Topic 8. 临床预测模型-Lasso回归
Lasso回归在决定哪些因素可以纳入模型提高模型的稳健性,以及相应的给出各种可用图表,在做生物标志物筛选时,效果非常好!
我们从最简单的线性回归(Linear Regression)开始了解如何使用 glmnet 拟合 LASSO 回归模型, 所以此时的连接函数(link function)就是恒等,或者说没有连接函数,而误差的函数分布是正态分布。
01 Lasso 回归概念
——————
用惩罚极大似然拟合广义线性模型。正则化路径是计算在正则化参数lambda值的网格上的套索或弹性网惩罚。可以处理各种形状的数据,包括非常大的稀疏数据矩阵。符合线性、logistic和多项式、泊松和Cox回归模型。
Lasso回归在建立广义线型模型时,响应变量可以包括:
-
一维连续因变量;
-
多维连续因变量;
-
非负次数因变量;
-
二元离散因变量;
-
多元离散因变。
除此之外,无论因变量是连续的还是离散的,lasso都能处理,总的来说,lasso对于数据的要求是极其低的,所以应用程度较广。而lasso的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。
我们可以看到目前基于生信上使用 Lasso 回归找预后生物标志物已经是非常常见的现象,好多文章大都是利用现有的各种模型来构建临床预后的一个结果预测,学会这些以后就不担心自己发不出文章了。

02 实例解析
——————
这里我们使用 R 包 ElemStatLearn 里面的数据,通过对数据的 Lasso 回归建模整个过程来学习分析思路。推荐 R 包 “glmnet”, 非常好用,可以适用于各种广义线性模型的建模。首先安装软件及调取数据,然后看数据类型,找到因变量和自变量,也就是响应变量和预测变量,本章案例是一个前列腺癌数据。虽然这个数据集比较小,只有97个观测共9个变量,但通过与传统技术比较,足以让我们掌握正则化技术。斯坦福大学医疗中心提供了97个病人的前列腺特异性抗原(PSA)数据,这些病人均接受前列腺根治切除术。我们的目标是,通过临床检测提供的数据建立一个预测模型预测患者术后PSA水平。对于患者在手术后能够恢复到什么程度, PSA水平可能是一个较为有效的预后指标。手术之后,医生会在各个时间区间检查患者的PSA水平,并通过各种公式确定患者是否康复。术前预测模型和术后数据(这里没有提供)互相配合,就可能提高前列腺癌诊疗水平,改善其预后。如下所示:
-
lcavol:肿瘤体积的对数值;
-
lweight:前列腺重量的对数值;
-
age:患者年龄(以年计);
-
bph:良性前列腺增生(BPH)量的对数值,非癌症性质的前列腺增生;
-
svi:精囊是否受侵,一个指标变量,表示癌细胞是否已经透过前列腺壁侵入精囊腺(1—是, 0—否);
-
lcp:包膜穿透度的对数值,表示癌细胞扩散到前列腺包膜之外的程度;
-
leason:患者的Gleason评分;由病理学家进行活体检查后给出(2—10) ,表示癌细胞的变异程度—评分越高,程度越危险;
-
pgg45:Gleason评分为4或5所占的百分比;
-
lpsa:PSA值的对数值,响应变量;
-
rain:一个逻辑向量(TRUE或FALSE,用来区分训练数据和测试数据) 。
#install.packages("glmnet")
#install.packages("ElemStatLearn")
#install.packages("leaps")
library(ElemStatLearn) #contains the data
library(car) #package to calculate Variance Inflation Factor
library(corrplot) #correlation plots
library(leaps) #best subsets regression
library(glmnet) #allows ridge regression, LASSO and elastic net
library(caret) #this will help identify the appropriate parameters
data(prostate)
str(prostate)
'data.frame': 97 obs. of 10 variables:
$ lcavol : num -0.58 -0.994 -0.511 -1.204 0.751 ...
$ lweight: num 2.77 3.32 2.69 3.28 3.43 ...
$ age : int 50 58 74 58 62 50 64 58 47 63 ...
$ lbph : num -1.39 -1.39 -1.39 -1.39 -1.39 ...
$ svi : int 0 0 0 0 0 0 0 0 0 0 ...
$ lcp : num -1.39 -1.39 -1.39 -1.39 -1.39 ...
$ gleason: num 0 0 1 0 0 0 0 0 0 0 ...
$ pgg45 : int 0 0 20 0 0 0 0 0 0 0 ...
$ lpsa : num -0.431 -0.163 -0.163 -0.163 0.372 ...
