Pytorch:卷积神经网络-ResNet
Pytorch: 残差网络-ResNet
Copyright: Jingmin Wei, Pattern Recognition and Intelligent System, School of Artificial and Intelligence, Huazhong University of Science and Technology
Pytorch教程专栏链接
文章目录
-
-
- Pytorch: 残差网络-ResNet
- @[toc]
-
-
- Reference
- 残差网络(ResNet)
-
- 主要贡献
- 动机
- Residual 块
- 网络结构
- 总结
- 代码实现
-
- 残差块实现
- 网络实现,将残差块和其他块连接起来
文章目录
-
-
- Pytorch: 残差网络-ResNet
- @[toc]
-
-
- Reference
- 残差网络(ResNet)
-
- 主要贡献
- 动机
- Residual 块
- 网络结构
- 总结
- 代码实现
-
- 残差块实现
- 网络实现,将残差块和其他块连接起来
-
-
本教程不商用,仅供学习和参考交流使用,如需转载,请联系本人。
Reference
ResNet 论文链接
import torch
import torch.nn as nn
残差网络(ResNet)
VGGNet 与 Inception 出现后,学者们将卷积网络不断加深以寻求更优越的性能,然而所着网络的加深,网络却越发难以训练,方而会产生梯度消失现象: 另一方面越深的网络返回的梯度相关性会越来越差,接近于白噪声,导致梯度更新也接近于随机扰动。
更详细的说,对神经网络模型添加新的层,充分训练后的模型是否只可能更有效地降低训练误差?理论上,原模型解的空间只是新模型解的空间的子空间。也就是说,如果我们能将新添加的层训练成恒等映射 f ( x ) = x f(x)=x f(x)=x ,新模型和原模型将同样有效。由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。然而在实践中,添加过多的层后训练误差往往不降反升。即使利用批量归一化带来的数值稳定性使训练深层模型更加容易,该问题仍然存在。
何恺明等人提出的ResNet(Residual Network,残差网络) 较好地解决了这个问题,并获得了 2015 年 ImageNet 分类任务的第一名。 此后的分类、检测、分割等任务也大规模使用 ResNet 作为网络骨架。
主要贡献
提出了一种残差学习框架来减轻网络训练,这些网络比以前使用的网络更深。
显式地将层重构为学习关于层输入的残差函数,而不是学习未参考的函数。
提供了全面的经验证据说明这些残差网络很容易优化,并可以显著增加深度来提高准确性。
动机
最根本的动机就是所谓的“退化”问题,即当模型的层次加深时,错误率却提高了。
但是模型的深度加深,学习能力增强,因此更深的模型不应当产生比它更浅的模型更高的错误率。而这个“退化”问题产生的原因归结于优化难题,当模型变复杂时,SGD 的优化变得更加困难,导致了模型达不到好的学习效果。
Residual 块
通过 shortcut 连接, identity mapping 来加深网络。
ResNet 的思想在于引入了一个深度残差框架来解决梯度消失问题,即让卷积网络去学习残差映射,而不是期望每一个堆叠层的网络都完整地拟合潜在的映射(拟合函数)。如图所示,对于神经网络,如果我们期望的网络最终映射为 H ( x ) H(x) H(x) , 左侧的网络需要直接拟合输出 H ( x ) H(x) H(x) ,而右侧由 ResNet 提出的子模块,通过引入一个 shortcut (捷径)分支,将需要拟合的映射变为残差 F ( x ) : H ( x ) − x F(x): H(x)-x F(x):H(x)−x 。 ResNet 给出的假设是:相较于直接优化潜在映射 H ( x ) H(x) H(x) ,优化残差映射 F ( x ) F(x) F(x) 是更为容易的。
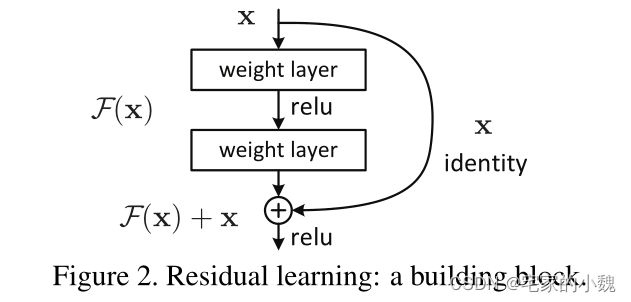
在形式上,将期望的底层映射表示为 H ( x ) H(x) H(x) ,我们让堆叠的非线性层适合 F ( x ) F(x) F(x) 的另一个映射: F ( x ) = H ( x ) − x F(x)= H(x)-x F(x)=H(x)−x 。原始映射被重铸为 F ( x ) + x F(x)+x F(x)+x 。
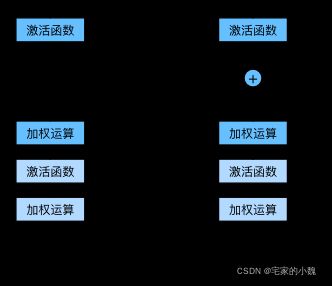
我们用更详细的图来说明二者的区别。设输入为 x x x。假设我们希望学出的理想映射为 f ( x ) f(x) f(x) ,从而作为激活函数的输入。
左图虚线框中的部分需要直接拟合出该映射 f ( x ) f(x) f(x) ,而右图虚线框中的部分则需要拟合出有关恒等映射的残差映射 f ( x ) − x f(x)−x f(x)−x 。残差映射在实际中往往更容易优化。
以恒等映射作为我们希望学出的理想映射 f ( x ) f(x) f(x) 。我们只需将图中右图虚线框内上方的加权运算(如仿射)的权重和偏差参数学成 0 0 0 ,那么 f ( x ) f(x) f(x) 即为恒等映射。
实际中,当理想映射 f ( x ) f(x) f(x) 极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动。
在残差块中,输入可通过跨层的数据线路更快地向前传播。
