滚蛋吧小广告!我现在用命令行解压缩;当哥白尼遇上人工智能;一份傲娇的深度学习技术清单;一个视频尽览旷视20项前沿技术 | ShowMeAI资讯日报

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
『2022旷视技术开放日』,20个重磅技术Demo演示视频B站合辑
https://www.bilibili.com/video/BV1ur4y177jA
7月15日,2022旷视技术开放日(MegTech 2022)在北京举行,旷视联合创始人、CEO印奇在演讲中阐释了旷视的『AIoT战略』及『2+1核心技术科研体系』。但这不是我们今天的重点~
17日,官方账号(旷视MEGVII)在B站发布了『前沿技术探索』『软硬协同设计』『算法量产』『产品技术』4个话题、20款技术产品 Demo 的讲解&演示视频,每个视频 3-4 分钟,覆盖 VR、自动驾驶、AI绘画、3D重建、3D人物生成、物体检测等技术方向。演示很生动!互动很好玩!这比论文和图文直观多了,推荐感兴趣的小伙伴们去看看~
工具&框架
『Ouch』更快的命令行压缩/解压缩工具
https://github.com/ouch-org/ouch
Ouch 是 Obvious Unified Compression Helper 的缩写,是一个命令行界面工具,可以压缩和解压缩 .tar .zip .bz 等多种格式的文件。工具在易用性方面做了很多努力,比如自动检测格式、所有格式的使用语法相同、没有运行时的依赖性等。对比tar,它有着更快速的压缩速度!
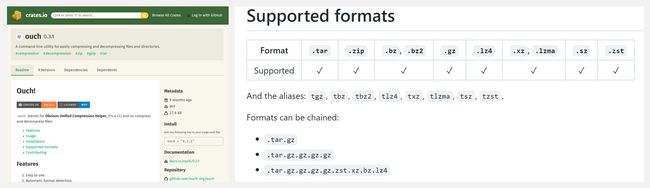
『Asent』基于spaCy的情感分析库
https://github.com/KennethEnevoldsen/asent
Asent 是一个基于规则的 Python 情感分析库,使用一个包含正面/负面评价的词汇字典 & 一系列规则,来确定一个词、句子或文件是正面还是负面的。目前的规则考虑了否定词(如 不高兴/not happy)、增强词(如 非常高兴/very happy),并考虑了对比性连接词(如 但是/but),以及其他强调标记(如感叹号、大小写和问号)。Repo 详细介绍了情感计算的流程,配图是例句『i am not very happy』的运行过程与解释。
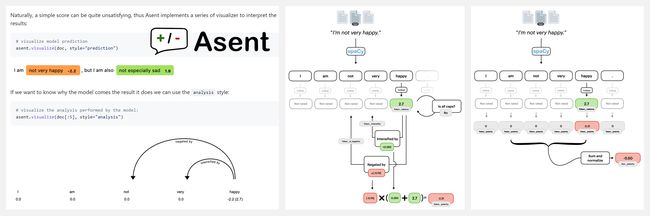
『AQP』语音/音频的质量评估平台
https://github.com/QxLabIreland/AQP
AQP (Audio Quality Platform,音频质量平台),是一个高度模块化的 pipeline,非常易于使用,可以对语音/音频的各类质量指标 (如 ViSQOL、PESQ、Warp-Q 等) 进行客观的测试和比较,以提高研发的稳健性、可重复性和开发速度。
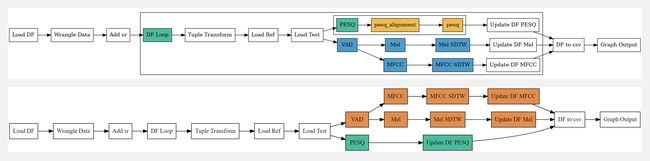
『Gorse』用 Go 编写的开源推荐系统
https://github.com/gorse-io/gorse
https://gorse.io/
Gorse 是一个使用 GO 语言编写的开源推荐系统。将项目、用户和交互数据导入 Gorse 后,系统将自动训练模型为每个用户生成推荐!作者总结了几个项目的特点(或者说优点),看看哪点让你心动了:
- 多源推荐:对于用户,从不同的方式(流行、最新、基于用户、基于项目和协同过滤)收集推荐项目,并通过点击率预测进行排名。
- AutoML:通过后台模型搜索自动选择最佳推荐模型和策略。
- 分布式推荐:单节点训练,分布式预测,在推荐阶段实现水平扩展的能力。
- RESTful API:为数据 CRUD 和推荐请求提供 RESTful API。
- Dashboard:提供数据导入导出、监控、集群状态检查的dashboard。
『ATOM Calibration』多传感器、多模态、机器人系统的校准工具
https://github.com/lardemua/atom
