机器学习之回归模型预测性能评估指标(RMSE、MSE、MAE、MAPE、SMAPE、R^2 Score、R^2 )
一、机器学习简介
机器学习就是通过大量的数据进行训练,然后得出输入数据的模型特征;再次输入相关的数据时,能得到一个预测的结果。这在现实生活中解决了大量的问题,如:股票预测、物体分类、房价预测等等,这些都依赖机器学习带给我们的便利。
机器学习中又分为两大类:监督学习和非监督学习。
而监督学习中又分为回归问题和分类问题。
本文章中主要讲回归问题。
二、回归模型的评估指标
假设:
预测值:
![]()
真实值:
![]()
2.1 平均绝对误差 Mean Absolute Error ( MAE )
平均绝对误差 MAE,也叫平均绝对离差;在计算的时候,先对真实值与预测值求和,然后再取平均值。
公式:

范围 [0, +∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
2.2 平均绝对百分误差 Mean Absolute Percentage Error ( MAPE )
平均绝对百分误差是对 MAE 改进后,通过计算真实值与预测的误差百分比避免了数据范围大小的影响。
公式:

范围[0,+∞),MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。
可以看到,MAPE跟MAE很像,就是多了个分母。
注意点:当真实值有数据等于0时,存在分母0除问题,该公式不可用!
2.3 均方误差 Mean Square Error( MSE )
均方误差就是对平均绝对误差求平方根,这个指标在计算时,先对真实值与预测值的距离平方后求和,再取平均值。
公式:

范围[0,+∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
一方面,该指标避免了MAE的绝对值导致函数不能求导的问题,因此均方误差常用于线性回归的损失函数;另一方面,均方误差可以通过平方来放大预测偏差较大的值,提高了检测的灵敏度。
2.4 均方根误差 Root Mean Square Error ( RMSE )
均方根误差(Root Mean Square Error),其实就是MSE加了个根号,这样数量级上比较直观,比如RMSE=10,可以认为回归效果相比真实值平均相差10。
公式:
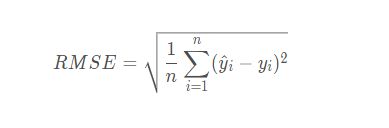
范围[0,+∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
2.5 对称平均绝对百分比误差Symmetric Mean Absolute Percentage Error (SMAPE )
公式:
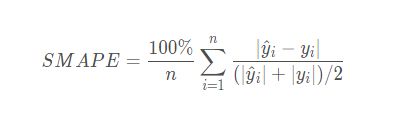
注意点:当真实值有数据等于0,而预测值也等于0时,存在分母0除问题,该公式不可用!
2.6 决定系数 R^2 Score
该指标需要了解另外三个指标:
Sum of Squares of the Regression,SSR
计算预测数据与真实数据均值之差的平方和,反映的是模型数据相对真实数据均值的离散程度。
![]()
Total Sum of Squares,SST
计算真实数据和其均值之差的平方和,反映的是真实数据相对均值的离散程度。

Sum of Squares for Error,SSE
真实数据和预测数据之差的平方和
![]()
细心的小伙伴可能注意到,SST = SSR + SSE
2.7 决定系数 R^2
决定系数 R^2,通过计算SSR 与 SST的比值,反应因变量 y 的全部变异能通过回归模型被自变量 x 解释的比例。比如,R^2 为0.9,则表示回归关系可以解释因变量 90% 的变异。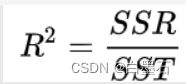
- 决定系数R2越高,越接近于1,模型的拟合效果就越好
- 决定系数R2越接近于0,回归直线拟合效果越差。
R^2 虽然可以评价回归模型效果,但会随着自变量数量的不断增加而改变。
三、python代码
# coding=utf-8
import numpy as np
from sklearn import metrics
# MAPE和SMAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true)) * 100
def smape(y_true, y_pred):
return 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true))) * 100
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.5, 5.0, 8.0, 4.5, 1.0])
# MSE
print(metrics.mean_squared_error(y_true, y_pred)) # 8.107142857142858
# RMSE
print(np.sqrt(metrics.mean_squared_error(y_true, y_pred))) # 2.847304489713536
# MAE
print(metrics.mean_absolute_error(y_true, y_pred)) # 1.9285714285714286
# MAPE
print(mape(y_true, y_pred)) # 76.07142857142858,即76%
# SMAPE
print(smape(y_true, y_pred)) # 57.76942355889724,即58%