自动驾驶(三十三)---------车位识别
车位识别感触很深,分为两个角度,从停车场角度:地磁检测、摄像头检测。从车辆角度:摄像头、超声波;
在我实习期间,做过地磁检测,那时还是职场小白,发生了很多有趣的事,同时也是一生中最痛苦的时段,感慨良多,一晃五年多,尘满面、鬓如霜。
本文只从车辆角度视觉角度,检测车道线,市面上有些基于传统VC的方法,我相信效果肯定一般,还是专注于深度学习的方法吧。对于摄像头标定、透视变换、坐标变换也不再本文讨论范围之内,这些基础知识出门左转,前面的blog有很多,这里涉及视觉识别和图像级定位。
车位识别有两种思路:在鱼眼图片基础上识别、在俯视图基础上做识别。两者在计算车位坐标,都会受到鱼眼畸变影响,不同的是,在鱼眼基础上识别,缺少了车位四个角点的矩形约束,在俯视图上识别会带有矩形约束。
这里通过介绍mask RCNN来介绍深度学习对车位的识别,为了介绍Mask RCNN,我们先介绍一些简单的网络模型,一步步进化到MaskRCNN;
1. RCNN
选择性搜索:我们不使用暴力方法,而是用候选区域方法创建目标检测的感兴趣区域(ROI)。我们首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的 ROI。

R-CNN 利用候选区域方法创建了约 2000 个 ROI。这些区域被转换为固定大小的图像,并分别馈送到卷积神经网络中。该网络架构后面会跟几个全连接层,以实现目标分类并提炼边界框。
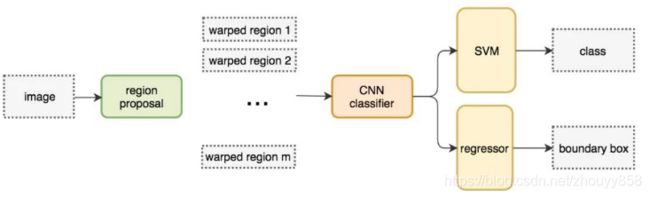
通过使用更少且更高质量的 ROI,R-CNN 要比滑动窗口方法更快速、更准确。候选区域方法有非常高的计算复杂度。为了加速这个过程,我们通常会使用计算量较少的候选区域选择方法构建 ROI,并在后面使用线性回归器(使用全连接层)进一步提炼边界框。
2. Faster RCNN
Faster RCNN是两阶段的目标检测算法,包括阶段一的Region proposal以及阶段二的bounding box回归和分类。用一张图来直观展示Faster RCNN的整个流程:
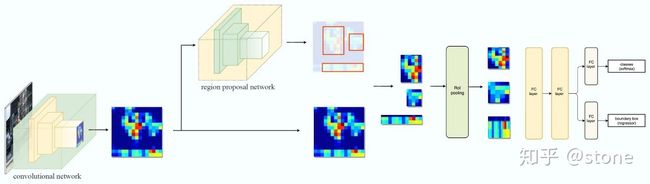
1. Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
2.Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
3.Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
4.Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
3. ResNet-FPN
多尺度检测在目标检测中变得越来越重要,对小目标的检测尤其如此。图片金字塔一直都是机器视觉的常用手段,FPN结构中包括自下而上,自上而下和横向连接三个部分,如下图所示。这种结构可以将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息,在特征学习中算是一把利器了。
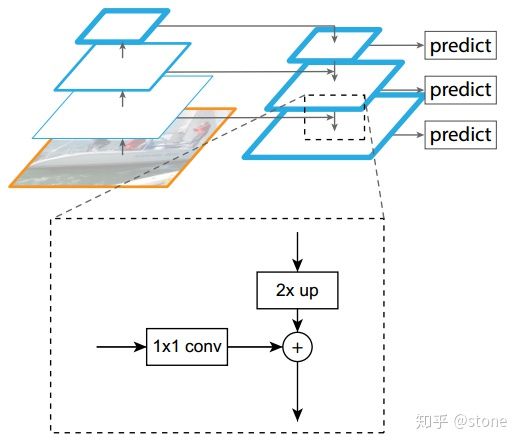
FPN实际上是一种通用架构,可以结合各种骨架网络使用,比如VGG,ResNet等。Mask RCNN文章中使用了ResNNet-FPN网络结构。

