雷达系列论文翻译(十一):LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometryvia Smoothing and Mapping
LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometryvia Smoothing and Mapping
摘要
我们提出了一个通过平滑和映射实现的紧耦合激光雷达视觉惯性里程计的框架LVI-SAM,该框架实现了实时状态估计和地图构建,具有高的精度和鲁棒性。LVI-SAM建立在因子图之上,由两个子系统组成:视觉惯性系统(VIS)和激光雷达惯性系统(LIS)。这两个子系统以紧耦合的方式设计,其中VIS利用LIS的估计来促进初始化。通过使用激光雷达测量提取视觉特征的深度信息,提高了VIS的准确性。在内部,LIS利用VIS的估计作为初始猜测,以支持扫描匹配。闭环首先由VIS识别,然后由LIS进一步细化。当两个子系统中的一个子系统出现故障时,LVI-SAM也能正常工作,从而提高无纹理和无特征环境中的鲁棒性。LVI-SAM在不同规模和环境下从多个平台收集的数据集上进行了广泛的评估。
引言
同时定位和建图(SLAM)是许多移动机器人导航任务所需的基础能力。在过去的二十年中,使用SLAM在具有挑战性的环境中使用单个感知传感器(如激光雷达或照相机)进行实时状态估计和建图取得了巨大的成功。基于激光雷达的方法可以在远距离捕捉环境的细节。然而,当在弱结构的的环境中时,此类方法通常会失败,例如长走廊或平坦开阔的场地。尽管基于视觉的方法特别适合于位置识别,并且在纹理丰富的环境中表现良好,但它们的性能对照明变化、快速运动和初始化非常敏感。因此,基于激光雷达和基于视觉的方法通常都与惯性测量单元(IMU)相结合,以提高各自的鲁棒性和准确性。激光雷达惯性系统有助于矫正点云畸变,并在短时间内缺乏特征时保持一定的精度。可以通过IMU测量恢复场景尺度和姿态,以辅助视觉惯性系统。为了进一步提高系统性能,激光雷达、相机和IMU测量的融合吸引了越来越多的注意力。
我们的工作与视觉惯性里程计(VIO)、激光雷达惯性里程计(LIO)和激光雷达视觉惯性里程计(LVIO)密切相关。我们注意到,在本文中我们不考虑非惯性系统,尽管我们知道有一些成功的非惯性激光雷达视觉系统,如[1],[2]。视觉惯性里程计(VIO)可分为两大类:基于滤波器的方法和基于优化的方法。基于滤波器的方法通常使用扩展卡尔曼滤波器(EKF)通过摄像机和IMU的测量值传播系统状态。基于优化的方法使用了滑动窗口估计器,并将视觉重投影误差和IMU测量误差降至最低。在我们的工作中,我们只考虑单目相机。在最流行的公开可用VIO工作流中,MSCKF[3]、ROVIO[4]和Open VIN[5]基于滤波器,OKVIS[6]、Kimera[7]和VINS- Mono[8]基于优化。虽然OKVIS在使用双目相机时表现出了卓越的性能,但它并没有针对单目相机进行优化。VINS-Mono在滑动窗口设置中执行非线性优化,并使用单目相机实现最先进的精度[9]。
根据其设计方案,激光雷达惯性里程计可分为两大类:松耦合方法和紧耦合方法。LOAM[10]和LeGO-LOAM[11]是松耦合的系统,因为在优化步骤中未使用IMU测量。紧耦合系统通常提供更高的精度和更高的稳定性,目前是正在进行的研究的一个主要焦点[12]。在公开可用的紧耦合系统中,LIO-mapping[13]采用了[8]中的优化工作流,并最小化了IMU和激光雷达测量的残差。由于LIO-mapping旨在优化所有测量,因此无法实现实时性能。LIO-SAM[14]通过引入激光雷达关键帧的滑动窗口来限制计算复杂性,利用因子图进行联合IMU和激光雷达约束优化。LINS[15]专门为地面车辆设计,使用误差状态卡尔曼滤波器递归的校正机器人的状态。
最近,激光雷达视觉惯性系统由于其在传感器退化任务中的鲁棒性而引起了越来越多的关注[16]。[17] 提出了一种紧耦合的LVIO系统,该系统采用顺序处理的工作流,解决了从粗到精的状态估计问题。粗估计从IMU预测开始,然后由VIO和LIO进一步细化。[17] 目前在KITTI基准上达到了最先进的精度[18]。基于MSCKF框架,[19]具有在线时空多传感器标定功能。[17]和[19]的实现尚未公开。我们的工作不同于前面提到的工作,因为我们利用一个因子图进行全局优化,它可以通过闭环检测定期消除机器人产生的漂移。
在本文中,我们提出了一个通过平滑和映射实现的紧耦合的雷达视觉惯性里程计的框架LVI-SAM,用于实时状态估计和建图。LVI-SAM建立在因子图之上,由两个子系统组成,一个子系统是视觉惯性系统(VIS)和一个子系统是激光雷达惯性系统(LIS)。当在其中一个子系统中检测到故障时,这两个子系统可以独立运行,或者当检测到足够的特征时,这两个子系统可以联合运行。VIS执行视觉特征跟踪,并可选择使用激光雷达帧提取特征深度。视觉里程计是通过优化视觉重投影和IMU测量误差而获得的,可作为激光雷达扫描匹配的初始猜测,并在因子图中引入约束。在使用IMU测量值对点云进行去畸变后,LIS提取雷达边缘和平面特征,并将其与滑动窗口中维护的特征地图进行匹配。LIS中的被估计的系统状态可发送至VIS,以方便其初始化。对于闭环矫正,候选匹配首先由VIS识别,然后由ILS进一步优化。视觉里程计、激光雷达里程计、IMU预积分[20]和闭环的约束在因子图中进行了优化。最后,利用优化后的IMU零偏来传播IMU测量值以进行IMU速率的位置估计。我们工作的主要贡献可总结如下:
- 构建在因子图之上的紧耦合LVIO框架,通过位置识别实现多传感器融合和全局优化。
- 我们的框架通过故障检测绕过存在故障的子系统,使其对传感器退化具有鲁棒性。
- 我们的框架通过在不同规模、平台和环境收集的数据进行了广泛验证。
从系统的角度来看,我们的工作是新颖的,代表了VIO和LIO中最先进技术的独一无二的集成,以实现LVIO系统来提供更高的鲁棒性和准确性。我们希望我们的系统可以作为一个坚实的基线,其他人可以很容易地在此基础上推进激光雷达视觉惯性里程计的最新发展。
通过平滑和映射实现的雷达视觉惯性里程计
A. 系统概述
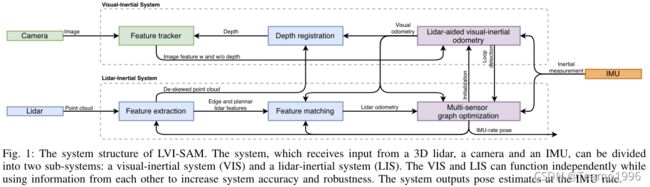