$ train : logi TRUE TRUE TRUE TRUE TRUE TRUE ...
table(prostate$train)
FALSE TRUE
30 67
plot(prostate,col=2,cex=0.5,pch=20)
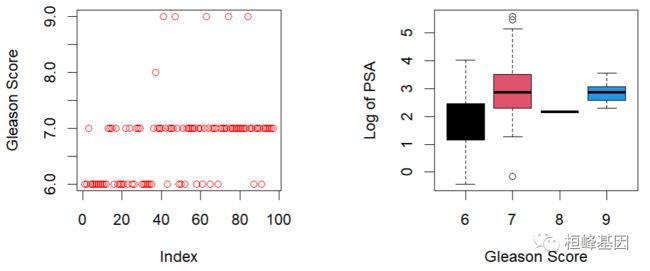
plot(prostate$gleason, ylab = "Gleason Score")
table(prostate$gleason)
6 7 8 9
35 56 1 5
boxplot(prostate$lpsa ~ prostate$gleason, xlab = "Gleason Score",
ylab = "Log of PSA")
prostate$gleason <- ifelse(prostate$gleason == 6, 0, 1)
table(prostate$gleason)
0 1
35 62
boxplot(prostate$lpsa ~ prostate$gleason, xlab = "Gleason Score",
p.cor = cor(prostate)
corrplot.mixed(p.cor)
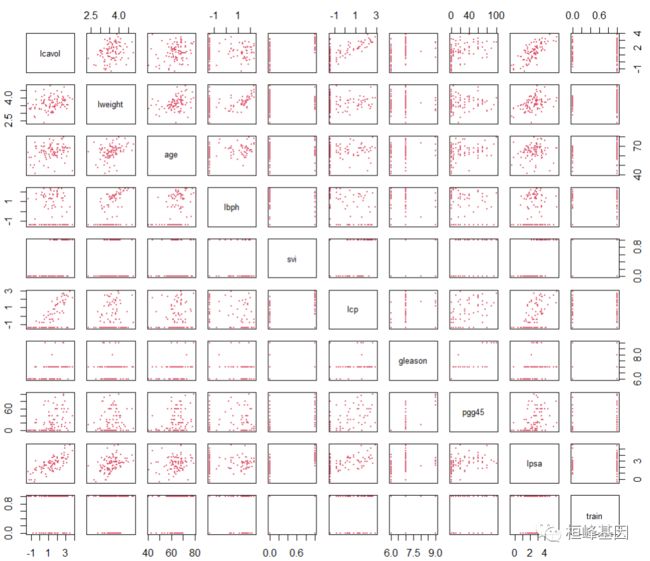
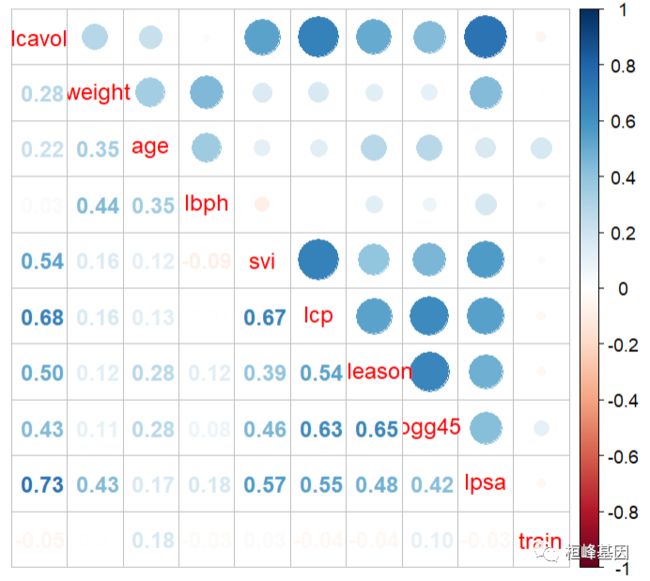
从上面可以看到 train那列是可以分层训练集和测试集,那么我们把数据分开,模型建立之后就可以对其进行测试,这个数据模式想的非常周到,下面我们就将数据切割,发现是7:3的方式切割数据,如下:
train <- subset(prostate, train == TRUE)[, 1:9]
str(train)
test = subset(prostate, train==FALSE)[,1:9]
str(test)
构造 glmnet 读取所需要的格式文件,x 为一个数值矩阵,y 为一个响应变量,这里的 y 为连续型自变量,并建模和交叉验证 (cv.glmnet),如下:
x <- as.matrix(train[, 1:8])
y <- train[, 9]
lasso <- glmnet(x, y, family = "gaussian", alpha = 1)
print(lasso)
Call: glmnet(x = x, y = y, family = "gaussian", alpha = 1)
Df %Dev Lambda
1 0 0.00 0.88400
2 2 4.39 0.80540
3 2 8.71 0.73390
4 2 12.30 0.66870
5 2 15.28 0.60930
6 2 17.75 0.55520
7 2 19.81 0.50580
8 2 21.52 0.46090
9 2 22.93 0.42000
10 3 24.11 0.38260
11 4 25.16 0.34870
12 4 26.04 0.31770
13 4 26.77 0.28950
14 4 27.37 0.26370
15 4 27.88 0.24030
16 4 28.29 0.21900
17 4 28.64 0.19950
18 4 28.92 0.18180
