Python MINIST手写集的识别,卷积神经网络,CNN(最简单PyTorch的使用)
文章目录
- 网络结构
- 输出图像尺寸
- 网络代码
- 预处理代码
- 训练代码
- 结果评定
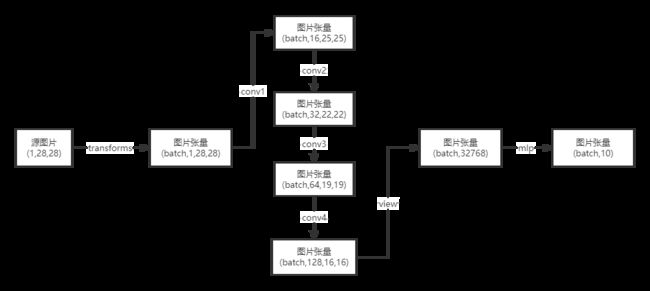
网络结构

按顺序对每个层的参数设置
Conv1
Conv2d:in_channels=1, out_channels=16, kernel_size=3, stride=1
BatchNorm2d:16
ReLU
MaxPool2d:kernel_size=2, stride=1
Conv2
Conv2d:in_channels=16, out_channels=32, kernel_size=3, stride=1
BatchNorm2d:32
ReLU
MaxPool2d:kernel_size=2, stride=1
Conv3
Conv2d:in_channels=32, out_channels=64, kernel_size=3, stride=1
BatchNorm2d:64
ReLU
AvgPool2d:kernel_size=2, stride=1
Conv4
Conv2d:in_channels=64, out_channels=128, kernel_size=3, stride=1
BatchNorm2d:128
ReLU
AvgPool2d:kernel_size=2, stride=1
MLP
Linear(128 * 16 * 16, 1000)
Linear(1000, 1000)
Linear(1000, 100)
Linear(100, 10)
输出图像尺寸
计算公式(lambda函数化)
func = lambda size, kernel=3, stride=1, padding=0: ((size - kernel + 2 * padding) / stride + 1)
代码通过显式获取图片长宽,并且结合网络层的构造可以自动计算图像尺寸的变换
func = lambda size, kernel=3, stride=1, padding=0: ((size - kernel + 2 * padding) / stride + 1)
x = func(func(self.options[1]), kernel=2)
x = func(func(x), kernel=2)
x = func(func(x), kernel=2)
x = func(func(x), kernel=2)
y = func(func(self.options[2]), kernel=2)
y = func(func(y), kernel=2)
y = func(func(y), kernel=2)
y = func(func(y), kernel=2)
x = int(x)
y = int(y)
网络代码
class CNN(nn.Module):
def __init__(self, channels, width, height, classes, device='cpu'):
super().__init__()
self.options = [channels, width, height, classes, device]
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=16, kernel_size=3, stride=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1)
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=1)
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=1)
)
func = lambda size, kernel=3, stride=1, padding=0: ((size - kernel + 2 * padding) / stride + 1)
x = func(func(self.options[1]), kernel=2)
x = func(func(x), kernel=2)
x = func(func(x), kernel=2)
x = func(func(x), kernel=2)
y = func(func(self.options[2]), kernel=2)
y = func(func(y), kernel=2)
y = func(func(y), kernel=2)
y = func(func(y), kernel=2)
x = int(x)
y = int(y)
self.mlp = nn.Sequential(
nn.Linear(128 * x * y, 1000),
nn.Linear(1000, 1000),
nn.Linear(1000, 100),
nn.Linear(100, self.options[3])
)
self = self.to(self.options[4])
def forward(self, data):
data = data.to(self.options[4]) # 将向量转移到设备上
data = self.conv1(data)
data = self.conv2(data)
data = self.conv3(data)
data = self.conv4(data)
data = data.view(data.size(0), -1)
data = self.mlp(data)
return data
预处理代码
data_tf = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5], [0.5])
]
)
data_path = r'data/minist' # minist数据集的下载路径
# 获取数据集
train_data = mnist.MNIST(data_path, train=True, transform=data_tf, download=False)
test_data = mnist.MNIST(data_path, train=False, transform=data_tf, download=False)
train_loader = data.DataLoader(train_data, batch_size=128, shuffle=True)
test_loader = data.DataLoader(test_data, batch_size=128, shuffle=True)
训练代码
device = 'cuda:0'
model = CNN(channels=1, width=28, height=28, classes=10, device=device)
loss_func = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=0.001)
loss_count = []
for epoch in range(50):
for i, (x, y) in enumerate(train_loader):
batch_x = Variable(x)
batch_y = Variable(y).to(device)
out = model(batch_x)
loss = loss_func(out, batch_y)
opt.zero_grad()
loss.backward()
opt.step()
if i % 20 == 0:
loss = loss.cpu()
loss_count.append(loss)
for a, b in test_loader:
test_x = Variable(a)
test_y = Variable(b).to(device)
out = model(test_x)
test_y = test_y.cpu()
out = out.cpu()
accuracy = max(out, 1)[1].numpy() == test_y.numpy()
print('accuracy:\t', accuracy.mean())
break
datas = []
for i in loss_count:
if i.data < 0.5:
datas.append(i.data)
plt.figure('LOSS')
plt.plot(datas, label='Loss')
plt.legend()
plt.show()
因为交叉熵损失会出现大于1的值,所以显示的时候删除掉损失大于0.5的值,会更好的显示损失图
结果评定