图 1 显示了本文所提出的激光雷达视觉惯性系统的概述,该系统从 3D 激光雷达、单目相机、和 IMU获取输入。我们的框架由两个关键子系统:视觉惯性系统(VIS)和激光雷达惯性系统(LIS)。 VIS 处理图像和 IMU 测量,激光雷达测量是可选的。视觉里程计是通过最小化视觉和 IMU 测量的联合残差来获得的。 LIS 提取激光雷达特征并通过将提取的特征与特征地图进行匹配来实现激光雷达里程计。为了实时性能,特征地图以滑动窗口的方式维护。最后,通过使用 iSAM2 在因子图中联合优化 IMU 预积分约束、视觉里程计约束、激光雷达里程计约束和闭环约束的贡献,可以解决状态估计问题,该问题可以表述为最大后验概率 (MAP) 问题[ 21]。请注意,LIS 中采用的多传感器图优化旨在减少数据交换并提高系统效率。
B. 视觉惯性系统
我们将[8]中的处理工作流用于我们的VIS,如图2所示。

视觉特征使用角点检测器进行检测[22],并通过Kanade–Lucas–Tomasi算法进行跟踪[23]。VIS初始化后,我们使用视觉里程计配准激光雷达帧,并获得用于特征深度估计的稀疏深度图像。系统在滑动窗口设置中执行BA,其中系统状态为 x ∈ X x \in X x∈X可以写成:
x = [ R p v b ] x = \begin{bmatrix} R & p & v & b \end{bmatrix} x=[Rpvb]
R ∈ S O ( 3 ) R \in SO(3) R∈SO(3)是旋转矩阵, p ∈ R 3 p \in \mathbb{R}^3 p∈R3是位置向量, v v v是速度, b = [ b a , b w ] b=[b_a,b_w] b=[ba,bw]是IMU零偏。 b a b_a ba和 b w b_w bw分别是加速度和角速度的零偏向量。从传感器主体坐标系 B B B到世界坐标系 W W W的变换 T ∈ S E ( 3 ) T \in SE(3) T∈SE(3)被表示为 T = [ R ∣ p ] T=[R | p] T=[R∣p]。在下面的部分中,我们将给出改进VIS初始化和特征深度估计的详细过程。由于篇幅限制,我们请读者参考[8]了解更多细节,例如残差的实现。
1) 初始化
基于优化的VIO由于在初始化过程中求解高度非线性的问题,通常会出现发散。初始化的质量在很大程度上取决于两个因素:传感器的初始移动和IMU参数的准确性。在实践中,我们发现当传感器以较小或恒定的速度移动时,[8]常常无法初始化。这是因为当加速度激励不够大时,k空间尺度是不可观测的。IMU参数包括缓慢变化的零偏和白噪声,这会影响原始加速度和角速度测量。在初始化过程中对这些参数的良好猜测有助于优化更快地收敛。
为了提高VIS初始化的鲁棒性,我们从LIS中获得被估计的系统状态 x x x和IMU零偏 b b b。由于激光雷达可以直接观测到深度,我们首先初始化LIS并获得 x x x和 b b b。然后,根据图像时间戳将它们与每个图像关键帧相关联。请注意,假设IMU零偏在两个图像关键帧之间是恒定的。最后,使用LIS中估计的 x x x和 b b b作为VIS初始化的初始猜测,这显著提高了初始化速度和鲁棒性。在补充视频1中可以找到有LIS帮助和没有LIS帮助时的VIS初始化的比较。
2) 特征深度关联
