Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
1.3 分词器结构
1.3.1 分词器整体结构
从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关系图,把TokenStream和他的儿孙们统统拉上去,就能比较好的把握他们之间的关系。
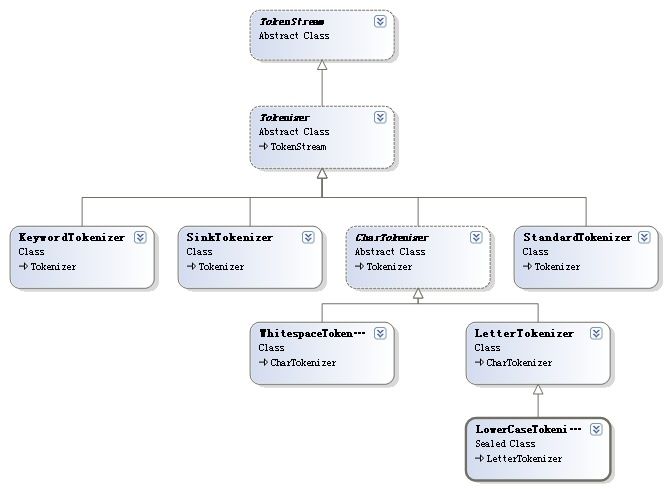
图 1.3.1.1
如图1.3.1.1 就是他们的类关系图。看出如果要做一个分词器,最短的路,就是继承第二代,成为第三代。然后再写一个Analyzer的子类,专门用来做新分词器的适配器就好了。转换器。 呵呵,写Analyzer的过程,就是实践适配器模式的过程。(这里是直接使用了Tokenizer的实例,不能算是适配器模式,更正,感谢老赵指正。 2008年9月1日 2:23:23)
1.3.2 分词器调用流程
光有整体结构还不行,还有了解方法和方法是如何被调用的。还是以最简单的KeywordTokenizer来作为分析对象。
入口毫无疑问,就是KeywordTokenizer的构造函数。然后就是调用Next方法,这是再简单不过的事情。而这里就是要让每次调用Next方法都可以出来一个分词。这个过程可以这么来描述:
(1)、分词,把一句话,一段话或者一篇文章按一个规则划分为N份;
(2)、把这N份片断存储到一个数组中,要同时记录这个片断的内容,还要记录它相对开始位置的偏移;
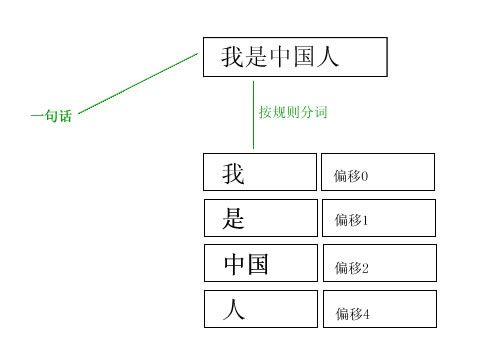
(3)、每次调用Next方法,就从上面的数组中取出一个片段;
(4)、片段取完就返回null值;
(5)、发现null值,分词过程结束。
明白以上流程,就可以开始自己写分词器了,嘿嘿。
2.1 自己动手写分词
自己写分词,光知道上面的还不够。自己写分词,首先,你要有个目标,目标是干嘛的呢?就是你这个分词到底是给什么用的,要做到什么程度。比方说,分词是给英文的还是中文的,还是中英文混合,还是还包含了日文。英文的写作规则,单词一空格划分,比较好区分,但是中文的怎么办?归结起来,现在将面临三个问题:
(1)、分词器要分什么东西,怎么才能达到目的,其实就是字符串怎么截取的问题;
(2)、分词器的准确度如何,分词速度如何,怎么做取舍,这是个算法的问题;
(3)、剩下的问题才是如何用Lucene.Net可以理解的方式写出来,这一步,上面讲了那么多小节,却是三个问题的最简单的一个。
2.1.1 最简单的分词方式
这里的最简单指的是用最少代码的方式。好,现在来个最简单的,写成代码2.1.1.1的方式总是最简单了吧?
代码 2.1.1.1
using System;
using Lucene.Net.Analysis;
namespace Test.Analysis
{
public class
{
}
}
太好了,终于写出来了,下面包装一下,写个Analyzer类。
代码 2.1.1.2
using Lucene.Net.Analysis;
namespace Test.Analysis
{
public class EsayAnalyzer : Analyzer
{
public override TokenStream TokenStream(string fieldName, System.IO.TextReader reader)
{
return new
}
}
}
立刻测试一下(测试方法见1.1.1节,具体测试则加入1.1.2节的AllAnalysisTest中,测试代码见 2.1.1.3)。
测试结果:
NUnit的gui崩溃了!!!
这个代码实在太强大了,让测试工具崩溃了!这个问题在1.2.1节讲过,Next方法和Next(Token)方法,在父类中是相互调用的,那会产生什么后果?这就像是个死循环,这个递归永远没办法结束,所以到一定次数以后,会堆栈溢出。所以我们写的分词器必须自己实现一个Next方法,哪怕什么都不做。而另外一个问题就是EsayAnalyzer类总是能拿到一个流,但是现在没办法传到分词器里来,所以,分词器必须有个能传入流的构造函数。对代码修正,如代码2.1.1.3。
代码 2.1.1.3
![]() Code
Code







 }
} }
}
同时把EsayAnalyzer 类对EsayTokenizer类的调用改成return new EsayTokenizer(reader)。OK,测试结果:
Test.Analysis.EsayAnalyzer结果:
--------------------------------
--------------------------------
什么也没有,这个在预料之中。和KeywordTokenizer分词器不同,KeywordTokenizer分词器是什么都有,而且没做任何处理。现在呢是什么都没了。还有一种写法是和这种不相上下的。如代码2.1.1.4。
代码 2.1.14
![]() Code
Code
测试结果:
Test.Analysis.EsayTooAnalyzer结果:
--------------------------------
,
--------------------------------
有个逗号了!!!哈哈,总算进步了。而把IsTokenChar方法改一下,改成:
protected override bool IsTokenChar(char c)
{
return c == ',' ? false : true;
}
Test.Analysis.EsayTooAnalyzer结果:
--------------------------------
我是中国人,I'can speak chinese
hello world,沪江小Q!
--------------------------------
这下除了逗号,什么都有了。
改成:
protected override bool IsTokenChar(char c)
{
return c == ',' ? false : false;
}
就什么都没了,要是两个都是true,会得什么结果呢?