19 4 29.16 0.16560
20 4 29.36 0.15090
21 4 29.52 0.13750
22 4 29.66 0.12530
23 4 29.77 0.11420
24 4 29.87 0.10400
25 4 29.95 0.09478
26 4 30.01 0.08636
27 4 30.07 0.07869
28 4 30.11 0.07170
29 4 30.15 0.06533
30 5 30.33 0.05953
31 5 30.50 0.05424
32 6 30.65 0.04942
33 6 30.78 0.04503
34 6 30.89 0.04103
35 6 30.98 0.03738
36 6 31.06 0.03406
37 6 31.12 0.03104
38 7 31.17 0.02828
39 7 31.24 0.02577
40 7 31.30 0.02348
41 7 31.35 0.02139
42 7 31.39 0.01949
43 8 31.44 0.01776
44 8 31.51 0.01618
45 8 31.56 0.01475
46 8 31.61 0.01344
47 8 31.64 0.01224
48 8 31.67 0.01115
49 8 31.70 0.01016
50 8 31.72 0.00926
51 8 31.74 0.00844
52 8 31.75 0.00769
53 8 31.76 0.00700
54 8 31.77 0.00638
55 8 31.78 0.00582
56 8 31.79 0.00530
57 8 31.80 0.00483
58 8 31.80 0.00440
59 8 31.80 0.00401
60 8 31.81 0.00365
61 8 31.81 0.00333
62 8 31.81 0.00303
63 8 31.81 0.00276
64 8 31.82 0.00252
65 8 31.82 0.00229
66 8 31.82 0.00209
67 8 31.82 0.00190
68 8 31.82 0.00174
69 8 31.82 0.00158
70 8 31.82 0.00144
71 8 31.82 0.00131
72 8 31.82 0.00120
73 8 31.82 0.00109
par(mfrow=c(1,2))
plot(lasso, xvar = "lambda", label = TRUE)
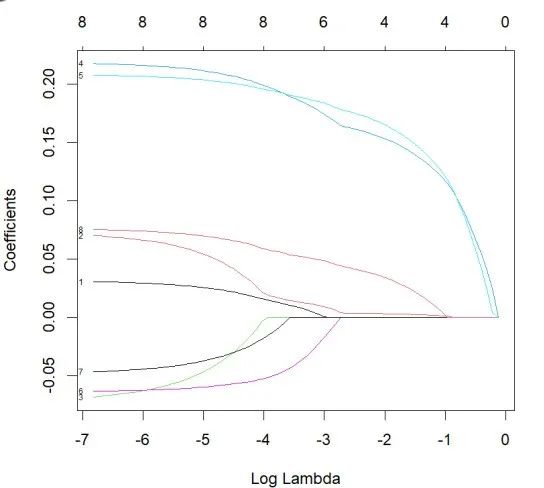
利用上述模型进行对测试集进行预测,如下:
lasso.coef <- predict(lasso, s = 0.045, type = "coefficients")
lasso.coef
9 x 1 sparse Matrix of class "dgCMatrix"
s1
(Intercept) -0.1305900670
lcavol 0.4479592050
lweight 0.5910476764
age -0.0073162861
lbph 0.0974103575
svi 0.4746790830
lcp .
