Hadoop生态之Hadoop体系架构(一)
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop是一个开源框架,可编写和运行分布式应用处理大规模数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop起源于谷歌的三篇论文(GFS、MapReduce、BigTable)。
名字起源:Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。”
hadoop的特点:
-
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
-
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
-
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
-
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
-
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
大数据的应用场景:
1:各大电商平台个性化推荐(京东,淘宝);
2:根据上网轨迹,构建用户画像,实现精准推送(今日头条,淘宝,京东)
3:海关历年数据分析,决策辅助
4:医疗(对多年同专业数据进行分析)
5:农业
大数据的数据级别及换算:
换算基本都是以2的10次方来递增的
1KiB(Kilobyte)=1024B ,即2的10次方字节,读音“千字节”
1MiB(Megabyte)=1024KiB,即2的20次方字节,读音“兆字节”
1GiB(Gigabyte)=1024MiB,即2的30次方字节,读音“吉字节”
1TiB(Terabyte)=1024GiB,即2的40次方字节,读音“太字节”
1PiB(Petabyte)=1024TiB,即2的50次方字节,读音“拍字节”
1EiB(Exabyte) =1024PiB,即2的60次方字节,读音“艾字节”
1ZiB(Zettabyte)=1024EiB,即2的70次方字节,读音“Z字节”
1YiB(Yottabyte)=1024ZiB,即2的80次方字节,读音“Y字节”
传说中还有
1NiB(NonaByte)=1024YiB,即2的90次方字节
1DiB(DoggaByte)=1024NiB,即2的100次方字节
1CiB(Corydonbyte )=1024DiB,即2的110次方字节
Hadopp生态体系架构图:
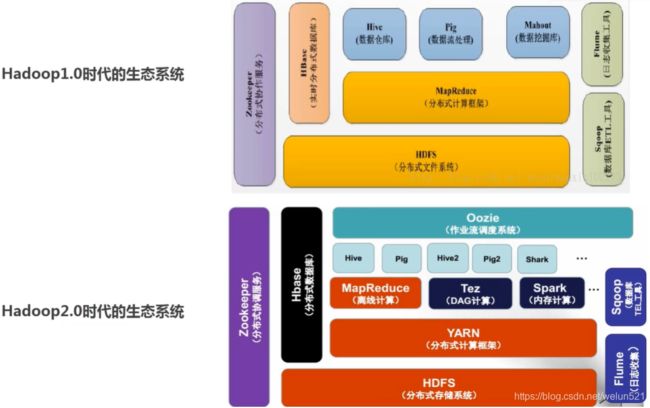
Hadoop技术框架简介:
HDFS:Hadoop中的重要组件之一,用来做分布式存储,具有高容错,高吞吐等特性,是常用的分布式文件存储
MR(MapReduce简称):Hadoop中的重要组件之一,作为分布式计算模型,程序人员只需在Mapper、Reducer中编写业务逻辑,然后直接交由框架进行分布式计算即可。
Yarn:Yarn是Hadoop中的重要组件之一,负责海量数据运算时的资源调度
Flume: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,用来做数据采集。
Kafka:分布式的消息发布/订阅系统,通过与Spark Streaming整合,完成实时业务计算。由Java+scala开发。
Hive/Pig:hive是基于Hadoop的一个数据仓库工具,通过将结构化的数据文件(通常为HDFS文件)映射为一张数据表,提供简单的sql查询功能,将sql语句转换为MapReduce任务运行。
pig可以看做hadoop的客户端软件,可以连接到hadoop集群进行数据分析工作,企业中很少用了。
Hbase:HBase是建立在Hadoop文件系统之上的面向列的分布式数据库。不同于一般的关系数据库,适合于存储非结构化的数据,HBase基于列而不是基于行。
Redis:Redis 可基于内存也可以持久化的日志型、Key-Value数据库。往往用来缓存key-value类型的小表数据。
Sqoop:负责数据在 HIVE---HDFS---DB之间进行导入导出
Standalone:是Spark提供的资源管理器,
Mesos:也是Apache下的开源分布式资源管理器。
Spark:Spark是大规模数据快速处理通用的计算引擎,其提供大量的库:Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX 。(只是计算,不作存储)。