在VIS初始化时,我们使用估计的视觉里程计将激光雷达帧配准到相机帧。由于现代3D激光雷达通常会产生稀疏扫描,因此我们堆叠多个激光雷达帧以获得稠密的深度图。要将特征与深度值关联,我们首先将视觉特征和激光雷达深度点投影到以相机为中心的单位球体上。然后使用球体上恒定密度的极坐标对深度点进行下采样和存储。通过使用视觉特征的极坐标搜索二维K-D树,在球体上查找视觉特征的最近三个深度点。最后,特征深度是视觉特征和相机中心 O C O_C OC形成的线的长度,该线与笛卡尔空间中三个深度点形成的平面相交。该过程的可视化如图3(a)所示,其中特征深度是虚线直线的长度。
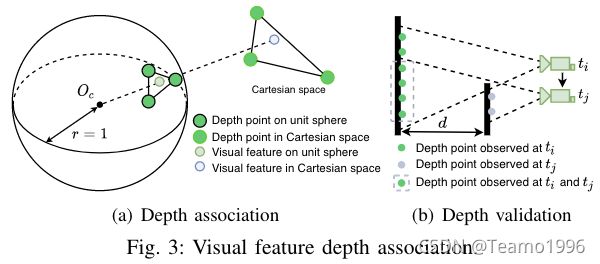
通过检查三个最近深度点之间的距离,我们进一步验证了相关的特征深度。这是因为叠加来自不同时间的激光雷达帧可能会导致来自不同对象的深度模糊。这种情况的说明如图3(b)所示。在时刻 t i t_i ti观察到的深度点用绿色表示。相机在时刻 t j t_j tj移到了一个新的位置,观察到了新的深度点,它被表示为灰色。然而,由灰色虚线环绕的在时刻 t i t_i ti的深度点由于激光雷达帧的叠加在时刻 t j t_j tj仍然可以观察到。使用不同对象的深度点关联特征深度会导致估计不准确。与[17]类似,我们通过检查一个特征的深度点之间的最大距离来拒绝这种假设。如果最大距离大于2m,则特征没有关联的深度。
配准深度地图和可视化特征的演示如图4所示。
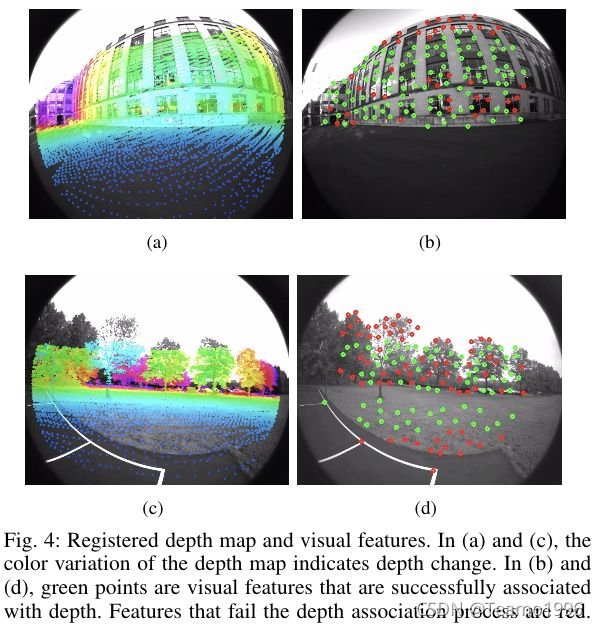
在图4(a)和(c)中,使用视觉里程计配准的深度点投影到相机图像上。在图4(b)和(d)中,与深度值成功关联的视觉特征为绿色。请注意,尽管深度图覆盖了图4(a)中的大部分图像,但由于验证检查失败,4(b)中位于窗口角落的许多特征缺少深度关联。
3) 故障检测
VIS因剧烈运动、光照变化和弱纹理的环境而失败。当机器人进行攻击性运动或进入弱纹理环境时,跟踪特征的数量会大大减少。特征不足可能导致优化发散。我们还注意到,当VIS出现故障时,会出现较大的IMU零偏估计。因此当被跟踪的特征的数量低于阈值,或当被估计的IMU零偏超过阈值时,我们报告VIS故障。主动故障检测对于我们的系统来说是必要的,这样它的故障就不会破坏LIS的功能。一旦检测到故障,VIS将重新初始化并通知LIS。
4) 闭环检测
我们利用DBoW2[24]进行闭环检测。对于每个新的图像关键帧,我们提取BRIEF描述子[25],并将其与先前提取的描述子相匹配。DBoW2返回的闭环候选关键帧的图像时间戳被发送到LIS用于进行进一步的验证。
C. 雷达惯性系统
提出的激光雷达惯性系统(改编自[14],它保持了全局位姿优化的因子图)如图5所示。
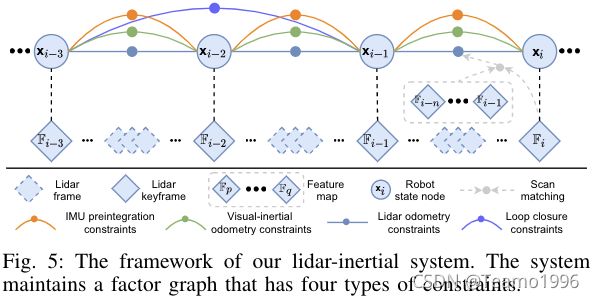
图中添加了四种类型的约束,即IMU预积分约束、视觉里程计约束、雷达里程计约束和闭环约束,并进行了联合优化。激光雷达里程计约束源自扫描匹配,其中我们将当前激光雷达关键帧匹配到全局特征地图。闭环约束的候选首先由VIS提供,然后通过扫描匹配进一步优化。我们为特征地图保留一个激光雷达关键帧滑动窗口,以保证有限的计算复杂度。当机器人位姿的变化超过阈值时,将选择一个新的激光雷达关键帧。在关键帧对之间进行的临时激光雷达帧扫描将被丢弃。选择新的激光雷达关键帧后,新的机器人状态 x x x将作为节点添加到因子图中。以这种方式添加关键帧不仅可以实现内存消耗和地图密度之间的平衡,还可以帮助保持相对稀疏的因子图以进行实时优化。由于空间限制,我们请读者参考[14]了解实现细节。在以下部分中,我们将重点介绍提高系统鲁棒性的新程序。
