Hadoop生态之Flume
Flume
- 1.什么是Flume?
- 2.Flume的特点
- 3.Flume的架构
-
- 3.1 Agent
- 3.2 Source
- 3.3 Sink
- 3.4 Channel
- 3.5 Event
- 4.Flume的安装部署
- 5.Flume简单案例
-
- 5.1 监控单个追加文件
- 5.2 实时监控目录下多个新文件
- 5.3 实时监控目录下的多个追加文件
- 6.Flume事务
- 7.Flume Agent内部原理
- 8.Flume拦截器、数据流以及可靠性
-
- 8.1、Flume拦截器
- 8.2、Flume数据流
- 8.3、Flume可靠性
- 9.Flume企业真实面试题
-
- 9.1 你在本地是如何实现 Flume 数据传输的监控的
- 9.3 Flume 的 Channel Selectors
- 9.4 Flume 参数调优
- 9.5 Flume 的事务机制
- 9.6 Flume 采集数据会丢失吗?

1.什么是Flume?
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。
但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.9.4. 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
2.Flume的特点
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
1)flume的可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
2)flume的可恢复性
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
3.Flume的架构

3.1 Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组成,Source、Channel、Sink。
3.2 Source
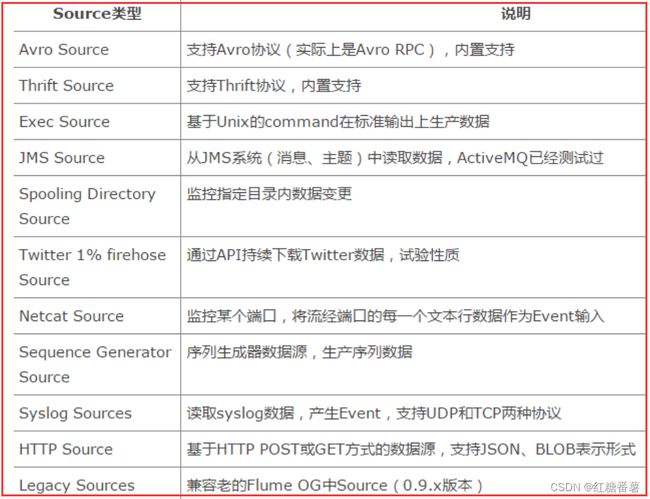
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、taildir、sequence generator、syslog、http、legacy。
3.3 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定
义。

3.4 Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适
用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
3.5 Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。
Event 由 Header 和 Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为字节数组。
| Header | Body |
|---|---|
| k=v | byte array |
4.Flume的安装部署
佬们可以阅读官方文档来安装,flume的安装步骤和hive相似一些。。。。

https://flume.apache.org/FlumeUserGuide.html
5.Flume简单案例
5.1 监控单个追加文件
#Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://localhost:ip/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs- #是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
#Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
#Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
注意:对于所有与时间相关的转义序列,Event Header 中必须存在以 “timestamp”的key
(除非 hdfs.useLocalTimeStamp 设置为 true,此方法会使用 TimestampInterceptor 自动添timestamp)。
a3.sinks.k3.hdfs.useLocalTimeStamp = true
5.2 实时监控目录下多个新文件
a3.sources = r3
a3.sinks = k3
a3.channels = c3
#Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp 结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*.tmp)
#Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =
hdfs://localhost:ip/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
#Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
#Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
5.3 实时监控目录下的多个追加文件
Exec source 适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而 Taildir Source 适合用于监听多个实时追加的文件,并且能够实现断点续传。
a3.sources = r3
a3.sinks = k3
a3.channels = c3
#Describe/configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.file.
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.log.
#Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =
hdfs://localhost:ip/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
#Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
#Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
6.Flume事务

7.Flume Agent内部原理
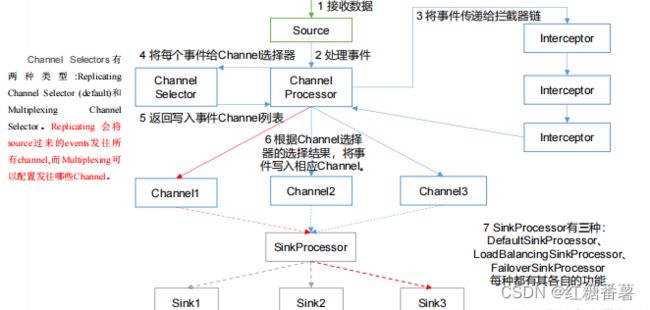
重要组件:
1)ChannelSelector
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型,分别是 Replicating(复制)和 Multiplexing(多路复用)。
ReplicatingSelector 会将同一个 Event 发往所有的 Channel,Multiplexing 会根据相应的原则,将不同的 Event 发往不同的 Channel。
2)SinkProcessor
SinkProcessor 共 有 三 种 类 型 , 分 别 是 DefaultSinkProcessor 、LoadBalancingSinkProcessor 和 FailoverSinkProcessor DefaultSinkProcessor 对 应 的 是 单 个 的 Sink , LoadBalancingSinkProcessor 和
FailoverSinkProcessor 对应的是 Sink Group,LoadBalancingSinkProcessor 可以实现负载均衡的功能,FailoverSinkProcessor 可以错误恢复的功能。
8.Flume拦截器、数据流以及可靠性
8.1、Flume拦截器
当我们需要对数据进行过滤时,除了我们在Source、 Channel和Sink进行代码修改之外, Flume为我们提供了拦截器,拦截器也是chain形式的。拦截器的位置在Source和Channel之间,当我们为Source指定拦截器后,我们在拦截器中会得到event,根据需求我们可以对event进行保留还是抛弃,抛弃的数据不会进入Channel中。

