YOLOv5改进之二十:Involution新神经网络算子引入网络
前 言:作为当前先进的深度学习目标检测算法YOLOv5,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv5的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。
需要更多程序资料以及答疑欢迎大家关注——微信公众号:人工智能AI算法工程师
解决问题:对于经典卷积conv,在神经网络中一直以来都是中流砥柱般的存在,其具有两个特性:spatial-agnostic and channel-specific(空间不可知和通道特定)。在空间范围上:前者通过在不同位置之间重用卷积核来保证卷积核的效率,并追求平移等效性。在通道域中:一系列卷积核负责收集不同通道中编码的各种信息,满足后一特性。自从VGGNet出现以来,现代神经网络通过限制卷积核的空间跨度不超过3*3 来满足卷积核的紧凑性。conv缺点:1、它剥夺了卷积核适应不同空间位置的不同视觉模式的能力。2、局部性限制了卷积的感受野,对小目标或者模糊图像构成了挑战。3、卷积滤波器内部的冗余问题突出,卷积核的灵活性受到影响。为了克服这些经典卷积所存在的这些局限性,所以本文作者提出了involution这个概念在involution运算过程中,内卷具有空间特定性和通道不可知“spatial-specific and channel-agnostic”(与convolution相反),内卷核在空间范围上是不同的,但在通道上是共享的,作者还通过在通道维数上共享involution 核来减少核的冗余。动态参数化 involution核在空间维度上具有广泛的覆盖。通过逆向设计方案,本文提出的involution 具有卷积的双重优势:1、可以在更广阔的空间中聚合上下文语义信息,从而克服了对远程交互进行建模的困难;2、可以在不同位置上自适应地分配权重,从而对空间域中信息最丰富的视觉元素进行优先排序。
原理:
论文链接:https://arxiv.org/abs/2103.06255
github代码链接:https://github.com/d-li14/involution
与上述标准卷积或深度卷积相比,卷积核 H 旨在包含空间和通道域中具有逆特征的变换,因此得名。(在论文中给involution的解释应该更契合“逆特征卷积”这个中文译名。网上也很多小伙伴译为“合卷”或者“内卷”。)
在involution的设计中,involution核是专门位于对应坐标(i,j)的像素Xi,j定制的,但在通道上共享,G计算每个组共享相同的Involution核的组数。利用Involution核对输入进行乘加运算,得到Involution的out feature map。与卷积核不同,Involution核H的形状取决于输入特征映射X的形状。设计想法是生成以原始输入张量为条件的Involution核,使输出核与输入核对齐。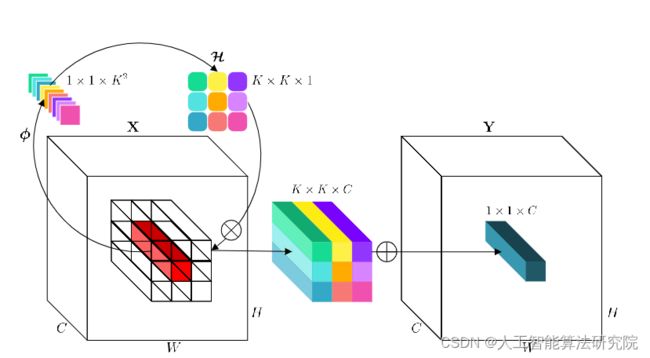
方 法:
第一步:修改common.py,定义Involution模块。
class Involution(nn.Module):
def __init__(self, c1, c2, kernel_size, stride):
super(Involution, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
self.c1 = c1
reduction_ratio = 4
self.group_channels = 16
self.groups = self.c1 // self.group_channels
self.conv1 = Conv(
c1, c1 // reduction_ratio, 1)
self.conv2 = Conv(
c1 // reduction_ratio,
kernel_size ** 2 * self.groups,
1, 1)
if stride > 1:
self.avgpool = nn.AvgPool2d(stride, stride)
self.unfold = nn.Unfold(kernel_size, 1, (kernel_size - 1) // 2, stride)
def forward(self, x):
weight = self.conv2(self.conv1(x if self.stride == 1 else self.avgpool(x)))
b, c, h, w = weight.shape
weight = weight.view(b, self.groups, self.kernel_size ** 2, h, w).unsqueeze(2)
# out = _involution_cuda(x, weight, stride=self.stride, padding=(self.kernel_size-1)//2)
# print("weight shape:",weight.shape)
out = self.unfold(x).view(b, self.groups, self.group_channels, self.kernel_size ** 2, h, w)
# print("new out:",(weight*out).shape)
out = (weight * out).sum(dim=3).view(b, self.c1, h, w)
return out第二步:将yolo.py中注册Involution模块。
第三步:改变yaml文件。
结 果:本人在多个数据集上做了大量实验,不同的数据集有不同的提升效果。
预告一下:下一篇继续分享YOLOv5改进。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦,csdn回复不及时欢迎添加微信公众号:人工智能AI算法工程师 。
PS:Involution的方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络,比如YOLOv4、v3等。
最后,希望能互粉一下,做个朋友,一起学习交流。