CS224n Part1
CS224n Part1
1 Introduction to Natural Language Processing
为什么自然语言处理如此特殊?人类语言是一种专门用于传达意义的系统,而不是由任何形式的物理表现产生的系统。不同于其他任何机器学习任务。
2 Word Vectors
我们想编码每个单词编码为能够表达单词空间的向量。
one-hot vector
表达每个单词使用 R ∣ V ∣ ∗ 1 R^{|V|*1} R∣V∣∗1类型的向量,该项列只有一个位置为1,其余位置都为0。唯一的位置为该单词在单词表中的位置。 ∣ V ∣ |V| ∣V∣为词库的长度。

这种方法我们完全独立的表达每个单词,每个词向量之间没有任何相似度。

3 SVD Based Methods
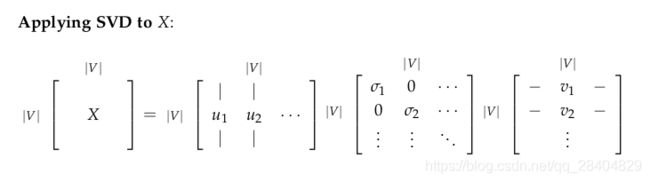
对于这类方法来查找单词嵌入,我们首先遍历大量数据集并累积后期单词共现以矩阵 X X X的某种形式计数,然后在 X X X上执行奇异值分解以获得 U S V T USV^T USVT 分解。 然后我们使用 U U U行作为所有我们字典中的单词的次嵌入。 让我们讨论一下 X X X的几个选择。
3.1 Word-Document Matrix
作为我们的第一次尝试,我们做出了大胆的猜想相关的经常出现在同一文件中。 例如,“银行”,“债券”,“股票”,“货币”等可能会一起出现。 但是“银行”,“章鱼”,“香蕉”和“曲棍球”会可能不会一直出现在一起。 我们用这个事实来构建一个单词文档矩阵, X X X按以下方式:循环结束数十亿的文件和每次出现在文件中的单词,我们在条目 X i j X _{ij} Xij中添加一个。 这显然是一个非常大的矩阵 ( R ∣ V ∣ × M ) (R ^{| V |×M}) (R∣V∣×M)并且它与文档数量 ( M ) (M) (M)成比例。
3.2 Window based Co-occurrence Matrix
矩阵 X X X存储单词的共现,从而成为亲和度矩阵。 在这方法我们计算每个单词出现在一个单词中的次数围绕感兴趣的词的特定大小的窗口。 我们计算这计算了语料库中的所有单词。

3.3 Applying SVD to the cooccurrence matrix
现在,我们对 X X X进行奇异值分解,观察奇异值(矩阵S的对角线元素),然后根据我们期望捕获到的方差占比在某个索引 k k k处将其截断:
Σ i = 1 k σ i Σ i = 1 ∣ V ∣ σ i \frac{\Sigma^k_{i=1}\sigma_i}{\Sigma^{|V|}_{i=1}\sigma_i} Σi=1∣V∣σiΣi=1kσi
然后,我们将 U 1 : ∣ V ∣ , 1 : k U_{1:|V|,1:k} U1:∣V∣,1:k的子矩阵作为我们的词嵌入矩阵。这将会为我们词汇表中每个单词提供一个 k k k维向量表示形式。
 这两种方法都给我们提供了足以编码语义和句法(词性)信息的词向量,但也存在了许多其它问题:
这两种方法都给我们提供了足以编码语义和句法(词性)信息的词向量,但也存在了许多其它问题:
新单词的频繁添加以及语料库大小的变换使得矩阵的维数变换频繁。
大部分词组不存在共现使得矩阵特别稀疏。
矩阵维度过高,通常为10^6 × 10^6。
训练的开销过大,呈二次型(如执行奇异值分解)。
需要一些技巧解决词频的急剧失衡。
针对上述存在的一些问题,有以下解决方法:
忽略一些虚词,如“the”,“he”,“has”等。
利用倾斜窗口——根据文档中词与词之间的距离来加权共现次数。
使用Pearson相关矩阵,并把负计数设置为0,而不是使用原来的计数方式。
在下面的章节中,基于迭代的方法能够以更优雅的方式解决以上的一些问题。
4 Interation Based Methods - Word2vec
我们可以尝试创建一个模型,一次性只能学习一次迭代,最终可以根据上下文语境给出一个词出现的概率;而不是像之前一样计算和存储一些庞大数据集的全部信息(可能是数10亿句)。
这一方法的主要思路就是:设计一个模型,用该模型的参数来表示词向量,然后基于语料库进行训练。在每一次迭代中,我们评估模型的误差,然后对参数进行更新。我们称这种方法为‘反向传播’误差。模型和任务越简单,模型训练的速度越快。
2个算法: continuous bag-of-words (CBOW)和skip-gram。CBOW旨在根据上下文窗口语境预测中间词。Skip-gram与之相反,他根据中心词预测该词的上下文语境。
2个训练方法: negative sampling和hierarchical softmax。negative sampling通过负抽样来定义一个目标词。然而,hierarchical softmax通过使用一个高效的树结构计算所有词汇的概率来定义目标词。
4.1 Language Models
我们需要创建一个可以计算字符序列出现概率的模型。让我们看下下面的例子:
“The cat jumped over the puddle.”
一个好的语言模型可以赋予这个句子高的概率。因为这句话符合句法和语义,通俗一点,他是一句人话。相反,应该赋予"stock boil fish is toy"这句话低的概率,因为这句话不是人话,没有任何意义。我们可以用以下数学表达式来表示给定n个单词序列的概率:
P ( w 1 , w 2 , . . . w n ) P(w_1,w_2,...w_n) P(w1,w2,...wn)
我们假定每个单词的出现时相互独立的,那么上面的一元模型的概率可以拆散为以下形式:
P ( w 1 , w 2 , . . . w n ) = ∏ i = 1 n P ( w i ) P(w_1,w_2,...w_n)=\quad \prod_{i=1}^nP(w_i) P(w1,w2,...wn)=i=1∏nP(wi)
然而,我们知道这有一些荒唐,因为下一个词的出现高度依赖于先前的单词序列。有可能导致那些愚蠢的,不像人话的句子被赋予的分数较高。因此,也许我们可以让序列的概率取决于序列中一个单词的成对概率和它旁边一个单词的概率。我们称之为二元语言模型(bigram model),表示如下:
P ( w 1 , w 2 , . . . w n ) = ∏ i = 1 n P ( w i ∣ w i − 1 ) P(w_1,w_2,...w_n)=\quad \prod_{i=1}^nP(w_i|w_{i-1}) P(w1,w2,...wn)=i=1∏nP(wi∣wi−1)
当然,这还是有点幼稚,因为我们只考虑一对相邻的词,而不是计算整个句子。但是,我们将会看到,这种表示方法使我们能够前行的更远。通过一个上下文大小为1的词矩阵,我们基本上能够获取这些成对词语的概率。但是,这需要计算和储存一个海量数据集的全部信息。
既然我们已经明白如何理解一个拥有概率性质的字符序列,那么接下来,我们将会介绍一些可以自主学习这些概率的模型。
4.2 Continuous Bag of Words Model (CBOW)
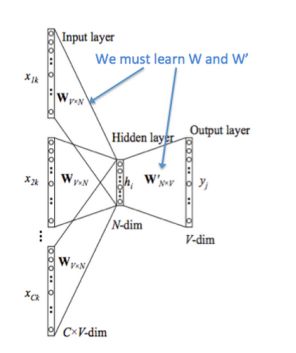

一种方法是把{‘The’, ‘cat’, ‘over’, ‘the’, ‘puddle’}作为上下文,来预测中心词语’jumped’。我们称这类模型为Bag of Words (CBOW)模型。
让我们详细地讨论下CBOW模型。首先,我们设定一些已知的参数。这些已知参数为用于表示单词的one-hot向量。我们用 x ( c ) x^{(c)} x(c)表示输入的one_hot向量(上下文),用 y ( c ) y^{(c)} y(c)表示输出。在CBOW模型中,只有一个输出,所以我们称 y y y为已知中心词的one-hot向量。接下来,让我们定义模型中未知的参数。
我们创建两个矩阵, v ∈ R n × ∣ V ∣ v∈R^{n×|V|} v∈Rn×∣V∣和 u ∈ R ∣ V ∣ × n u∈R^{|V|×n} u∈R∣V∣×n。 n n n为词嵌入向量的大小, v v v为输入词矩阵,其中,当 w i w_i wi为模型的一个输入时, v v v的第 i i i列为单词 w i w_i wi的 n n n维词嵌入向量。我们把这个 n × 1 n×1 n×1向量定义为 v i v_i vi。相似的, u u u为输出词矩阵,当 w i w_i wi模型的一个输出时, u u u的第 j j j行为单词 w j w_j wj嵌入向量。我们把 u u u的第 j j j行定义为 u j u_j uj。请注意:我们实际上为每个单词 w i w_i wi学习了两个词向量(输入词向量 v i v_i vi和输出词向量 u i u_i ui)。
模型工作包含以下几步:
1.获取输入的one-hot向量,窗口大小为m :
( x ( c − m ) , . . . , x ( c − 1 ) , x ( c + 1 ) , . . . , x ( c + m ) ∈ R ∣ V ∣ ) (x^{(c-m)},..., x^{(c-1)}, x^{(c+1)},..., x^{(c+m)}∈R^{|V|}) (x(c−m),...,x(c−1),x(c+1),...,x(c+m)∈R∣V∣)。
2.我们得到输入窗口语料的词嵌入向量
( v ( c − m ) = v x ( c − m ) , v ( c − m + 1 ) = v x ( c − m + 1 ) , . . . , v ( c + m ) = v x ( c + m ) ∈ R n ) (v_{(c-m)}=vx^{(c-m)}, v_{(c-m+1)}=vx^{(c-m+1)}, ... ,v_{(c+m)}=vx^{(c+m)}∈R^n) (v(c−m)=vx(c−m),v(c−m+1)=vx(c−m+1),...,v(c+m)=vx(c+m)∈Rn)
3.求取这些向量的平均值,得到:
v ^ = v c − m + v c − m + 1 + . . . + v c + m 2 m ∈ R n \hat{v}=\frac{v_{c-m}+v_{c-m+1}+...+v_{c+m}}{2m}\in R^n v^=2mvc−m+vc−m+1+...+vc+m∈Rn
4.生成一个分数向量(score vector): z = u v ^ ∈ R ∣ V ∣ z=u\hat{v} \in R^{|V|} z=uv^∈R∣V∣,由于向量之间越相似,其点积越高,所以相似的单词将会离得更近以得到更高的分数。
5.利用Softmax函数将分数转换为概率的形式: y ^ = s o f t m a x ( z ) ∈ R ∣ V ∣ \hat{y}=softmax(z) \in R^{|V|} y^=softmax(z)∈R∣V∣
6.我们期望预测的概率 y ^ \hat{y} y^能够与真实概率 y y y相匹配,即刚好是目标单词的one-hot向量。
既然我们已经了解了当我们拥有 v v v和 u u u两个矩阵后,我们的模型是怎么工作的。那么,我们该怎么去学习获取这两个未知参数矩阵呢?这时,我们需要创建一个目标函数。通常,当我们从某种真实概率中学习概率时,我们会借助信息理论来度量两个分布之间的距离。这里,我们使用最常用的距离/损失度量,交叉熵。在离散情况下,使用交叉熵的灵感来自于下面的损失函数:
H ( y ^ , y ) = − ∑ j = 1 ∣ V ∣ y i l o g ( y i ^ ) H(\hat{y},y)=-\sum_{j=1}^{|V|} y_ilog(\hat{y_i}) H(y^,y)=−j=1∑∣V∣yilog(yi^)
让我们考虑下CBOW这个案例,y为one-hot向量。因此,上面的损失函数可以简化为:
H ( y ^ , y ) = − y i l o g ( y i ^ ) H(\hat{y},y)=-y_ilog(\hat{y_i}) H(y^,y)=−yilog(yi^)
在这个公式中,c是指目标单词one-hot向量为1的索引。假设我们的预测非常完美时,我们可以算得:
H ( y ^ , y ) = − 1 l o g ( 1 ) = 0 H(\hat{y},y)=-1log(1)=0 H(y^,y)=−1log(1)=0。
因此,对于一个完美的预测,不会得到惩罚或者损失。假设我们的预测很差,为0.01,则我们可以得到:
H ( y ^ , y ) = − 1 l o g ( 0.01 ) ≈ 4.605 H(\hat{y},y)=-1log(0.01)\approx4.605 H(y^,y)=−1log(0.01)≈4.605
因此,我们可以看出对于概率分布,交叉熵为我们提供了一个很好的度量距离(误差)的方法。因此,我们把我们模型的优化目标设置为:

采用随机梯度下降法(stochastic gradient descent)更新所有相关的词向量 u c u_c uc和 v j v_j vj。
4.3 Skip-Gram Model
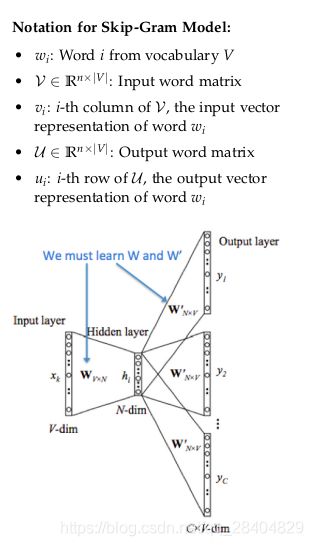
另一种方法是创建一个模型,给定一个中心单词’jumped’,该模型能够预测周边单词(上下文):‘The’, ‘cat’, ‘over’, ‘the’, ‘puddle’。这里,我们称单词’jumped’为语境(context)。我们称这类模型为Skip-Gram模型。
Skip—Gram模型和CBOW模型很相似,不过这里我们把 x x x和 y y y进行了交换,即CBOW中的 x x x现在变为了 y y y,反之亦然。我们用 x x x表示输入的one-hot向量(中心单词),尽管这里只有一个单词。用 y ( j ) y^{(j)} y(j)表示输出向量。 v v v和 u u u的定义和CBOW中的定义相同。
我们把Skip-Gram模型的工作流程拆分为以下6个步骤:
1.获取中心单词的one-hot输入向量 x ∈ R ∣ V ∣ x \in R^{|V|} x∈R∣V∣。
2.求取中心单词的词嵌入向量 v c = v x ∈ R n v_c =vx \in R^n vc=vx∈Rn。
3.计算分数向量 z = u v c z = uv_c z=uvc。
4.通过Softmax函数将分数向量转换为概率: y ^ = s o f t m a x ( z ) \hat{y}=softmax(z) y^=softmax(z)
注意:每个上下文词的概率为: y ^ c − m , . . . , y ^ c − 1 , y ^ c + 1 , . . . , y ^ c + m \hat{y}_{c-m},...,\hat{y}_{c-1},\hat{y}_{c+1},...,\hat{y}_{c+m} y^c−m,...,y^c−1,y^c+1,...,y^c+m。
5.我们期望计算出的概率和真实概率 y ( c − m ) , . . . , y ( c − 1 ) , y ( c + 1 ) , . . . , y ( c + m ) y^{(c-m)},..., y^{(c-1)}, y^{(c+1)},..., y^{(c+m)} y(c−m),...,y(c−1),y(c+1),...,y(c+m)相匹配。
正如CBOW模型那样,我们同样也需要定义一个目标函数来衡量我们的模型。最重要的一个区别是,在Skip-Gram模型中我们引入朴素贝叶斯假设来分解概率。简单地说,就是一个强条件独立假设。换句话说,给定中心单词,所有的输出单词完全相互独立。
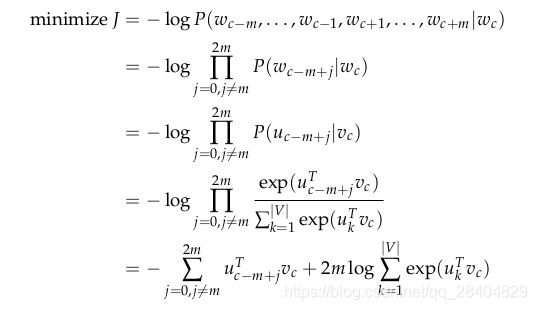
通过目标函数,我们计算未知参数的相应梯度,以及在每次迭代中通过随机梯度下降法更新这些未知参数。
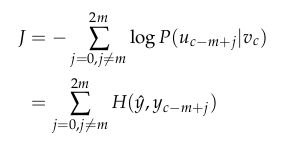
注意:
在Skip-Gram模型中,只输出了一个概率向量。Skip-Gram模型同等对待每一个背景词:模型计算每一个背景词的出现概率,和背景词到中心词的距离无关。
4.4 Negative Sampling
接下来,让我们探讨一下目标函数。在 ∣ V ∣ |V| ∣V∣维数据上进行求和的计算量巨大!目标函数的任何更新后者计算将会消耗大量的时间。我们可以尝试通过近似的方法去提高效率。
在每次训练过程中,我们可以仅仅抽取几个负样本,而不是循环遍历整个词汇表!我们从一个噪声分布 ( P n ( w ) ) (P_n(w)) (Pn(w))中抽样,其概率与词汇表中词频相匹配。如果把负抽样机制应用到模型中,我们需要调整以下几点:
目标函数
梯度
更新规则
虽然负抽样基于Skip-Gram模型,但实际上它优化了一个不同的目标函数。(w, c)(w, c分别为单词(word)和上下文(context))是否真的来自训练数据集(即w, c是否分别对应为训练集的中心词(输入)和背景词(输出)?
记 P ( D = 1 ∣ w , c ) P(D = 1|w, c) P(D=1∣w,c)为(w, c)来自语料库数据的概率,相应的 P ( D = 0 ∣ w , c ) P(D = 0|w, c) P(D=0∣w,c)为(w, c)不是来自语料库的概率。首先,我们用sigmoid函数来模拟 P ( D = 0 ∣ w , c ) P(D = 0|w, c) P(D=0∣w,c):
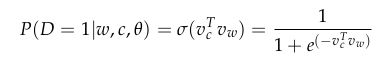
sigmoid函数为softmax的1维特殊形式,可以用于表示概率。

现在,我们建立了一个新的目标函数,试图当(w, c)来自语料库时最大化概率 P ( D = 1 ∣ w , c ) P(D = 1|w, c) P(D=1∣w,c),当(w, c)不是来自语料库时,最大化概率 P ( D = 0 ∣ w , c ) P(D = 0|w, c) P(D=0∣w,c)。我们采用最大似然估计(MLE)来计算这两个概率。(这里,我们记θ为模型的参数,在word2vec模型里对应着v和u。)
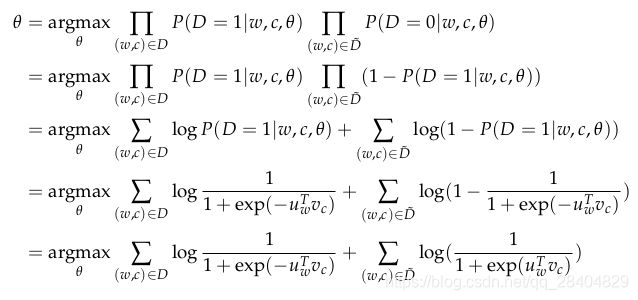 所以最大化似然函数等同于最小化下面的负对数似然函数:
所以最大化似然函数等同于最小化下面的负对数似然函数:
记 D ~ \tilde{D} D~为错误(false)/负(negative)语料库。当我们有一个句子,例如"stock boil fish is toy"。不自然的句子出现的概率应该很低。我们可以从词库里随机抽取生成负样本 D ~ \tilde{D} D~。
对于Skip-Gram模型,给定中心词c观察到上下文c-m+j的目标函数为:
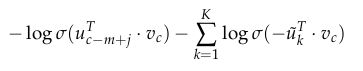
对于CBOW模型,给定(上下文)背景词向量,观察到中心词 u c u_c uc的目标函数为:
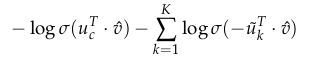
其中,负样本服从 P n ( w ) P_n(w) Pn(w)分布。但是Pn(w)该是什么样的呢?经过多次地讨论以及实验如何做出最好的近似,似乎一元文法模型(Unigram Model)的3/4次方的效果最好。为什么是3/4呢?下面的例子可能会帮助你理解一下:
is: 0.93/4 = 0.92
Constitution: 0.093/4 = 0.16
bombastic: 0.013/4 = 0.032
可以看出:"Bombastic"现在被抽到的可能性是之前的3倍,然而"is"仅仅提升了一点
4.5 Hierarchical Softmax
层次softmax对低频单词的效果较好。然而负抽样对高频单词以及低维向量的效果较好。
层次softmax采用二叉树展示词汇表中的所有单词。树的每一个叶子节点代表一个单词,并且从根节点到叶节点的路径是唯一的。在这个模型中,树的每一个节点(除了根节点和叶节点)都对应着一个向量,这个向量需要模型去学习。
给定一个向量 w i w_i wi,单词 w w w的概率 P ( w ∣ w i ) P(w | w_i) P(w∣wi)等于从根节点随机游走,最终到达叶节点 w w w的概率。这种计算概率的方式的主要优点是花销仅仅为 O ( l o g ( ∣ V ∣ ) ) O(log(|V|)) O(log(∣V∣))。
用 L ( w ) L(w) L(w)表示从根节点到叶节点w的节点数。例如(如下图所示):
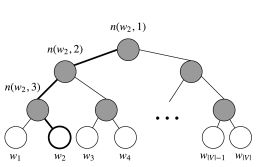
L ( w 2 ) L(w_2) L(w2)为3。用 n ( w , i ) n(w, i) n(w,i)表示路径中第 i i i个节点,对应的向量表示为 v n ( w , i ) v_{n(w,i)} vn(w,i)。所以 n ( w , 1 ) n(w, 1) n(w,1)为根节点, n ( w , L ( w ) ) n(w, L(w)) n(w,L(w))为 w w w的父节点。现在,对于每一个内层节点n,我们任意挑选一个子节点,用 c h ( n ) ch(n) ch(n)表示(例如,总抽取左节点)。然后,我们可以计算概率:

首先,我们根据从根节点(n(w,1))到叶节点(w)的路径形状计算每一项的乘积。如果我们假设ch(n)总是n的左节点,那么当路径沿着左侧行走时,[n(w, j+1) = ch(n(w, j))]为1,当沿着右侧时,为-1。
此外,[n(w, j+1) = ch(n(w, j))]起到了正则化的作用(概率的公理化定义)。即在节点n处,向左和向右的概率相加为1:
![]()
同时正则化就像在原始softmax中那样也保证了:
![]()
最后,我们使用点积计算输入向量 v w i v_{wi} vwi和每个内节点向量 v n ( w , j ) T v^T_{n(w,j)} vn(w,j)T的相似性。让我们看下示例:在上图中选取 w 2 w_2 w2,我们必须通过两个左节点和一个右节点才能从根节点到达 w 2 w_2 w2,所以:
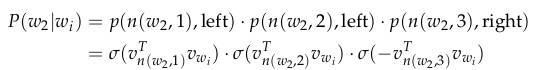
为了训练模型,我们的目标依然是最小化负对数释然 − l o g P ( w ∣ w i ) -log P(w| w_i) −logP(w∣wi)。但是我们在训练过程不再更新每个单词的输出向量,而是更新二叉树中从根节点到叶节点路径上的节点单词的向量。
参考:
https://github.com/stanfordnlp/cs224n-winter17-notes
https://www.meiwen.com.cn/subject/ujamhxtx.html