1) 初始猜测
我们发现,初始猜测对扫描匹配的成功起着至关重要的作用,特别是当传感器经历剧烈运动时。初始化LIS之前和之后,初始猜测的来源不同。
在 LIS 初始化之前,我们假设机器人从零速度的静止位置开始。 然后我们在假设零偏和噪声为零值的情况下积分原始 IMU 测量。两个激光雷达关键帧之间的积分后的平移和旋转变化产生扫描匹配的初始猜测。 我们发现当初始线速度小于 10m/s 且角速度小于 180°/s 时,这种方法可以在具有挑战性的条件下成功初始化系统。 LIS 初始化后,我们在因子图中估计 IMU 零偏、机器人位姿和速度。然后我们将它们发送到 VIS 以帮助其初始化。
LIS初始化后,我们可以从两个来源获得初始猜测:零偏矫正后积分的IMU测量和VIS。当视觉惯性里程计可用时,我们使用它作为初始猜测。如果VIS报告失败,我们将切换到IMU测量进行初始猜测。这些程序可在纹理丰富和弱纹理的环境中提高初始猜测的准确性和鲁棒性。
2) 故障检测
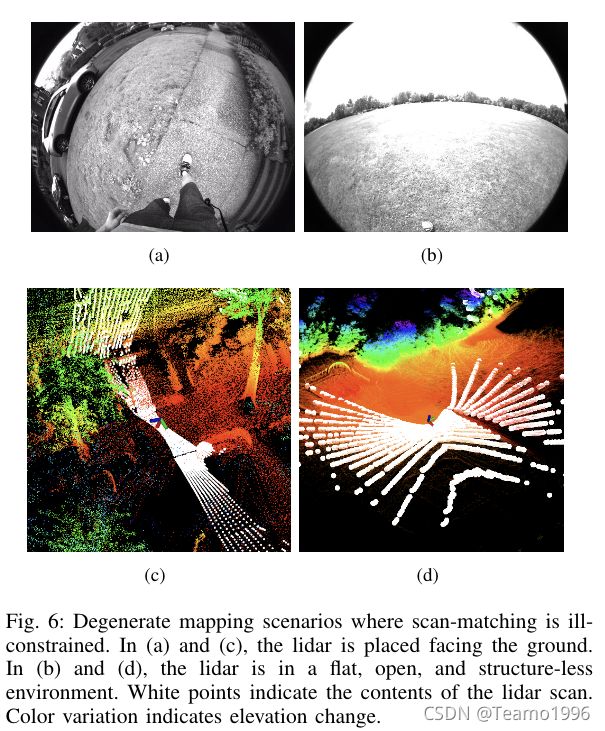
尽管激光雷达可以在远距离捕获环境的细节,但它仍然会遇到扫描匹配被弱约束的退化场景。这些场景如图6所示。
我们采用[26]中的方法进行LIS故障检测。扫描匹配中的非线性优化问题可表述为迭代求解线性问题:
min T ∣ ∣ A T − b ∣ ∣ 2 (1) \min_{T}{|| AT-b ||^2} \tag{1} Tmin∣∣AT−b∣∣2(1)
其中 A A A和 b b b通过针对 T T T线性化获得。当在优化的第一次迭代中, A T A A^TA ATA的最小特征值小于阈值时,LIS报告失败。发生故障时,不会将激光雷达里程计约束添加到因子图中。我们请读者参考[26],了解这些假设所依据的详细分析。
实验
现在,我们描述了一系列实验,以在三个自收集的数据集上验证所提出的框架,这三个数据集分别是对应于Urban、Jackal和Handheld。这些数据集的详细信息在以下章节中提供。我们用于数据采集的传感器套件包括一个Velodyne VLP-16线激光雷达、一个FLIR BFS-U3-04S2M-CS相机、MicroStrain 3DM-GX5-25 IMU和Reach RS+GPS(用于地面真值)。我们将所提出的框架与开源解决方案进行比较,包括VINS-Mono、LOAM、LIO-mapping、LINS和LIO-SAM。所有这些方法都是在C++中实现的,并在INTILIE710710U笔记本上使用Ubuntu Linux执行。我们的LVI-SAM和数据集的实现可在下面的链接获得。
A. Ablation Study
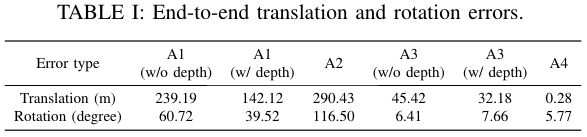
我们使用Urban数据集展示了系统中每个模块的设计如何影响所提出框架的性能。该数据集以建筑物、停放和移动的汽车、行人、骑自行车的人和植被为特征,由携带传感器套件的操作员行走来收集。我们还特意将传感器套件放置在具有挑战性的位置(图6(a)),以验证系统在退化场景中的鲁棒性。由于密集的植被,该地区没有GPS信号。我们在同一位置开始和结束数据收集过程,以验证端到端的平移和旋转误差,如表I所示。