gleason 0.2968768129
pgg45 0.0009788059
lasso.y <- predict(lasso, newx = newx,
type = "response", s = 0.045)
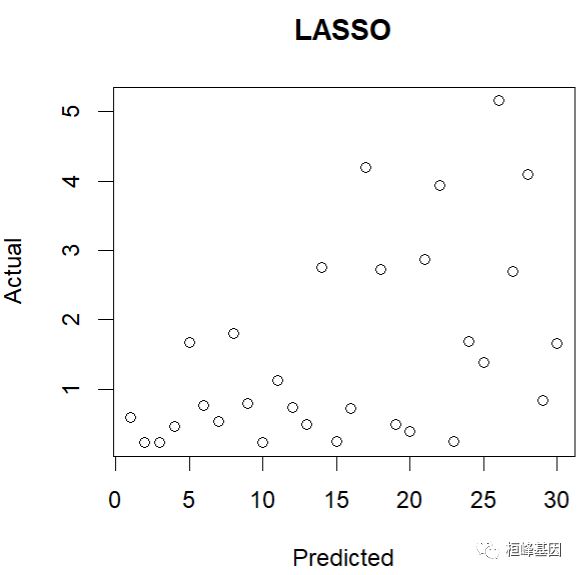
plot(lasso.y, test$lpsa, xlab = "Predicted", ylab = "Actual",
main = "LASSO")
lasso.resid <- lasso.y - test$lpsa
mean(lasso.resid^2)
[1] NaN
03 结果解析
——————
我们从图上可以看出,在有三个参数在随着 alpha 值的变化趋向于 0,在线性回归中系数趋于 0 就等同于没有对相应变量没有影响,也就是无意义,所以个根据结果给出我们选择六个参数时的 alpha 值时0.045,这时 age, lcp, pgg45 都可去掉,这样才能达到模型的最优化。
lasso.coef
9 x 1 sparse Matrix of class "dgCMatrix"
s1
(Intercept) -0.1305900670
lcavol 0.4479592050
lweight 0.5910476764
age -0.0073162861
lbph 0.0974103575
svi 0.4746790830
lcp .
gleason 0.2968768129
pgg45 0.0009788059
04 交叉验证
——————
我们将对上述模型进行交叉验证,大概说一下交叉验证的概念:
交叉验证(Cross-validation)主要用于建模应用中,例如 PCR、PLS 回归建模中。在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。如下:
set.seed(317)
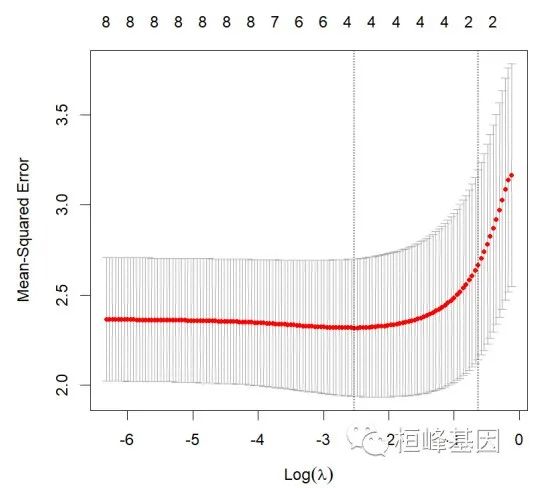
lasso.cv = cv.glmnet(x=x, y=y, nlambda = 200,alpha = 1)
plot(lasso.cv)
lasso.cv$lambda.min #minimum
lasso.cv$lambda.1se #one standard error away
coef(lasso.cv, s = "lambda.1se")
lasso.y.cv = predict(lasso.cv, newx=newx, type = "response",
s = "lambda.1se")
lasso.cv.resid = lasso.y.cv - test$lpsa
mean(lasso.cv.resid^2)
这期 Lasso 回归模型学会了,一篇 SCI 文章基本不愁,一定要来学习,祝您发高分!
Reference:
-
Friedman, J., Hastie, T. and Tibshirani, R. (2008) Regularization Paths for Generalized Linear Models via Coordinate Descent (2010), Journal of Statistical Software, Vol. 33(1), 1-22,
-
Simon, N., Friedman, J., Hastie, T. and Tibshirani, R. (2011) Regularization Paths for Cox’s Proportional Hazards Model via Coordinate Descent, Journal of Statistical Software, Vol. 39(5), 1-13.
-
Tibshirani, Robert, Bien, J., Friedman, J., Hastie, T.,Simon, N.,Taylor, J. and Tibshirani, Ryan. (2012) Strong Rules for Discarding Predictors in Lasso-type Problems, JRSSB, Vol. 74(2), 245-266.
-
Hastie, T., Tibshirani, Robert and Tibshirani, Ryan. Extended Comparisons of Best Subset Selection, Forward Stepwise Selection, and the Lasso (2017), Stanford Statistics Technical Report.
-
Huang R, Mao M, Lu Y, Yu Q, Liao L. A novel immune-related genes prognosis biomarker for melanoma: associated with tumor microenvironment. Aging (Albany NY). 2020;12(8):6966-6980. doi:10.18632/aging.103054
-
Chen H, Kong Y, Yao Q, et al. Three hypomethylated genes were associated with poor overall survival in pancreatic cancer patients. Aging (Albany NY). 2019;11(3):885-897. doi:10.18632/aging.101785

桓峰基因
生物信息分析,SCI文章撰写及生物信息基础知识学习:R语言学习,perl基础编程,linux系统命令,Python遇见更好的你
29篇原创内容
公众号