网络结构
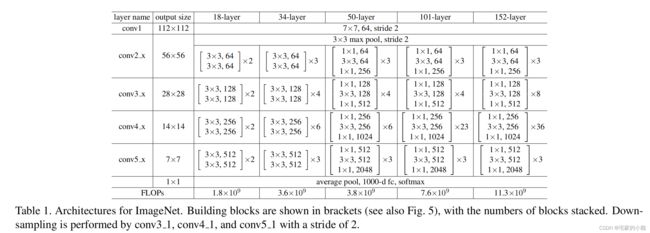
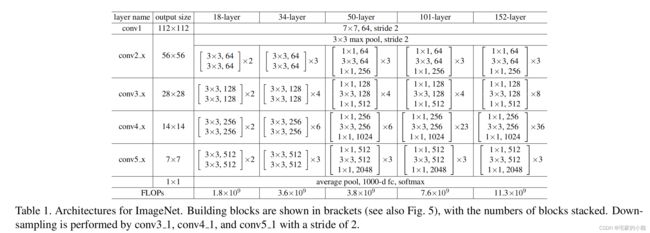
在 ReNet 中,上述的一个残差模块称为 Bottleneck。ResNet 有不同网络层数的版本,如 18 , 34 , 50 , 101 , 152 18,34,50,101,152 18,34,50,101,152 层。
ResNet 沿用了 VGG 全 3 × 3 3×3 3×3 卷积层的设计。残差块里首先有 2 2 2 个有相同输出通道数的 3 × 3 3×3 3×3 卷积层。每个卷积层后接一个批量归一化层和 ReLU 激活函数。然后我们将输入跳过这两个卷积运算后直接加在最后的 ReLU 激活函数前。这样的设计要求两个卷积层的输出与输入形状一样,从而可以相加。如果想改变通道数,就需要引入一个额外的 1 × 1 1×1 1×1 卷积层来将输入变换成需要的形状后再做相加运算。
我们这里以常用的 50 50 50 层来讲解,ResNet-50 的网络架构如图所示,最主要的部分在于中间经历了 4 4 4 个大的卷积组,而这 4 4 4 个卷积组分别包含了 3 , 4 , 6 3,4,6 3,4,6 这 3 3 3 个 Bottleneck 模块。最后经过一个全局平均池化使得特征图大小本为 1 × 1 1\times1 1×1 ,然后进行 1000 1000 1000 维的全连接,最后经过 Softmax 输出分类得分。
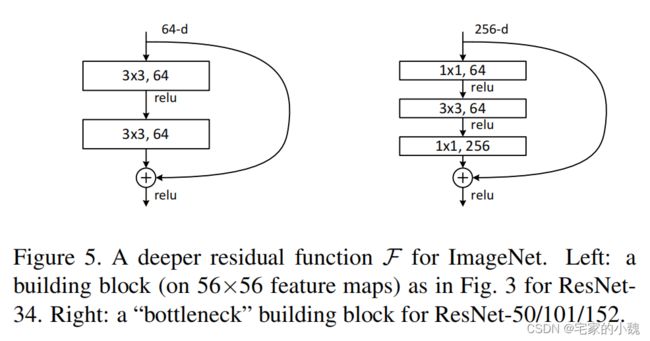
由于 F ( x ) + x F(x)+x F(x)+x 是逐通道进行相加,因此根据两者是否通道数相同,存在两种 Bottleneck 结构。对于通道数不同的情况,比如每个卷积组的第一个 Bottleneck ,需要利用 1 × 1 1\times1 1×1 卷积对 x x x 进行 Down Sample 操作,将通道数变为相同,再进行加操作。对于相同的情况下,而者可以直接进行相加。
总结
ResNet 通过残差块,有效解决了模型的退化问题,使得网络伴随深度加深,仍能保持更好的识别精度。
并且同时通过恒等映射的思想,能够捕捉更为微小的变化。
代码实现
残差块实现
残差块的实现如下。它可以设定输出通道数、是否需要下采样、以及卷积层的步幅。
class Bottleneck(nn.Module):
def __init__(self, in_channels, channels, stride=1, downsample_flag=False, expansion=4):
super(Bottleneck, self).__init__()
self.downsample_flag = downsample_flag
self.expansion = expansion
# 网路堆叠层是由3个卷积+BN组成
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels, channels, 1, stride=1, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU(True),
nn.Conv2d(channels, channels, 3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU(inplace=True),
nn.Conv2d(channels, channels*self.expansion, 1, stride=1, bias=False),
nn.BatchNorm2d(channels * self.expansion)
)
# Down sample由一个包含BN的1*1卷积构成
if self.downsample_flag == True:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, channels*self.expansion, 1, stride, bias=False),
nn.BatchNorm2d(channels*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
output = self.bottleneck(x)
if self.downsample_flag == True:
identity = self.downsample(x)
# 将identity(恒等映射)与堆叠层输出相加
output += identity
output = self.relu(output)
return output
# 实例化Bottleneck,输入64,输出256
bottleneck_1_1 = Bottleneck(64, 64, downsample_flag=True, expansion=4).cuda()
# 测试输入输出
input = torch.randn(1, 64, 256, 256).cuda()
output = bottleneck_1_1(input)
# 通道数变为4倍
output.shape
torch.Size([1, 256, 256, 256])
from torchsummary import summary
# D*W*H
summary(bottleneck_1_1, input_size=(64, 256, 256))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 256, 256] 4,096
