,做各种不同的分辨率缩放,然后输入这些不同的金字塔组合到一个训练好的CNN,最后,网络将多组输出整合为最终结果。Redmon等人[26]使用上述概念来执行输入图像的大小缩放。他们使用更高的输入图像分辨率来对经过训练的Darknet53进行微调,执行该步骤的目的是获得更高的精度。
近年来,网络架构搜索(NAS)相关研究得到大力发展,NASFPN[7]搜索特征金字塔的组合路径。我们可以把NAS-FPN看作是一种主要在阶段级执行的模型缩放技术。对于EfficientNet[30],它使用了基于深度、宽度和输入大小的复合缩放搜索 。EfficientDet[31]的主要设计理念是将具有不同功能的目标检测器模块拆解,然后对图像大小、宽度、#BiFPN层、#box/class层进行缩放。另一种采用NAS概念的设计是SpineNet[5],主要针对fish-shaped目标检测器的整体架构进行网络架构搜索。这种设计理念最终可以产生一个比例排列的结构。另一种采用NAS设计的网络是RegNet[23],它主要固定阶段数和输入分辨率,将各阶段的深度、宽度、瓶颈比、组宽等参数集成为深度、初始宽度、坡度、量化、瓶颈比、组宽。 最后,利用这六个参数对复合模型进行尺度搜索。上述方法都是伟大的工作,但很少有方法分析不同参数之间的关系 。在本文中,我们将根据目标检测的设计要求,尝试寻找一种协同复合缩放方法。
3.模型缩放的原则
在对所提出的目标检测器进行模型缩放后,下一步是处理将发生变化的定量因素,包括带有定性因素的参数的数量。这些因素包括模型推理时间、平均精度等。根据使用的设备或数据库,定性因素会有不同的增益效果。我们将在3.1中对定量因素进行分析和设计。在3.2和3.3中,我们将分别设计运行在低端设备和高端gpu上的微型目标检测器的定性因素。
3.1 模型缩放的常规原则
在设计有效的模型比例方法时,我们的主要原则是当比例上升或下降时,我们想要增加或减少的定量成本越低/越高越好。在本节中,我们将展示和分析各种常见的CNN模型,并试图了解它们在面对(1)图像大小、(2)层数和(3)通道数量变化时的量化成本。我们选择的cnn是ResNet、ResNext和Darknet。
对于具有b通道数的k层CNN, ResNet层计算为k∗{conv 1 × 1, b/4 – conv
3 × 3, b/4 – conv 1 × 1, b}, ResNext层计算为k∗{conv 1 × 1, b/2 – gconv 3 × 3/32, b/2 – conv 1 × 1,b}。对于darknet,计算量为k∗{conv 1 × 1, b/2 – conv 3 × 3, b}。将可用于调整图像大小、层数和通道数的缩放因子分别设置为:α, β, 和 γ。当这些比例因子发生变化时,FLOPs的相应变化见表1。(根据上面的描述和EfficientNet的论文,下面的图应该画错了,width和depth位置应该互换)。
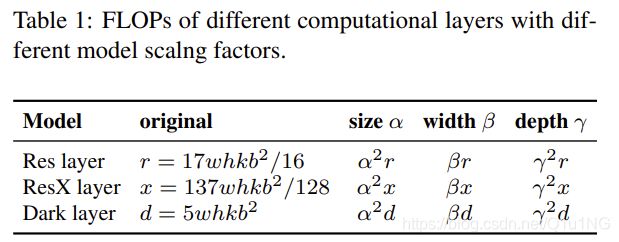
由表1可以看出,图像大小、深度和宽度都会导致计算成本的增加,他们分别成二次,线性,二次增长。
Wang等人提出的CSPNet[33]可以应用于各种CNN架构,同时减少了参数和计算量。此外,它还提高了准确性,减少了推理时间。我们把它应用到ResNet, ResNeXt,DarkNet并且发现计算量的变化,如表2所示。

从表2中所示的数字中,我们发现将上述CNN转换为CSPNet后,新的体系结构可以有效地减少ResNet、ResNeXt和Darknet的计算量(flop),分别减少23.5%、46.7%和50.0%。因此,我们使用CSP-ized模型作为执行模型缩放的最佳模型。
3.2 为低端设备缩放tiny模型
对于低端设备,设计模型的推理速度不仅受到计算量和模型大小的影响,更重要的是必须考虑外围硬件资源的限制。因此,在执行tiny模型缩放时,我们还必须考虑诸如内存带宽、内存访问成本(MACs)和DRAM流量 等因素。为了考虑到以上因素,我们的设计必须遵循以下原则:
使计算复杂度少于O(whkb2): 轻量化模型不同于大型模型,轻量化模型的参数利用效率更高,才能在计算量较小的情况下达到所要求的精度。在进行模型缩放时,我们希望计算复杂度尽可能的低。在表3中,我们分析了有效利用参数的网络,如DenseNet和OSANet的计算负荷。
对于常规的CNN,表3中列出的g、b、k之间的关系为k << g < b,因此DenseNet的计算复杂度为O(whgbk), OSANet的计算复杂度为O(max(whbg, whkg2))。以上两者的计算复杂度的阶数小于ResNet系列的O(whkb2)。因此,我们利用OSANet设计了计算复杂度较小的tiny模型。
最小化/平衡feature map的大小: 为了在计算速度上得到最好的折衷,我们提出了一个新的概念,即在CSPOSANet的计算块之间进行梯度截断。如果我们将原来的CSPNet设计应用到DenseNet或ResNet架构上,由于这两种架构的第j层输出是第1st层到第(j-1)th层输出的积分,我们必须将整个计算块作为一个整体来处理。由于OSANet的计算块属于PlainNet架构,从计算块的任意层制作CSPNet都可以达到梯度截断的效果。我们利用该特性对基层的b通道和计算块生成的kg通道进行重新规划,并将其分割为通道数相等的两条路径 ,如表4所示。
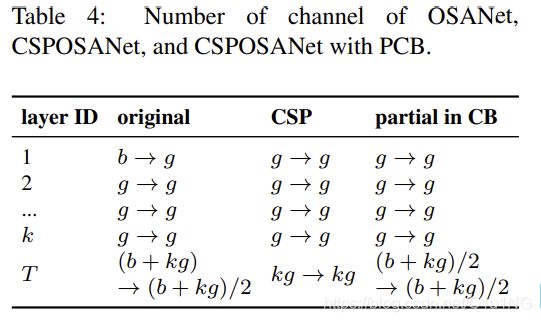
当通道数量为b + kg时,如果要将这些通道分割成两条路径,最好将其分割成相等的两部分,即(b + kg)/2。当我们实际考虑硬件的带宽时,如果不考虑软件优化,最好的值是ceil((b + kg)/2τ) × τ。我们设计的CSPOSANet可以动态调整通道分配。
在卷积后保持相同的通道数: 在评估低端设备的计算成本时,还必须考虑功耗,影响功耗的最大因素是内存访问成本(MAC)。通常一个卷积运算的MAC计算方法如下:
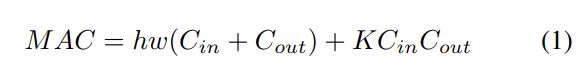
其中h, w, Cin, Cout, K分别表示feature map的高度和宽度,输入和输出的通道数,卷积滤波器的核大小。通过计算几何不等式,可以推导出Cin = Cout时的最小MAC。
最小化卷积输入/输出(CIO): CIO是一个可以测量DRAM IO状态的指标。表5列出了OSA、CSP和我们设计的CSPOSANet的CIO。当kg > b/2时,CSPOSANet可以获得最佳的CIO。

3.3 为高端设备缩放Large模型
由于我们希望在对CNN模型进行缩放后提高准确性并保持实时推理速度,所以在进行复合缩放时,必须在目标检测器众多的缩放因子中找到最佳的组合。通常,我们可以调整目标检测器的输入、backbone和neck的比例因子。表6总结了可以调整的潜在缩放因子。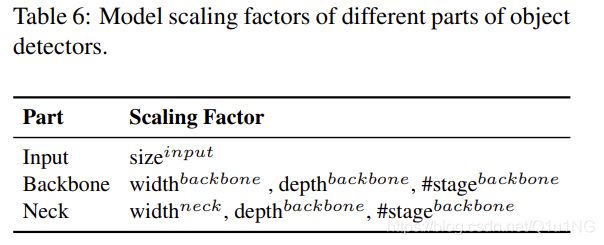
图像分类与目标检测最大的区别在于,前者只需要识别图像中最大成分的类别,而后者需要预测图像中每个目标的位置和大小。在one-stage目标检测器中,利用每个位置对应的特征向量来预测该位置的目标类别和大小。更好地预测物体大小的能力基本上取决于特征向量的感受野。在CNN的架构中,与感受野最直接相关的是stage, feature pyramid network (FPN)的架构告诉我们,更高的stage更适合预测大的物体。表7说明了感受野与几个参数之间的关系。
从表7可以看出,宽度缩放可以独立操作。当输入图像尺寸增大时,要想对大对象有更好的预测效果,就必须增大网络的depth或stage的数量。在表7中列出的参数中,{sizeinput, #stage}的组合效果最好。因此,当执行缩放时,我们首先在sizeinput,#stage上执行复合缩放,然后根据实时的环境,我们再分别进一步缩放深度depth和宽度width。
4. Scaled-YOLOv4
在本节中,我们将重点放在为一般gpu、低端gpu和高端gpu设计缩放YOLOv4上。
4.1 CSP-ized YOLOv4
YOLOv4是为通用GPU上的实时目标检测而设计的。在本节中,我们将YOLOv4重新设计为YOLOv4- csp,以获得最佳的速度/精度权衡。
Backbone: 在CSPDarknet53的设计中,跨stage处理的下采样卷积计算不包括在残差块中。因此,我们可以推断CSPDarknet每个阶段的计算量为whb2(9/4+3/4+5k/2)。由上式可知,只有当k>1时,CSPDarknet的stage比Darknet的stage具有更好的计算优势。SPDarknet53中每个阶段拥有的残差层数分别为1-2-8-8-4。为了获得更好的速度/精度权衡,我们将第一个CSP阶段转换为原始的DarkNet的残差层。
Neck: 为了有效地减少计算量,我们将CSP结构融合到YOLOv4中的PAN体系结构。PAN体系结构的计算列表如图2(a)所示。它主要整合来自不同特征金字塔的特征,然后通过两组反向的DarkNet残差层,没有shortcut连接。经过csp化,新的计算列表的架构如图2(b)所示。这个新的更新有效地减少了40%的计算量。
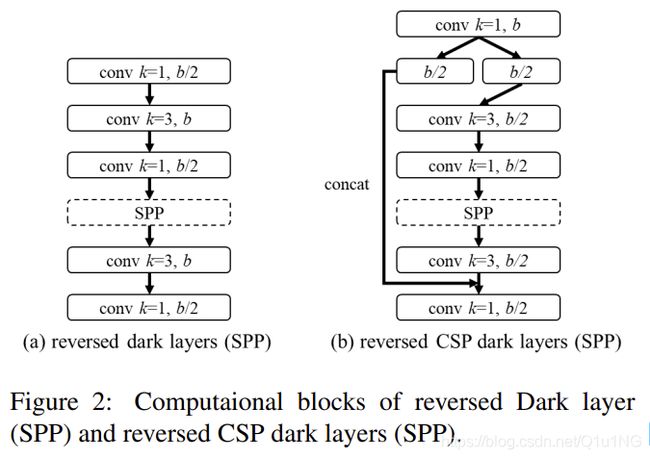
SPP: SPP模块最初是插入在neck第一个计算列表组的中间位置。因此,我们也将SPP模块插入到CSPPAN的第一个计算列表组的中间位置。
4.2 YOLOv4-tiny
YOLOv4-tiny是为低端GPU设备设计的,设计将遵循3.2节中提到的原则。
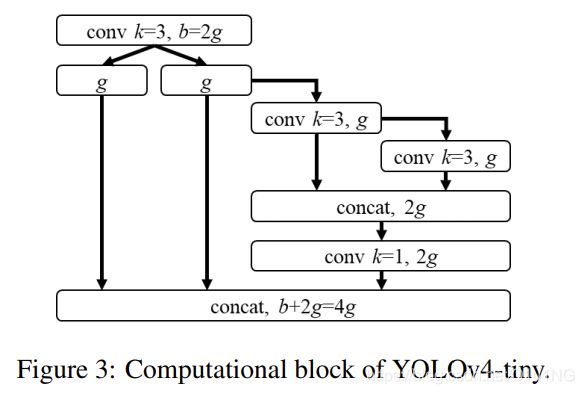
我们将使用PCB架构的CSPOSANet来构成YOLOv4的主干。我们设g = b/2为增长率,最终使其增长到b/2 + kg = 2b。通过计算,我们得到k = 3,其结构如图3所示。对于每个阶段的通道数量和neck部分,我们采用YOLOv3-tiny的设计。
4.3 YOLOv4-large
YOLOv4-large是为云GPU设计的,主要目的是实现高精度的目标检测。我们设计了一个完全csp化的模型YOLOv4-P5,并将其扩展到YOLOv4-P6和YOLOv4-P7。
YOLOv4- p5、YOLOv4- P6、YOLOv4- p7的结构如图4所示。我们设计在sizeinput, #stage上执行复合缩放。我们将每个stage的depth尺度设置为2dsi, ds设置为[1,3,15,15,7,7,7]。最后,我们进一步使用推断时间作为约束来执行额外的宽度缩放。实验表明,当宽度缩放因子为1时,YOLOv4-P6可以在30帧/秒的视频中达到实时性能。对于YOLOv4-P7来说,当宽度缩放因子等于1.25时,它可以在15 fps的视频中达到实时性能。

5.实验
我们使用MSCOCO 2017目标检测数据集对提出的 scaled-YOLOv4进行验证。
我们没有使用ImageNet预训练的模型,所有的scaled-YOLOv4模型都是从头开始训练的,采用的工具是SGD优化器。训练YOLOv4-tiny的时间是600 epoch,训练YOLOv4-CSP的时间是300 epoch。对于YOLOv4-large,我们先执行300个epoch,然后使用更强的数据增强方法训练150个epoch。对于拉格朗日乘子的超参数,如锚点,学习率、不同程度的数据增强方法,我们采用k-means和遗传算法来确定。所有与超参数相关的细节在附录中详细说明(虽然目前论文还没有看到有附录。。)。
5.1 CSP化模型的消融实验
在本节中,我们将对不同的模型进行CSP化,并分析CSP化对参数数量、计算量、吞吐量和平均精度的影响。我们使用Darknet53(D53)作为主干,并选择带SPP的FPN(FPNSPP)和带SPP的PAN(PANSPP)来设计消融研究。表8中我们列出了对不同DNN模型进行csp化后的APval结果。我们分别使用LeakyReLU (Leaky)和Mish激活函数来比较使用的参数、计算量和吞吐量。实验均在COCO minval dataset上进行,得到的APs如表8最后一列所示。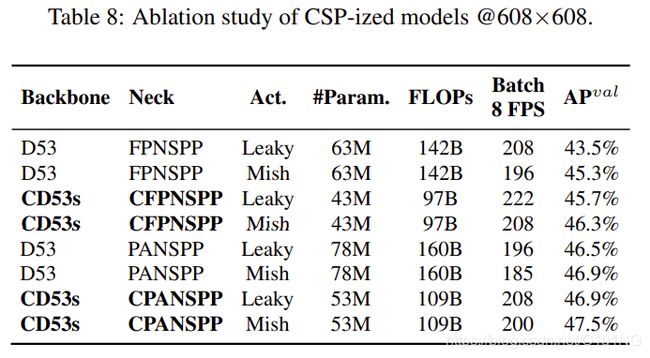
从表8中列出的数据可以看出,csp化的模型大大减少了32%的参数量和计算量,并且在Batch 8吞吐量和AP方面都有了提高。在CSP化之后,如果想要保持相同的帧率,需要添加更多的层数或者使用更先进的激活函数。从表8所示的图中可以看出, CD53s-CFPNSPP-Mish和CD53sCPANSPP-Leaky具有与D53-FPNSPP-Leaky相同的Batch 8吞吐量,但在计算资源较低的情况下,它们分别提高了1%和1.6%的AP(我看图明明是提升了2.8%和3.4%呀。。)。从上面的改进图中,我们可以看到模型csp化带来的巨大优势。因此,我们决定使用表8中AP最高的CD53s-CPANSPP-Mish作为YOLOv4-CSP的主干。
5.2 YOLOv4-tiny的消融实验
在这一小节中,我们设计了一个实验来展示如果在计算块中使用带有 partial函数的CSPNet可以有多灵活。我们还与CSPDarknet53进行了比较,后者在宽度和深度上进行了线性缩小。结果见表9。
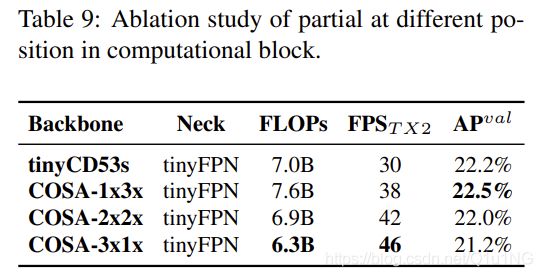
从表9的图中可以看出,设计的PCB技术可以使模型更加灵活,因为这样的设计可以根据实际需要进行调整。从以上结果,我们也证实了线性缩放确实有其局限性。很明显,在有限的运行条件下,tinyCD53s的残差添加成为推理速度的瓶颈,因为在相同的计算量下,tinyCD53s的帧速率远低于COSA架构 。同时,我们也看到本文提出的COSA可以获得更高的AP,因此,我们最终选择了在我们的实验中速度/精度权衡最好的COSA-2x2x作为YOLOv4-tiny架构。
5.3 YOLOv4-large的消融研究
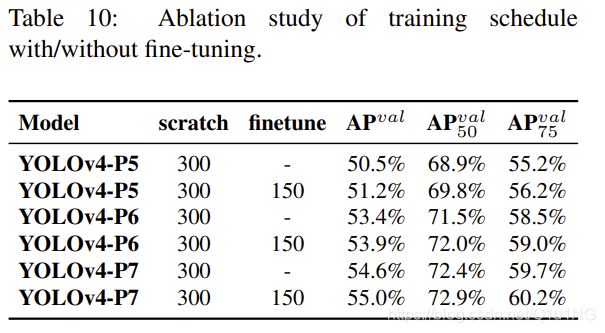
表10展示了YOLOv4模型在从零开始训练和微调阶段获得的AP。
5.4 用于目标检测的Scaled-YOLOv4
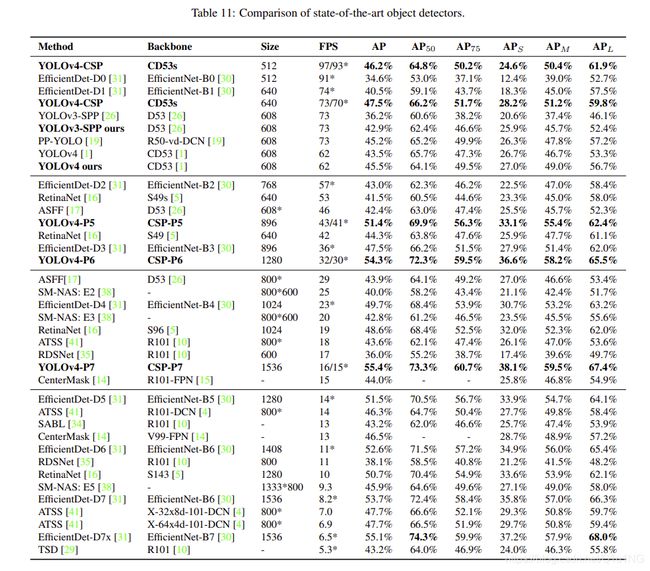
与其他实时目标检测检测器进行比较,结果如表11所示。[AP, AP50, AP75, APS, APM, APL]项中粗体标记的值表明模型在相应项中表现最好。我们可以看到,所有规模的YOLOv4模型,包括YOLOv4- csp, YOLOv4- p5, YOLOv4- p6, YOLOv4- P7,在所有指标上都是最优的。当我们将YOLOv4-CSP与同样精度的EfficientDet-D3 (47.5% vs 47.5%)进行比较时,推理速度是1.9倍。YOLOv4-P5与EfficientDet-D5比较,两者精度相同(51.4% vs 51.5%),推理速度是2.9倍。类似于YOLOv4-P6与EfficientDet- D7 (54.3% vs 53.7%)和YOLOv4-P7与EfficientDet-D7x (55.4% vs 55.1%)的比较。在这两种情况下,YOLOv4-P6和YOLOv4-P7的推理速度分别快了3.7倍和2.3倍。所有的yolov4模型都达到了最先进的效果。
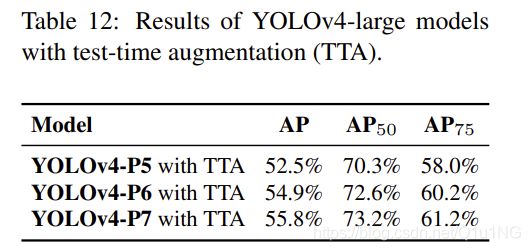
yolov4大模型的测试时间增加(TTA)实验结果见表12。应用TTA后,YOLOv4- P5、YOLOv4- p6和YOLOv4- p7分别上涨1.1%、0.6%和0.4%。
然后我们将YOLOv4-tiny与其他tiny目标检测器的性能进行比较,结果如表13所示。很明显,YOLOv4-tiny在与其他tiny模型的比较中获得了最好的性能。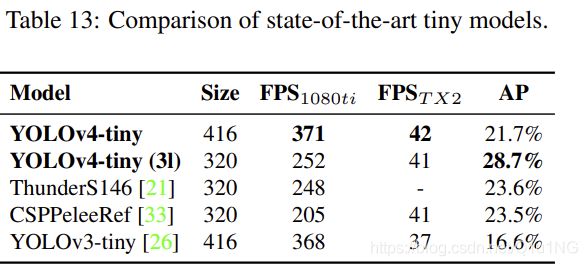
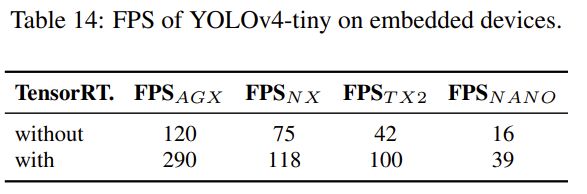
最后,我们将YOLOv4-tiny放在不同的嵌入式gpu上进行测试,包括Xavier AGX, Xavier NX, Jetson TX2, Jetson NANO。我们还使用TensorRT FP32(如果支持FP16)进行测试。表14列出了不同模型得到的所有帧率。可以看出,无论使用哪种设备,YOLOv4-tiny都可以实现实时性能。如果我们采用FP16和batch size 4来测试Xavier AGX和Xavier NX,帧率可以分别达到380fps和199fps。另外,如果使用TensorRT FP16在通用GPU RTX 2080ti上运行YOLOv4-tiny,当批处理大小分别为1和4时,各自的帧率可以达到773fps和1774fps,非常快。
5.5 Scaled-YOLOv4 是一个简单的once-for-all 模型
在本小节中,我们设计实验表明FPN-like架构是一个简单的 once-for-all 模型。我们删除了YOLOv4-P7的一些自顶向下路径和检测分支。YOLOv4-P7\P7和YOLOv4-P7\P7 \P6表示已经从训练好的YOLOv4-P7中移除{P7}和{P7, P6}阶段的模型。图5显示了在不同的输入分辨率下,经过修剪的模型与原始YOLOv4-P7之间的AP差异。
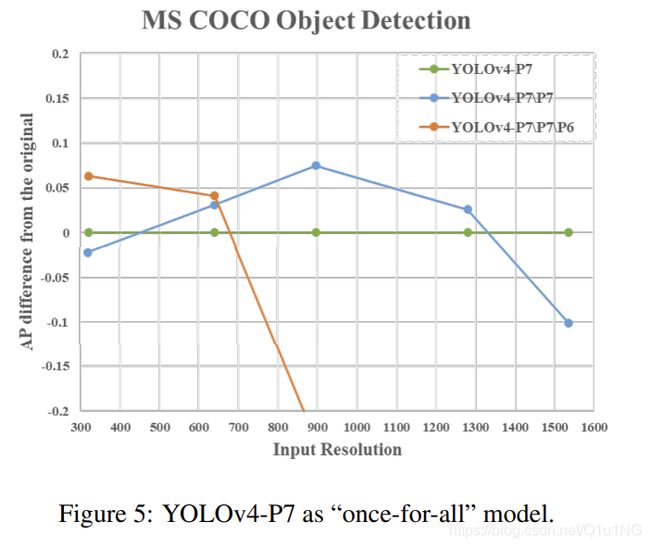
我们可以发现YOLOv4-P7在高分辨率下的AP最好,而YOLOv4-P7\P7和YOLOv4-P7\P7\P6在中、低分辨率下的AP最好。这意味着我们可以使用FPN-like模型的子网络来很好地执行目标检测任务。此外,我们还可以对目标检测器的模型结构和输入大小进行复合缩小,以获得最佳性能。
6.结论
实验表明,基于CSP方法的YOLOv4目标检测神经网络具有可伸缩性和可伸缩性,适用于大小网络。因此,我们使用TensorRT-FP16在RTX 2080Ti上为YOLOv4-large模型在test-dev COCO数据集上实现了最高的精度55.8% AP,为小模型YOLOv4-tiny实现了极高的速度1774 FPS,并为其他YOLOv4模型实现了最佳的速度和精度。
参考文献
[1] Alexey Bochkovskiy, Chien-Yao Wang, and HongYuan Mark Liao. YOLOv4: Optimal speed and accuracy of
object detection. arXiv preprint arXiv:2004.10934, 2020. 2,
7
[2] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and
Song Han. Once-for-all: Train one network and specialize it
for efficient deployment. arXiv preprint arXiv:1908.09791,
2019. 1
[3] Jiale Cao, Hisham Cholakkal, Rao Muhammad Anwer, Fahad Shahbaz Khan, Yanwei Pang, and Ling Shao. D2Det:
Towards high quality object detection and instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11485–11494,
2020. 2
[4] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong
Zhang, Han Hu, and Yichen Wei. Deformable convolutional
networks. In Proceedings of the IEEE international conference on computer vision, pages 764–773, 2017. 7
[5] Xianzhi Du, Tsung-Yi Lin, Pengchong Jin, Golnaz Ghiasi,
Mingxing Tan, Yin Cui, Quoc V Le, and Xiaodan Song.
SpineNet: Learning scale-permuted backbone for recognition and localization. arXiv preprint arXiv:1912.05027,
2019. 2, 7
[6] Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. CenterNet: Keypoint triplets for
object detection. In Proceedings of the IEEE International
Conference on Computer Vision (ICCV), pages 6569–6578,
2019. 2
[7] Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. NAS-FPN:
Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), pages 7036–7045,
2019. 2
[8] Ross Girshick. Fast R-CNN. In Proceedings of the IEEE
International Conference on Computer Vision (ICCV), pages
1440–1448, 2015. 2
[9] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra
Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), pages 580–587, 2014. 2
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), pages 770–778, 2016. 1, 2, 7
[11] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), pages 4700–4708,
2017. 2
[12] Hei Law and Jia Deng. CornerNet: Detecting objects as
paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), pages 734–750, 2018. 2
[13] Hei Law, Yun Teng, Olga Russakovsky, and Jia Deng.
CornerNet-Lite: Efficient keypoint based object detection.
arXiv preprint arXiv:1904.08900, 2019. 2
[14] Youngwan Lee and Jongyoul Park. CenterMask: Real-time
anchor-free instance segmentation. In Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 7
[15] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, ´
Bharath Hariharan, and Serge Belongie. Feature pyramid
networks for object detection. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition
(CVPR), pages 2117–2125, 2017. 7
[16] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and
Piotr Dollar. Focal loss for dense object detection. In ´ Proceedings of the IEEE International Conference on Computer
Vision (ICCV), pages 2980–2988, 2017. 2, 7
[17] Songtao Liu, Di Huang, and Yunhong Wang. Learning spatial fusion for single-shot object detection. arXiv preprint
arXiv:1911.09516, 2019. 7
[18] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian
Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C
Berg. SSD: Single shot multibox detector. In Proceedings
of the European Conference on Computer Vision (ECCV),
pages 21–37, 2016. 2
[19] Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang,
Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin
Han, Errui Ding, et al. PP-YOLO: An effective and efficient implementation of object detector. arXiv preprint
arXiv:2007.12099, 2020. 2, 7
[20] Siyuan Qiao, Liang-Chieh Chen, and Alan Yuille. DetectoRS: Detecting objects with recursive feature pyramid and switchable atrous convolution. arXiv preprint
arXiv:2006.02334, 2020. 2
[21] Zheng Qin, Zeming Li, Zhaoning Zhang, Yiping Bao, Gang
Yu, Yuxing Peng, and Jian Sun. ThunderNet: Towards realtime generic object detection. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019.
8
[22] Han Qiu, Yuchen Ma, Zeming Li, Songtao Liu, and Jian Sun.
BorderDet: Border feature for dense object detection. arXiv
preprint arXiv:2007.11056, 2020. 2
[23] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick,
Kaiming He, and Piotr Dollar. Designing network design ´
spaces. In Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition, pages 10428–
10436, 2020. 1, 3
[24] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali
Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 779–
788, 2016. 2
[25] Joseph Redmon and Ali Farhadi. YOLO9000: better, faster,
stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7263–
7271, 2017. 2
[26] Joseph Redmon and Ali Farhadi. YOLOv3: An incremental
improvement. arXiv preprint arXiv:1804.02767, 2018. 2, 7, 8
[27] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.
Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems (NIPS), pages 91–99, 2015. 2
[28] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv
preprint arXiv:1409.1556, 2014. 2
[29] Guanglu Song, Yu Liu, and Xiaogang Wang. Revisiting the sibling head in object detector. In Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pages 11563–11572, 2020. 7
[30] Mingxing Tan and Quoc V Le. EfficientNet: Rethinking
model scaling for convolutional neural networks. In Proceedings of International Conference on Machine Learning
(ICML), 2019. 1, 2, 7
[31] Mingxing Tan, Ruoming Pang, and Quoc V Le. EfficientDet:
Scalable and efficient object detection. In Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 2, 7
[32] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS:
Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 9627–9636, 2019. 2
[33] Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu,
Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. CSPNet: A
new backbone that can enhance learning capability of CNN.
Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition Workshop (CVPR Workshop), 2020.
3, 8
[34] Jiaqi Wang, Wenwei Zhang, Yuhang Cao, Kai Chen, Jiangmiao Pang, Tao Gong, Jianping Shi, Chen Change Loy, and
Dahua Lin. Side-aware boundary localization for more precise object detection. In European Conference on Computer
Vision, pages 403–419. Springer, 2020. 7
[35] Shaoru Wang, Yongchao Gong, Junliang Xing, Lichao
Huang, Chang Huang, and Weiming Hu. RDSNet: A new
deep architecture for reciprocal object detection and instance
segmentation. arXiv preprint arXiv:1912.05070, 2019. 7
[36] Xinjiang Wang, Shilong Zhang, Zhuoran Yu, Litong Feng,
and Wayne Zhang. Scale-equalizing pyramid convolution
for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages
13359–13368, 2020. 2
[37] Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, and ´
Kaiming He. Aggregated residual transformations for deep
neural networks. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR), pages
1492–1500, 2017. 2
[38] Lewei Yao, Hang Xu, Wei Zhang, Xiaodan Liang, and Zhenguo Li. SM-NAS: Structural-to-modular neural architecture
search for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020. 7
[39] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016. 2
[40] Hongkai Zhang, Hong Chang, Bingpeng Ma, Naiyan Wang,
and Xilin Chen. Dynamic R-CNN: Towards high quality object detection via dynamic training. arXiv preprint
arXiv:2004.06002, 2020. 2
[41] Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and
Stan Z Li. Bridging the gap between anchor-based and
anchor-free detection via adaptive training sample selection.
In Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), 2020. 7
[42] Xingyi Zhou, Dequan Wang, and Philipp Krahenb ¨ uhl. Ob- ¨
jects as points. In arXiv preprint arXiv:1904.07850, 2019.2
一些不重要的话.
其实之前笔者就有关注这个项目,而且这个模型已经在MS COCO数据集登顶至少好几周了,之前所有的实验和结果都在WongKinYiu/PyTorch_YOLOv4项目里面(记得当时测了一下里面的YOLOv4pacsp,速度也一般,不过是要比原YOLOV4快),现在分离出来了WongKinYiu/ScaledYOLOv4,其实整个项目就是用ultralytics/yolov5的代码(里面也包含很多tricks,例如新的边框回归,EMA,CIOU LOSS, 数据增强等),然后按照以前YOLOV4的结构,在neck部分添加了CSP结构,又重新设计了P5/6/7三个网络结构,达到了SOTA。虽然还是牛,毕竟SOTA,但感觉论文写的很赶,好多地方有点没讲清楚,模型缩放也没有EfficientNet讲的清楚,附录也还没有,具体训练细节也看不到,感觉就是想先把自己的SOTA结果发表出来写的论文。。