ATOM (Atomic Transformations Optimization Method,原子变换优化法) 由自动化和机器人实验室开发,用于多传感器、多模态、机器人系统的校准,是对 ROS-Robot 提出的 atomic transformations 理论的进一步优化。ATOM提供了几个脚本,囊括校准程序的所有步骤。详细的安装和使用说明可以查看官方文档。

博文&分享
聚焦『大语言模型对齐』的深度学习进阶课程
https://github.com/jacobhilton/deep_learning_curriculum
作者的研究领域聚焦在『大语言模型对齐』,因此这门课程也是对该领域内容和前沿研究结果的梳理。课程共8章,每章包含推荐阅读、可选阅读和建议练习三个部分,课前需要具备概率、微积分、编程等知识基础。作者反复警告,课程难度较高,沉浸学习需要较长的时间,最好是跟一位导师或者小伙伴一起进行。项目文档非常完备,给作者点个赞~

数据&资源
『CALLISTO』可用于人工智能研究的 Copernicus(哥白尼) 数据集清单
https://github.com/Agri-Hub/Callisto-Dataset-Collection
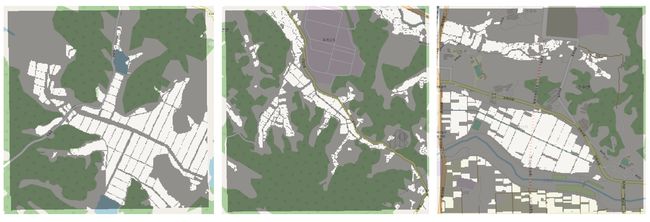
Copernicus (哥白尼) 是欧盟的一项地球观测计划,提供来自卫星、陆基、机载和海上测量系统的大量全球数据信息,通过数千个分布在陆地、空中和海洋的传感器组成的全球网络,创建了最详细的地球图片。项目的绝大多数信息是免费和完整开放的。
CALLISTO 在 Copernicus Data 上更进一步,提供了一个交互操作的大数据平台,将地球观测数据、地理参考数据与无人驾驶飞行器的观测结果相结合,研究人工智能技术在农业政策制定、水资源管理、新闻和边境安全管理等实际场景中的使用。项目页面列写了包括『来自Mapillary的带注释的街道图像』『韩国的水稻标示点(2018)』在内的几十个数据集的详细信息。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.07.11 『知识库』 COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary or Truncated Texts
- 2022.07.17 『机器学习』 Open-Sampling: Exploring Out-of-Distribution data for Re-balancing Long-tailed datasets
- Findings (NAACL) 2022 『自然语言处理』 Fine-grained Image Captioning with CLIP Reward
- 2022.05.05 『机器学习』 Approximate Convex Decomposition for 3D Meshes with Collision-Aware Concavity and Tree Search
⚡ 论文:COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary or Truncated Texts
论文标题:COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary or Truncated Texts
论文时间:11 Jul 2022
所属领域:知识库
对应任务:Link Prediction,链接预测
论文地址:https://arxiv.org/abs/2207.04675
代码实现:https://github.com/ku21fan/coo-comic-onomatopoeia
论文作者:Jeonghun Baek, Yusuke Matsui, Kiyoharu Aizawa
论文简介:To encourage research on this topic, we provide a novel comic onomatopoeia dataset (COO), which consists of onomatopoeia texts in Japanese comics./为了鼓励这方面的研究,我们提供了一个新的漫画拟声词数据集(COO),其中包括日本漫画中的拟声词文本。