BatchNorm2d-2 [-1, 64, 256, 256] 128
ReLU-3 [-1, 64, 256, 256] 0
Conv2d-4 [-1, 64, 256, 256] 36,864
BatchNorm2d-5 [-1, 64, 256, 256] 128
ReLU-6 [-1, 64, 256, 256] 0
Conv2d-7 [-1, 256, 256, 256] 16,384
BatchNorm2d-8 [-1, 256, 256, 256] 512
Conv2d-9 [-1, 256, 256, 256] 16,384
BatchNorm2d-10 [-1, 256, 256, 256] 512
ReLU-11 [-1, 256, 256, 256] 0
================================================================
Total params: 75,008
Trainable params: 75,008
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 16.00
Forward/backward pass size (MB): 832.00
Params size (MB): 0.29
Estimated Total Size (MB): 848.29
----------------------------------------------------------------
网络实现,将残差块和其他块连接起来
ResNet 的前两层跟之前介绍的 GoogLeNet 中的一样:在输出通道数为 64 64 64 、步幅为 2 2 2 的 7 × 7 7×7 7×7 卷积层后接步幅为 2 2 2 的 3 × 3 3×3 3×3 的最大池化层。不同之处在于 ResNet 每个卷积层后增加的批量归一化层。
GoogLeNet 在后面接了 4 4 4 个由 Inception 块组成的模块。ResNet 则使用 4 4 4 个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的最大池化层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这个模块。注意,这里对第一个模块做了特别处理。
接着我们为 ResNet 加入所有残差块。这里每个模块使用两个残差块。
最后,与 GoogLeNet 一样,加入全局平均池化层后接上全连接层输出。
这里每个模块里有 4 4 4 个卷积层(不计算 1 × 1 1×1 1×1 卷积层),加上最开始的卷积层和最后的全连接层,共计 50 50 50 层。这个模型通常也被称为 ResNet-50 。通过配置不同的通道数和模块里的残差块数可以得到不同的 ResNet 模型,例如更深的含 152 152 152 层的 ResNet-152 。虽然 ResNet 的主体架构跟 GoogLeNet 的类似,但 ResNet 结构更简单,修改也更方便。这些因素都导致了 ResNet 迅速被广泛使用。
class ResNet(nn.Module):
def __init__(self, blocks, num_classes=1000, expansion=4):
# blocks为一个[],传递的是每一组res block的个数
super(ResNet, self).__init__()
self.expansion = expansion
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(3, stride=2, padding=1)
)
self.conv2_x = self.make_layer(64, 64, blocks[0], stride=1)
self.conv3_x = self.make_layer(256, 128, blocks[1], stride=2)
self.conv4_x = self.make_layer(512, 256, blocks[2], stride=2)
self.conv5_x = self.make_layer(1024, 512, blocks[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(2048, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 使用正态分布对输入张量的权重进行赋值
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
# 使用1, 0对输入张量的权重和偏置进行赋值
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def make_layer(self, in_channels, channels, block, stride):
# 结构: 1-1续*(block-1) - 2-2续*(block-1) - 3-3续*(block-1) - 4-4续*(block-1)
layers = []
# 1: 64, 64 -> 64-64-256
# 2: 256, 128 -> 256-128-128-512
# 3: 512, 256 -> 512-256-256-1024
# 4: 1024, 512 -> 1024-512-512-2048
layers.append(Bottleneck(in_channels, channels, stride, downsample_flag=True))
for i in range(1, block):
# 1续: 256, 64 -> 256-64-64-256
# 2续: 512, 128 -> 512-128-128-512
# 3续: 1024, 256 -> 1024-256-256-1024
# 4续: 2048, 512 -> 2048-512-512-2048
layers.append(Bottleneck(channels*self.expansion, channels))
# *号用来取列表中的元素,并挨个放入Sequential
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.conv2_x(x)
x = self.conv3_x(x)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
output = self.fc(x)
return output
resnet50 = ResNet([3, 4, 6, 3])
resnet101 = ResNet([3, 4, 23, 3])
resnet152 = ResNet([3, 8, 36, 3])
# 测试输入, batch_size*D*W*H
input = torch.randn(1, 3, 224, 224)
output = resnet50(input)
output.shape
torch.Size([1, 1000])
from torchsummary import summary
# D*W*H
summary(resnet50, input_size=(3, 224, 224), device='cpu')
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 4,096
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 16,384
BatchNorm2d-12 [-1, 256, 56, 56] 512
Conv2d-13 [-1, 256, 56, 56] 16,384
BatchNorm2d-14 [-1, 256, 56, 56] 512
ReLU-15 [-1, 256, 56, 56] 0
Bottleneck-16 [-1, 256, 56, 56] 0
Conv2d-17 [-1, 64, 56, 56] 16,384
BatchNorm2d-18 [-1, 64, 56, 56] 128
ReLU-19 [-1, 64, 56, 56] 0
Conv2d-20 [-1, 64, 56, 56] 36,864
BatchNorm2d-21 [-1, 64, 56, 56] 128
ReLU-22 [-1, 64, 56, 56] 0
Conv2d-23 [-1, 256, 56, 56] 16,384
BatchNorm2d-24 [-1, 256, 56, 56] 512
ReLU-25 [-1, 256, 56, 56] 0
Bottleneck-26 [-1, 256, 56, 56] 0
Conv2d-27 [-1, 64, 56, 56] 16,384
BatchNorm2d-28 [-1, 64, 56, 56] 128
ReLU-29 [-1, 64, 56, 56] 0
Conv2d-30 [-1, 64, 56, 56] 36,864
BatchNorm2d-31 [-1, 64, 56, 56] 128
ReLU-32 [-1, 64, 56, 56] 0
Conv2d-33 [-1, 256, 56, 56] 16,384
BatchNorm2d-34 [-1, 256, 56, 56] 512
ReLU-35 [-1, 256, 56, 56] 0
Bottleneck-36 [-1, 256, 56, 56] 0
Conv2d-37 [-1, 128, 56, 56] 32,768
BatchNorm2d-38 [-1, 128, 56, 56] 256
ReLU-39 [-1, 128, 56, 56] 0
Conv2d-40 [-1, 128, 28, 28] 147,456
BatchNorm2d-41 [-1, 128, 28, 28] 256
ReLU-42 [-1, 128, 28, 28] 0
Conv2d-43 [-1, 512, 28, 28] 65,536
BatchNorm2d-44 [-1, 512, 28, 28] 1,024
Conv2d-45 [-1, 512, 28, 28] 131,072
BatchNorm2d-46 [-1, 512, 28, 28] 1,024
ReLU-47 [-1, 512, 28, 28] 0
Bottleneck-48 [-1, 512, 28, 28] 0
Conv2d-49 [-1, 128, 28, 28] 65,536
BatchNorm2d-50 [-1, 128, 28, 28] 256
ReLU-51 [-1, 128, 28, 28] 0
Conv2d-52 [-1, 128, 28, 28] 147,456
BatchNorm2d-53 [-1, 128, 28, 28] 256
ReLU-54 [-1, 128, 28, 28] 0
Conv2d-55 [-1, 512, 28, 28] 65,536
BatchNorm2d-56 [-1, 512, 28, 28] 1,024
ReLU-57 [-1, 512, 28, 28] 0
Bottleneck-58 [-1, 512, 28, 28] 0
Conv2d-59 [-1, 128, 28, 28] 65,536
BatchNorm2d-60 [-1, 128, 28, 28] 256
ReLU-61 [-1, 128, 28, 28] 0
Conv2d-62 [-1, 128, 28, 28] 147,456
BatchNorm2d-63 [-1, 128, 28, 28] 256
ReLU-64 [-1, 128, 28, 28] 0
Conv2d-65 [-1, 512, 28, 28] 65,536
BatchNorm2d-66 [-1, 512, 28, 28] 1,024
ReLU-67 [-1, 512, 28, 28] 0
Bottleneck-68 [-1, 512, 28, 28] 0
Conv2d-69 [-1, 128, 28, 28] 65,536
BatchNorm2d-70 [-1, 128, 28, 28] 256
ReLU-71 [-1, 128, 28, 28] 0
Conv2d-72 [-1, 128, 28, 28] 147,456
BatchNorm2d-73 [-1, 128, 28, 28] 256
ReLU-74 [-1, 128, 28, 28] 0
Conv2d-75 [-1, 512, 28, 28] 65,536
BatchNorm2d-76 [-1, 512, 28, 28] 1,024
ReLU-77 [-1, 512, 28, 28] 0
Bottleneck-78 [-1, 512, 28, 28] 0
Conv2d-79 [-1, 256, 28, 28] 131,072
BatchNorm2d-80 [-1, 256, 28, 28] 512
ReLU-81 [-1, 256, 28, 28] 0
Conv2d-82 [-1, 256, 14, 14] 589,824
BatchNorm2d-83 [-1, 256, 14, 14] 512
ReLU-84 [-1, 256, 14, 14] 0
Conv2d-85 [-1, 1024, 14, 14] 262,144
BatchNorm2d-86 [-1, 1024, 14, 14] 2,048
Conv2d-87 [-1, 1024, 14, 14] 524,288
BatchNorm2d-88 [-1, 1024, 14, 14] 2,048
ReLU-89 [-1, 1024, 14, 14] 0
Bottleneck-90 [-1, 1024, 14, 14] 0
Conv2d-91 [-1, 256, 14, 14] 262,144
BatchNorm2d-92 [-1, 256, 14, 14] 512
ReLU-93 [-1, 256, 14, 14] 0
Conv2d-94 [-1, 256, 14, 14] 589,824
BatchNorm2d-95 [-1, 256, 14, 14] 512
ReLU-96 [-1, 256, 14, 14] 0
Conv2d-97 [-1, 1024, 14, 14] 262,144
BatchNorm2d-98 [-1, 1024, 14, 14] 2,048
ReLU-99 [-1, 1024, 14, 14] 0
Bottleneck-100 [-1, 1024, 14, 14] 0
Conv2d-101 [-1, 256, 14, 14] 262,144
BatchNorm2d-102 [-1, 256, 14, 14] 512
ReLU-103 [-1, 256, 14, 14] 0
Conv2d-104 [-1, 256, 14, 14] 589,824
BatchNorm2d-105 [-1, 256, 14, 14] 512
ReLU-106 [-1, 256, 14, 14] 0
Conv2d-107 [-1, 1024, 14, 14] 262,144
BatchNorm2d-108 [-1, 1024, 14, 14] 2,048
ReLU-109 [-1, 1024, 14, 14] 0
Bottleneck-110 [-1, 1024, 14, 14] 0
Conv2d-111 [-1, 256, 14, 14] 262,144
BatchNorm2d-112 [-1, 256, 14, 14] 512
ReLU-113 [-1, 256, 14, 14] 0
Conv2d-114 [-1, 256, 14, 14] 589,824
BatchNorm2d-115 [-1, 256, 14, 14] 512
ReLU-116 [-1, 256, 14, 14] 0
Conv2d-117 [-1, 1024, 14, 14] 262,144
BatchNorm2d-118 [-1, 1024, 14, 14] 2,048
ReLU-119 [-1, 1024, 14, 14] 0
Bottleneck-120 [-1, 1024, 14, 14] 0
Conv2d-121 [-1, 256, 14, 14] 262,144
BatchNorm2d-122 [-1, 256, 14, 14] 512