1)A1-视觉惯性里程计中包含来自激光雷达的特征深度信息的影响
我们禁用 LIS 中的扫描匹配并仅依靠 VIS 执行位姿估计。 在图 7 中,启用和不启用深度配准的所得的结果轨迹标记为 A1。轨迹方向为顺时针方向。 当将深度与视觉特征相关联时,表 I 中显示的端到端位姿误差大大减少。
2) 包括视觉惯性里程计的影响
我们禁用VIS,仅使用LIS进行位姿估计。当遇到退化场景时,图7中标记为A2的轨迹会偏离几次。
3) 在激光雷达视觉惯性里程计中包含来自激光雷达的特征深度信息的影响:
现在我们一起使用VIS和LIS,在VIS中切换深度配准模块,以比较生成的LVIO轨迹。在视觉特征深度的帮助下,平移误差进一步降低了29%,从45.42m降低到32.18m。请注意,在本测试中禁用闭环检测,以在纯里程计模式下验证系统。
4) A4-包括视觉闭环检测的影响:
我们通过在VIS中启用闭环检测功能来消除系统的漂移。在框架中启用每个模块时的最终轨迹在图7中标记为A4。
B. Jackal 数据集
Jackal数据集是通过将传感器套件安装在Clearpath Jackal无人地面车辆(UGV)上收集的。我们在特征丰富的环境中手动驱动机器人,从同一位置开始和结束。如图8(a)所示,环境以结构、植被和各种路面为特征。GPS接收可用的区域用白点标记。

我们比较了各种方法,并在图9(a)中显示了它们的轨迹。

我们通过手动开启和关闭闭环矫正功能,进一步验证了具有闭环矫正功能的方法的准确性。基准测试结果如表二所示。
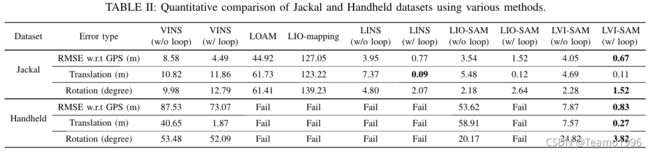
LVI-SAM实现了相对于被视为地面真值的GPS测量的最低平均均方根误差(RMSE)。最低端到端平移误差由LINS实现,LINS改编自LeGO-LOAM[11],专门设计用于UGV操作。最低端到端旋转误差再次由LVI-SAM实现。
C. Handheld 数据集
Handheld数据集由携带传感器套件的操作员在几个开阔场地周围行走收集,如图8(b)所示。这个数据集也在同一位置开始和结束。我们通过一个开放的棒球场来增加这个数据集的挑战,这个棒球场位于图像的顶部中心。当通过该场时,相机和激光雷达收集的主要观测值分别为草地面和地平面(图6(b)和(d))。由于上述的退化问题,所有基于激光雷达的方法都无法产生有意义的结果。本文提出的框架LVI-SAM在启用或不启用闭环矫正的情况下成功完成了测试,在表2中列出的所有三个基准测试标准中实现了最低的误差。
结论
我们提出了LVI-SAM,一个通过平滑和映射实现的紧耦合激光雷达视觉惯性里程计的框架,用于在复杂环境中执行实时状态估计和建图。该框架由两个子系统组成:视觉惯性系统和激光雷达惯性系统。这两个子系统设计为以紧耦合的方式交互,以提高系统的鲁棒性和准确性。通过对不同规模、平台和环境下的数据集进行评估,我们的系统显示出与现有公开可用方法相当或更好的准确性。我们希望我们的系统将成为一个坚实的基础,其他人可以很容易地在此基础上推进激光雷达视觉惯性里程计的最新发展。