论文摘要:识别不规则文本一直是文本识别中的一个挑战性话题。为了鼓励这方面的研究,我们提供了一个新颖的漫画拟声词数据集(COO),它由日本漫画中的拟声词文本组成。COO有许多任意的文本,如极度弯曲的、部分缩小的文本,或任意放置的文本。此外,有些文本被分成了几个部分。每个部分都是一个被截断的文本,本身没有意义。这些部分应该被联系起来,以代表预期的意义。因此,我们提出了一个新颖的任务,预测截断的文本之间的联系。我们进行了三个任务来检测拟声词区域并捕捉其预期的含义:文本检测、文本识别和链接预测。通过广泛的实验,我们分析了COO的特点。我们的数据和代码可在 https://github.com/ku21fan/COO-Comic-Onomatopoeia 获取。

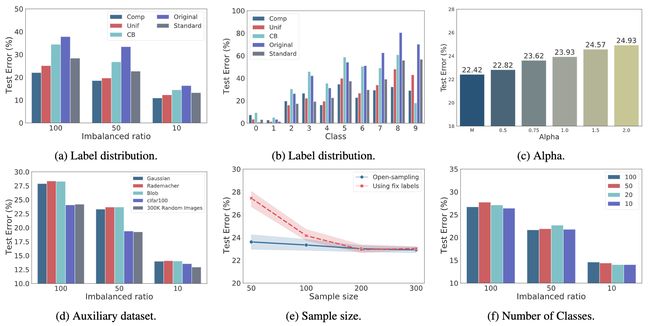
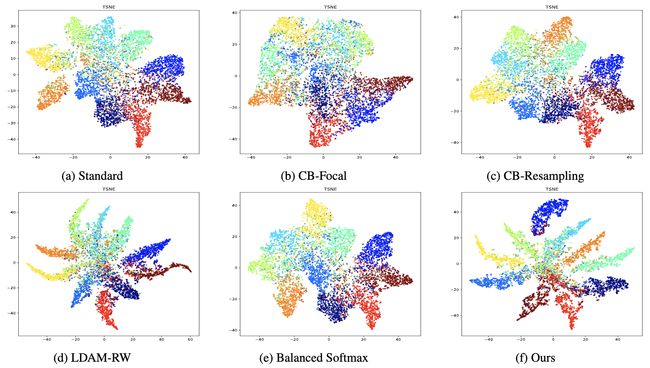
⚡ 论文:Open-Sampling: Exploring Out-of-Distribution data for Re-balancing Long-tailed datasets
论文标题:Open-Sampling: Exploring Out-of-Distribution data for Re-balancing Long-tailed datasets
论文时间:17 Jun 2022
所属领域:机器学习
论文地址:https://arxiv.org/abs/2206.08802
代码实现:https://github.com/hongxin001/logitnorm_ood,https://github.com/hongxin001/open-sampling
论文作者:Hongxin Wei, Lue Tao, Renchunzi Xie, Lei Feng, Bo An
论文简介:Deep neural networks usually perform poorly when the training dataset suffers from extreme class imbalance./深度神经网络在训练数据集遭受极端的类不平衡时通常表现不佳。
论文摘要:当训练数据集遭受极端的类不平衡时,深度神经网络通常表现得很差。最近的研究发现,以半监督的方式直接用分布外的数据(即开放集样本)进行训练会损害泛化性能。在这项工作中,我们从理论上表明,从贝叶斯的角度来看,分布外的数据仍然可以被利用来增加少数人的类别。基于这一动机,我们提出了一种叫做开放采样的新方法,它利用开放集的噪声标签来重新平衡训练数据集的类别预设。对于每个开放集的实例,标签从我们预先定义的分布中抽样,该分布是对原始类预设分布的补充。我们的经验表明,开放取样不仅可以重新平衡类预设,而且可以鼓励神经网络学习可分离的表征。广泛的实验表明,我们提出的方法明显优于现有的数据再平衡方法,并能提高现有最先进方法的性能。
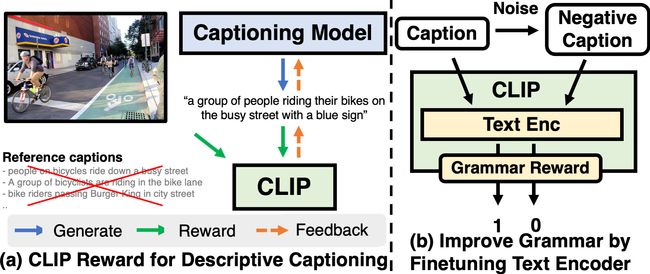
⚡ 论文:Fine-grained Image Captioning with CLIP Reward
论文标题:Fine-grained Image Captioning with CLIP Reward
论文时间:Findings (NAACL) 2022
所属领域:自然语言处理
对应任务:Image Captioning,Image Retrieval,text similarity,Text-to-Image Retrieval,图像字幕,图片检索,文本相似性,文本到图片检索
论文地址:https://arxiv.org/abs/2205.13115
代码实现:https://github.com/j-min/clip-caption-reward
论文作者:Jaemin Cho, Seunghyun Yoon, Ajinkya Kale, Franck Dernoncourt, Trung Bui, Mohit Bansal
论文简介:Toward more descriptive and distinctive caption generation, we propose using CLIP, a multimodal encoder trained on huge image-text pairs from web, to calculate multimodal similarity and use it as a reward function./为了实现更多的描述性和与众不同的标题生成,我们建议使用CLIP,这是一个多模态编码器,在互联网的海量图像-文本对上进行训练,以计算多模态的相似性并将其作为奖励函数。
论文摘要:现代的图像标题模型通常以文本相似性为目标进行训练。然而,由于公共数据集中的参考标题通常描述最突出的普通对象,以文本相似性目标训练的模型往往忽略了图像中区别于其他图像的具体和详细方面。为了实现更多的描述性和与众不同的标题生成,我们建议使用CLIP,一个在互联网上海量的图像-文本对上训练的多模态编码器,来计算多模态的相似性并将其作为一个奖励函数。我们还提出了一个简单的CLIP文本编码器的微调策略,以改善不需要额外文本注释的语法。这完全消除了奖励计算过程中对参考字幕的需要。为了全面评估描述性的标题,我们引入了FineCapEval,一个新的标题评估数据集,具有细粒度的标准:整体、背景、对象、关系。在我们关于文本到图像检索和FineCapEval的实验中,提出的CLIP指导的模型比CIDEr优化的模型产生了更有特色的标题。我们还表明,我们对CLIP文本编码器的无监督语法微调缓解了原始CLIP奖励的退化问题。最后,我们展示了人类的分析,根据各种标准,标注人员非常喜欢CLIP奖励而不是CIDEr和MLE目标。代码和数据:https://github.com/j-min/CLIP-Caption-Reward 。
⚡ 论文:Approximate Convex Decomposition for 3D Meshes with Collision-Aware Concavity and Tree Search
论文标题:Approximate Convex Decomposition for 3D Meshes with Collision-Aware Concavity and Tree Search
论文时间:5 May 2022
所属领域:机器学习
论文地址:https://arxiv.org/abs/2205.02961
代码实现:https://github.com/sarahweiii/coacd
论文作者:Xinyue Wei, Minghua Liu, Zhan Ling, Hao Su
论文简介:Approximate convex decomposition aims to decompose a 3D shape into a set of almost convex components, whose convex hulls can then be used to represent the input shape./近似凸分解的目的是将一个三维形状分解成一组几乎是凸的成分,然后用其凸壳来表示输入的形状。
论文摘要:近似凸分解的目的是将一个三维形状分解成一组几乎是凸的分量,然后用这些分量的凸壳来表示输入的形状。因此,它能够实现专门为凸形设计的高效几何处理算法,并已被广泛用于游戏引擎、物理模拟和动画。虽然先前的工作可以捕捉到输入形状的全局结构,但它们可能无法保留细粒度的细节(例如,填充烤面包机的槽),而这些细节对于保留互动环境中物体的功能至关重要。在本文中,我们提出了一种新的方法,从三个方面解决现有方法的局限性:(a)我们引入了一种新的碰撞感知的凹陷度量,从边界和内部检查形状和其凸壳之间的距离。所提出的凹陷度保留了碰撞条件,对检测各种近似错误更加稳健。(b) 我们通过直接用三维平面切割网格来分解形状。它确保了生成的凸壳是无交点的,并避免了体素化错误。© 我们建议采用多步骤的树状搜索来确定切割平面,而不是使用单步的贪婪策略,这导致了全局更好的解决方案,并避免了不必要的切割。通过对大规模铰接物体数据集的广泛评估,我们表明,我们的方法产生的分解更接近于原始形状,而且成分更少。因此,它支持下游应用中精细而有效的物体交互。我们将发布我们的实现,以促进未来的研究。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~