第四周作业:卷积神经网络(Part2)
目录
现代卷积神经网络
AlexNet
NiN(network in network)
VGG
GoogLeNet
批量归一化(BatchNorm)
残差网络ResNet
使用Resnet进行迁移学习——猫狗大战
结果展示
具体内容分析
感想与问题
现代卷积神经网络
上周学习了第一个卷积神经网络LeNet,了解了卷积网络的基本计算方法和一些模块,例如卷积核,池化等等。本周学习了LeNet之后产生的更新的卷积神经网络。
AlexNet
第一个现代卷积网络是AlexNet,也正是AlexNet在ImageNet竞赛上的成功,使得卷积神经网络以及深度学习开始风靡,引发了这一轮的深度学习热潮。AlexNet的基本模式同LeNet相同,其成功的关键原因有两个,一是网络时代大量增加的数据,二是GPU提供的算力支持了大型网络的训练。在LeNet的时代,网络尚未完全普及,在图像领域的机器学习研究通常使用小样本,而且样本的维度也不大。在这样的情况下,神经网络并不比传统的机器学习方法更有优势,而且神经网络的训练和调参难度也比传统机器学习方法大,因此神经网络没有获得多少青睐。而后来互联网的普及使得数据集的规模有了增大的可能,而gpu的使用,使得训练更大更深的神经网络更加容易。在这两个条件的基础上,AlexNet取得了成功。
AlexNet的基本结构如下:

AlexNet在提出时使用了多GPU拆分网络训练的方式,因为当时GPU的显存仍然不够大,现在我们的硬件条件已经不需要将网络拆分训练了。利用pytorch进行AlexNet网络的构建也十分容易,由于AlexNet也是这种串联的网络结构,我们可以直接使用nn.Sequential构建网络。
以下代码来自李沐《动手学深度学习》
import torch
import torch.nn as nn
AlexNet = nn.Sequential(
nn.Conv2d(1,96,kernel_size=11,stride=4,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(96,256,kerne_size=5,padding=2),
nn.Relu(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(256,384,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(384,384,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(384,256,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Faltten(),
nn.Linear(6400,4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,4096),
nn.Dropout(p=0.5),
nn.Linear(4096,10)
)值得注意的是,AlexNet没有用sigmoid函数作为激活函数,而是采用了ReLU函数作为激活函数。相较于sigmoid,ReLU函数拥有更简单的导数,而且也不容易梯度弥散。后面的神经网络基本都采用Relu作为激活函数。我们查看一下网络每一层输出的形状
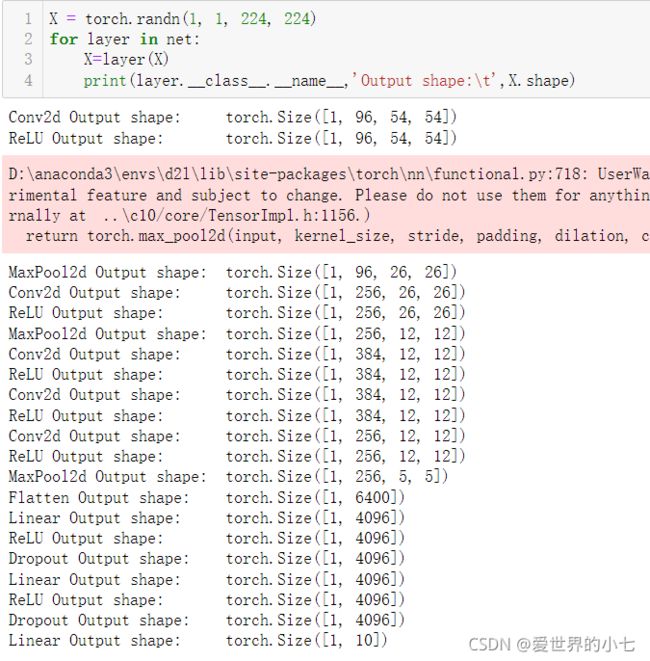
接下来我们使用d2l库定义好的数据处理和训练的函数,对AlexNet进行训练。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
NiN(network in network)
接下来一个网络是NiN,其最重要的创新,是提出了1*1卷积,即对特征图的每个像素点上,应用全连接网络,将每个像素点上所有通道的特征进行计算。由于1*1卷积不改变特征图的尺寸,只调整特征图的通道,可以灵活的调整网络结构,降低计算复杂度,因此这种卷积被后来的网络结构广泛采用。
VGG
下一个学习的网络结构是有名的VGG Net。其创新点在于提出了卷积块的概念,将若干个卷积层以及激活函数打包成一个块,通过多个块的堆叠构造神经网络,方便了网络结构的设计,并且也取得了很好的效果。其另一个发现是多个3*3的卷积堆叠,效果要好于使用大尺寸的卷积,例如7*7,11*11,即使用窄且深的网络比宽且浅的网络好。
一个vgg块包含若干个卷积和ReLU,每个块的第一个卷积会将输入的通道进行改变(或不改变),后续的所有卷积都采用尺寸为3,步长为1,padding为1的卷积,输入的通道和输出的通道数一致,因此在一个vgg块内部,特征图的尺寸不会发生变化,直到块的末尾。
按照vgg的思路,我们构建一个小规模的vgg用来进行fashin_mnist分类。
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
ratio = 4
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())训练结果如下
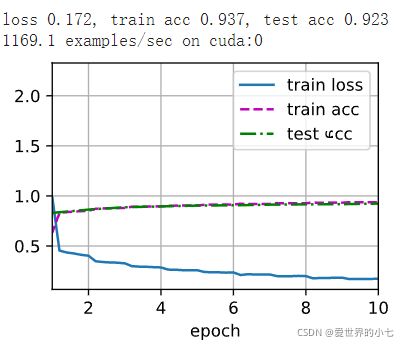
可以看到vgg的效果好于AlexNet。
GoogLeNet
随着卷积神经网络的流行,各种尺寸的卷积都在应用,那么什么时候用多大尺寸的卷积更合适呢?GoogLeNet给了我们答案——小孩子才做选择。GoogLeNet提出了Inception块,即把多个尺寸的卷积核并联,同一个输入同时经过多条路径,产生不同的特征,之后将所有特征在通道的维度凭借起来。
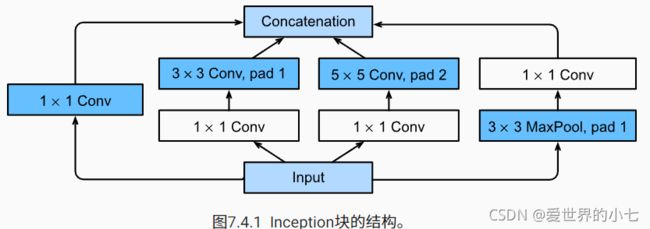
当然这样做的代价就是,计算的开销变得巨大,因此我们可以得出结论—— 世上没有免费的午餐(有钱真好)
整个GoogLeNet的框架如图:

模型定义代码和训练结果如下:
class Inception(nn.Module):
# `c1`--`c4` 是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大汇聚层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

批量归一化(BatchNorm)
批量归一化是一个十分有效的方法,可以稳定模型的训练,提升模型的表现。其基本思想是对网络每一层的输入都进行归一化,使网络的输入总是基本符合正态分布,保证网络能够稳定的训练。具体的计算方法是,对每一个特征(对于全连接网络来说就是每个神经元的输出,对于卷积神经网络来说就是特征图的每个通道),在batch的维度上进行归一化。

每个特征通过减去均值除以标准差的方式,被调整到正态分布。同时为了控制这种分布移动,BatchNorm还有两个可学习参数,γ和β。那么在理想情况下,如果分布被调整之后不合适,这两个可学习参数会反方向对特征进行变换,抵消归一化。γ会初始化为1,β会初始化为0。
值得注意的是,如果batchsize为1,那么对全连接网络进行batchnorm会使所有的特征变成随机数。因为batchsize为1时,每个神经元的输出的特征均值即为自身,归一化会使其成为0,最后的值就是可学习参数β,但是β初始化为0,而且也没法获得网络的特征,因此相当于我们将神经网络的特征完全随机了。如果时卷积神经网络,那么batchsize为1是就是对每个特征图的每个通道进行了归一化。
残差网络ResNet
如果AlexNet让深度学习风靡,那么ResNet带来了真正的深度。残差连接思想的提出使得我们训练极深的网络成为了可能,残差连接几乎成为了现在深度学习不可缺少的技术。
残差链接使得网络层数的加深和复杂可以包含原有的网络,即模型的效果最坏不会坏于加深之前的效果。具体的计算方式是,每次将输入直接与输出相加,使得网络变成x+f(x)的形式,这样网络最差也是恒等映射,y=x,不会让效果变得更差。更重要的是,残差连接使得梯度可以通过“捷径”从深处传递到前面,缓解了梯度弥散的问题,使得深层的网络更容易训练。