ReLU-123 [-1, 256, 14, 14] 0
Conv2d-124 [-1, 256, 14, 14] 589,824
BatchNorm2d-125 [-1, 256, 14, 14] 512
ReLU-126 [-1, 256, 14, 14] 0
Conv2d-127 [-1, 1024, 14, 14] 262,144
BatchNorm2d-128 [-1, 1024, 14, 14] 2,048
ReLU-129 [-1, 1024, 14, 14] 0
Bottleneck-130 [-1, 1024, 14, 14] 0
Conv2d-131 [-1, 256, 14, 14] 262,144
BatchNorm2d-132 [-1, 256, 14, 14] 512
ReLU-133 [-1, 256, 14, 14] 0
Conv2d-134 [-1, 256, 14, 14] 589,824
BatchNorm2d-135 [-1, 256, 14, 14] 512
ReLU-136 [-1, 256, 14, 14] 0
Conv2d-137 [-1, 1024, 14, 14] 262,144
BatchNorm2d-138 [-1, 1024, 14, 14] 2,048
ReLU-139 [-1, 1024, 14, 14] 0
Bottleneck-140 [-1, 1024, 14, 14] 0
Conv2d-141 [-1, 512, 14, 14] 524,288
BatchNorm2d-142 [-1, 512, 14, 14] 1,024
ReLU-143 [-1, 512, 14, 14] 0
Conv2d-144 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-145 [-1, 512, 7, 7] 1,024
ReLU-146 [-1, 512, 7, 7] 0
Conv2d-147 [-1, 2048, 7, 7] 1,048,576
BatchNorm2d-148 [-1, 2048, 7, 7] 4,096
Conv2d-149 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-150 [-1, 2048, 7, 7] 4,096
ReLU-151 [-1, 2048, 7, 7] 0
Bottleneck-152 [-1, 2048, 7, 7] 0
Conv2d-153 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-154 [-1, 512, 7, 7] 1,024
ReLU-155 [-1, 512, 7, 7] 0
Conv2d-156 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-157 [-1, 512, 7, 7] 1,024
ReLU-158 [-1, 512, 7, 7] 0
Conv2d-159 [-1, 2048, 7, 7] 1,048,576
BatchNorm2d-160 [-1, 2048, 7, 7] 4,096
ReLU-161 [-1, 2048, 7, 7] 0
Bottleneck-162 [-1, 2048, 7, 7] 0
Conv2d-163 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-164 [-1, 512, 7, 7] 1,024
ReLU-165 [-1, 512, 7, 7] 0
Conv2d-166 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-167 [-1, 512, 7, 7] 1,024
ReLU-168 [-1, 512, 7, 7] 0
Conv2d-169 [-1, 2048, 7, 7] 1,048,576
BatchNorm2d-170 [-1, 2048, 7, 7] 4,096
ReLU-171 [-1, 2048, 7, 7] 0
Bottleneck-172 [-1, 2048, 7, 7] 0
AvgPool2d-173 [-1, 2048, 1, 1] 0
Linear-174 [-1, 1000] 2,049,000
================================================================
Total params: 25,557,032
Trainable params: 25,557,032
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 286.56
Params size (MB): 97.49
Estimated Total Size (MB): 384.62
----------------------------------------------------------------
# 输出网络结构
from torchviz import make_dot
x = torch.randn(1, 3, 224, 224).requires_grad_(True)
y = resnet50(x)
myCNN_vis = make_dot(y, params=dict(list(resnet50.named_parameters()) + [('x', x)]))
myCNN_vis