8.2、Flume数据流
1)Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
2) Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。 Event 从 Source,流向 Channel,再到 Sink<本身为一个 byte 数组,并可携带 headers 信息。 Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。

值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。
比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,
也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是Flume强大之处。如下图所示:

8.3、Flume可靠性
Flume 使用事务性的方式保证传送Event整个过程的可靠性。 Sink 必须在Event 被存入 Channel 后,或者,已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把 Event 从 Channel 中 remove 掉。这样数据流里的 event 无论是在一个 agent 里还是多个 agent 之间流转,
都能保证可靠,因为以上的事务保证了 event 会被成功存储起来。比如 Flume支持在本地保存一份文件 channel 作为备份,而memory channel 将event存在内存 queue 里,速度快,但丢失的话无法恢复。

9.Flume企业真实面试题
9.1 你在本地是如何实现 Flume 数据传输的监控的
使用第三方框架 Ganglia 实时监控 Flume。 4.2 Flume 的 Source,Sink,Channel 的作用?你们 Source 是什么类
型?
1)作用
(1)Source 组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
(2)Channel 组件对采集到的数据进行缓存,可以存放在 Memory 或 File 中。
(3)Sink 组件是用于把数据发送到目的地的组件,目的地包括 Hdfs、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
2)我公司采用的 Source 类型为:
(1)监控后台日志:exec
(2)监控后台产生日志的端口:netcat
9.3 Flume 的 Channel Selectors

9.4 Flume 参数调优
1)Source
增加 Source 个(使用 Tair Dir Source 时可增加 FileGroups 个数)可以增大 Source
的读取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个
文件目录,同时配置好多个 Source 以保证 Source 有足够的能力获取到新产生的数据。
batchSize 参数决定 Source 一次批量运输到 Channel 的 event 条数,适当调大这个参
数可以提高 Source 搬运 Event 到 Channel 时的性能。
2)Channel
type 选择 memory 时 Channel 的性能最好,但是如果 Flume 进程意外挂掉可能会丢失
数据。type 选择 file 时 Channel 的容错性更好,但是性能上会比 memory channel 差。
使用 file Channel 时 dataDirs 配置多个不同盘下的目录可以提高性能。
Capacity 参数决定 Channel 可容纳最大的 event 条数。transactionCapacity 参数决
定每次 Source 往 channel 里面写的最大 event 条数和每次 Sink 从 channel 里面读的最大
event 条数。transactionCapacity 需要大于 Source 和 Sink 的 batchSize 参数。
3)Sink
增加 Sink 的个数可以增加 Sink 消费 event 的能力。Sink 也不是越多越好够用就行,
过多的 Sink 会占用系统资源,造成系统资源不必要的浪费。
batchSize 参数决定 Sink 一次批量从 Channel 读取的 event 条数,适当调大这个参数
可以提高 Sink 从 Channel 搬出 event 的性能。
9.5 Flume 的事务机制
Flume 的事务机制(类似数据库的事务机制):Flume 使用两个独立的事务分别负责从Soucrce 到 Channel,以及从 Channel 到 Sink 的事件传递。比如 spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到 Channel 且提交成功,那么 Soucrce 就将该文件标记为完成。
同理,事务以类似的方式处理从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到 Channel 中,等待重新传递。
9.6 Flume 采集数据会丢失吗?
根据 Flume 的架构原理,Flume 是不可能丢失数据的,其内部有完善的事务机制,Source 到 Channel 是事务性的,Channel 到 Sink 是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是 Channel 采用 memoryChannel,agent 宕机导致数据丢失,或者 Channel 存储数据已满,导致 Source 不再写入,未写入的数据丢失。
Flume 不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由 Sink 发出,
但是没有接收到响应,Sink 会再次发送数据,此时可能会导致数据的重复。