3、ResNet-FPN+Fast RCNN

将ResNet-FPN和Fast RCNN进行结合,实际上就是Faster RCNN的了,但与最初的Faster RCNN不同的是,FPN产生了特征金字塔 ![]() ,而并非只是一个feature map。金字塔经过RPN之后会产生很多region proposal。这些region proposal是分别由
,而并非只是一个feature map。金字塔经过RPN之后会产生很多region proposal。这些region proposal是分别由 ![]() 经过RPN产生的,但用于输入到Fast RCNN中的是
经过RPN产生的,但用于输入到Fast RCNN中的是 ![]() ,也就是说要在
,也就是说要在 ![]() 中根据region proposal切出ROI进行后续的分类和回归预测。问题来了,我们要选择哪个feature map来切出这些ROI区域呢?实际上,我们会选择最合适的尺度的feature map来切ROI。具体来说,我们通过一个公式来决定宽w和高h的ROI到底要从哪个
中根据region proposal切出ROI进行后续的分类和回归预测。问题来了,我们要选择哪个feature map来切出这些ROI区域呢?实际上,我们会选择最合适的尺度的feature map来切ROI。具体来说,我们通过一个公式来决定宽w和高h的ROI到底要从哪个![]() 来切:
来切:
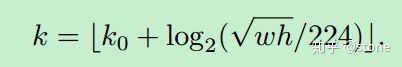
这里224表示用于预训练的ImageNet图片的大小。![]() 表示面积为
表示面积为 ![]() 的ROI所应该在的层级。作者将
的ROI所应该在的层级。作者将 ![]() 设置为4,也就是说
设置为4,也就是说 ![]() 的ROI应该从 P4 中切出来。假设ROI的scale小于224(比如说是112 * 112),
的ROI应该从 P4 中切出来。假设ROI的scale小于224(比如说是112 * 112), ![]() ,就意味着要从更高分辨率的
,就意味着要从更高分辨率的 ![]() 中产生。另外,k 值会做取整处理,防止结果不是整数。这种做法很合理,大尺度的ROI要从低分辨率的feature map上切,有利于检测大目标,小尺度的ROI要从高分辨率的feature map上切,有利于检测小目标。
中产生。另外,k 值会做取整处理,防止结果不是整数。这种做法很合理,大尺度的ROI要从低分辨率的feature map上切,有利于检测大目标,小尺度的ROI要从高分辨率的feature map上切,有利于检测小目标。
4. ResNet-FPN+Fast RCNN+mask
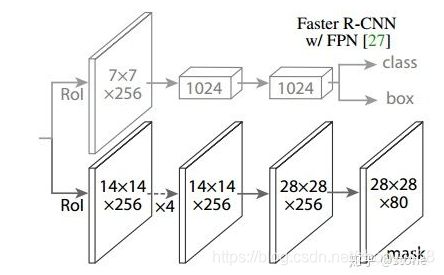
我们再进一步,将ResNet-FPN+Fast RCNN+mask,则得到了最终的Mask RCNN,如下图:
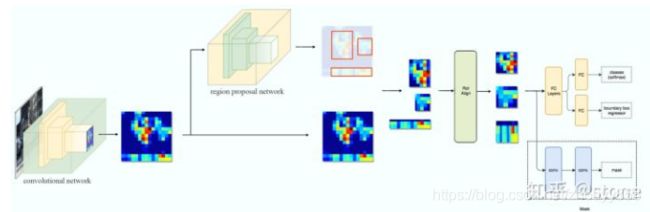
Mask RCNN的构建很简单,只是在ROI pooling(实际上用到的是ROIAlign,后面会讲到)之后添加卷积层,进行mask预测的任务。下面总结一下Mask RCNN的网络:
- 骨干网络ResNet-FPN,用于特征提取,另外,ResNet还可以是:ResNet-50,ResNet-101,ResNeXt-50,ResNeXt-101;
- 头部网络,包括边界框识别(分类和回归)+mask预测。头部结构见下图: