论文笔记:Self-critical Sequence Training for Image Captioning
Self-critical Sequence Training for Image Captioning
1.提出问题
-
文本的生成模型通常经过训练,以使用反向传播在给定前一个 ground-truth 单词的情况下最大化下一个 ground-truth 单词的可能性。这种方法被称为 ”Teacher Forcing“ 。但是,这种方法会在训练和测试之间造成不匹配,因为在测试时,模型使用模型分布中先前生成的单词来预测下一个单词。这种 exposure bias 会导致测试时生成过程中的错误累积,因为该模型从未暴露于自己的预测中。
-
之前这个问题是用 “Professor Forcing” 解决的,它使用对抗训练,来使从网络中采样的上文词汇尽量贴合 ground truth。但之前的方法,模型训练的时候用的是cross entropy loss,而evaluate的时候却用的是BLEU、ROUGE、METEOR、CIDEr等评价指标,存在不对应的问题。
-
由于生成单词的操作是不可微的,无法通过反向传播来直接优化这些metrics,因此很多工作开始使用强化学习来解决这些问题。但强化学习在计算期望梯度时的方差会很大,通常来说是不稳定的。又有些研究通过引入一个baseline来进行偏差校正。还有一些方法比如Actor-Critic,训练了一个critic网络来估算生成单词value,但这些也是不稳定的。
2.提出创新点
本文提出了一种新的序列训练方法,称之为 self-critical sequence training (SCST),并证明 SCST 可以显着提高图像描述系统的性能。 SCST 是一种强化算法,它不是估计 reward ,而是使用了自己在测试时生成的句子作为baseline。sample 时,那些比baseline好的句子就会获得正的权重,差的句子就会被抑制。
3.方法
3.1、Captioning Models
FC models:
首先,使用 CNN 对输入图像F进行编码,然后乘上一个嵌入矩阵 WI,得到一个x1。把生成的单词送入LTSM:

Φ \Phi Φ是一个2单元的非线性 maxout 函数, ⊗ \otimes ⊗代表单元;σ 是sigmoid函数。
每个单词xt可以看作一个独热向量乘上一个维度和WI一样的嵌入矩阵E。
BOS代表每个句子的开始,EOS代表结束。
h0和co初始化为0。
LSTM 使用 softmax 函数输出下一个单词 wt 的分布:(1)
![]()
之后让θ 表示模型的参数,参数 θ 是通过最大化观察到的序列的可能性来学习的。具体来说,给定一个目标ground truth 序列(w∗1,…,w∗T),目标是最小化交叉熵损失(XE):
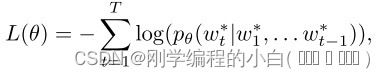
其中 pθ(wt|w1, . . . , wt−1) 由方程(1)中的参数模型给出。
Attention Model (Att2in):
修改了LSTM,把 attention 特征仅输入到 cell node 中:

其中 It 是 attention-derived image feature,代表对于N个不同位置的特征,它计算过程为:

h0和co同样初始化为0。
作者发现使用ADAM方法优化的时候,这种结构的表现优于其他结构。
3.2、Reinforcement Learning
把序列生成看作是一个RL的问题:
- Agent: LSTM
- Environment: 单词和图像的特征
- Action: 预测下一个生成的单词
- State: LSTM 的单元和隐藏状态、注意力权重等
- Reward: 生成句子的 CIDEr 分数
训练的目标是最小化Reward的负的期望:
![]()
ws = (ws1, . . . ,wsT) 是在时间步t从模型中采样的单词。
实际上,L( θ \theta θ)来自p θ \theta θ的单个样本估计(而不是选择概率最大的那一个):

带有 REINFORCE 的策略梯度:
使用REINFORCE方法计算上述目标函数的梯度:
![]()
推导过程:

在实践中,期望梯度可以通过使用单个蒙特卡洛抽样从p θ \theta θ中抽样ws近似。对于小批量中的每个训练样例:
![]()
带有 Baseline 的 REINFORCE:
由 REINFORCE 给出的策略梯度可以推广到计算与相对于参考奖励或基线 b 的 action 值相关的奖励:
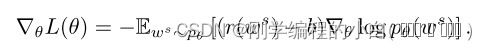
基线可以是任意函数,只要它不依赖于“action”ws ,因为在这种情况下:
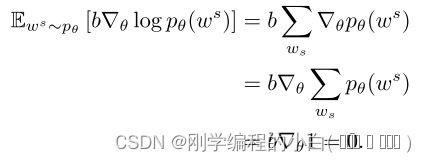
这说明b不会改变预期梯度,但重要的是,它可以降低梯度估计的方差。对于每个训练案例,我们再次使用单个样本 ws∼pθ 来近似预期梯度:
![]()
最终梯度表达式:
根据链式法则和编码过程中注意力参数模型p θ \theta θ:

其中st是注意力模型中softmax函数的输入。使用带有基线b的 REINFORCE 算法, 的梯度计算为:
的梯度计算为:

(Reinforcement learn-ing neural turing machines. 推导这篇论文提到,但没看懂啥意思。)
3.3、Self-critical sequence training (SCST)
自临界序列训练 (SCST) 方法的中心思想是将 REINFORCE 算法与当前模型在测试时使用的推理算法下获得的 reward 作为基线。
来自模型的样本 ws 的负奖励的梯度,到时间步 t 处的 softmax 激活然后变为:
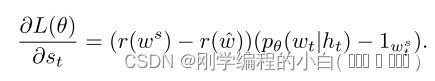
其中 r(w^) 是当前模型在测试时使用的推理算法下获得的 reward。
因此,模型中reward高于w^的样本将被“提高”或概率增加,而导致reward较低的样本将被抑制。
对于如果当前sample到的词比测试阶段生成的词好,那么在这次词的维度上,整个式子的值就是负的(因为等式右边一定为负),这样梯度就会上升,从而提高这个词的分数,而对于其他词,等式右边一定为正,梯度就会下降,从而降低其他词的分数。
我们使用贪婪解码:
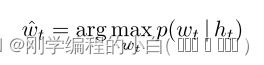
SCST阶段的训练过程如图所示:
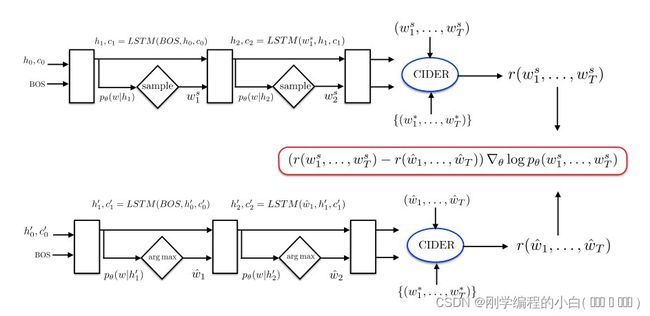
这样,最大限度地减少了使用测试时间推理算法进行基线对训练时间的影响,因为它只需要一个额外的前向传递,并训练系统进行优化,以在测试时间进行快速、贪婪的解码。