由于需要把输入和输出相加,因此残差块的输入和输出特征必须要有同样的尺寸,即通道数和长宽都必须要一致。因此残差块内部使用尺寸为3*3,stride为1,padding为1的卷积保证尺寸不变化,同时用1*1的卷积来调整通道数,保证输入和输出的通道数一致。
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)这里要注意,首先我们传入的参数中第一个是输入特征的通道数,第二个参数是输出特征的通道数,第三是是否使用1*1卷积,第四是步长。如果输入和输出的通道数不同,那么必须要将使用1*1卷积设置为True,否则输入和输出的通道不同无法相加。如果步长不为1,那么使用1*1卷积也必须同时设置为True,否则输入和输出的特征长宽尺度不同,无法相加。
接下来构建ResNet
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
ResNet由若干模块组成,每个模块由若干残差块组成,第一个模块使用最大池化降采样,第三个模块及之后都采用卷积的操作进行降采样,使尺寸减半同时通道加倍。训练效果如下
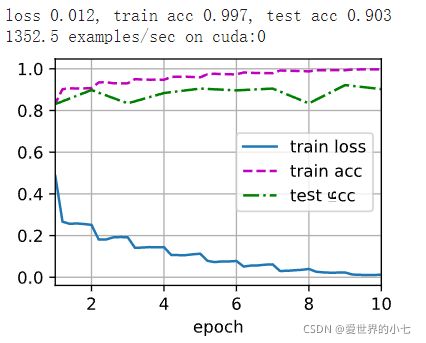
使用Resnet进行迁移学习——猫狗大战
结果展示
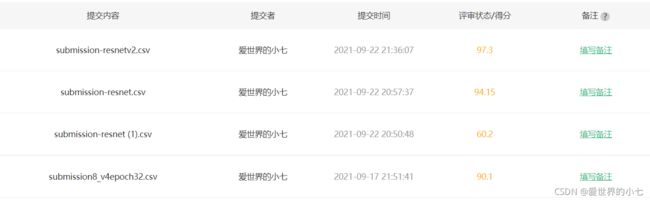
目前最好的成绩是97.3(测试集正确率97.3%)。
具体内容分析
迁移学习是指将模型在目标数据集之外的数据集上进行与训练,再将预训练好的模型在目标数据集上训练。可以看作一种更有效的模型初始化方法,相较于随机初始化。一般来讲,预训练的数据集要远大于目标数据集,并且二者尽可能类似。
卷积神经网络在更大的数据集上预训练后,已经可以提取一些通用的模式,例如边缘等一些基础的纹理
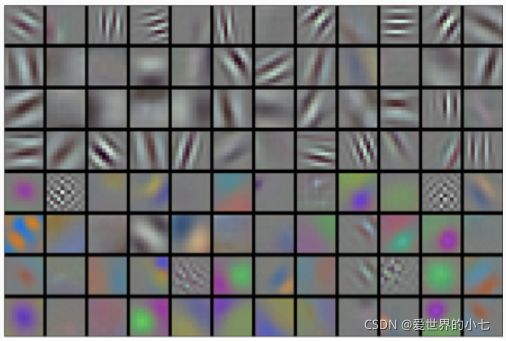
在此基础上,我们在目标数据集上再进行训练就可以更快的获得好的效果。
我们使用在ImageNet上预训练的ResNet18做迁移学习,数据处理的代码复用了上一次的。这里我们只分析与上次不同的部分。
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])数据增强的代码采用了李沐《动手学深度学习》中的部分。
ResNet在ImageNet上进行了预训练,因此我们也将自己的数据集进行与ImageNet一样的预处理。主要包括调整尺寸以及归一化。
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
params_1x = [param for name, param in finetune_net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD([{'params': params_1x},
{'params': finetune_net.fc.parameters(),'lr': 5e-5 * 10}],
lr=5e-5, weight_decay=0.001)这里我们采用李沐《动手学深度学习》中的写法,我们将ResNet最后一层的全连接层换掉,使其输出2类的分类结果。动手学深度学习中的代码采用了差异训练的思想,即对卷积部分采用小学习率,对更换的全连接层采用较大的学习率。原因在于,卷积网络的部分经过预训练已经可以很好的提取特征,我们给其小学习率使其进行微小的调整即可,而更换的全连接层是随机初始化的,我们给其较大的学习率进行学习。
我们按照这种方式,在训练集上训练5个epoch

可以看到最开始,模型的正确率就已经很高,训练五个epoch之后就可以有90%以上的正确率。
将这个模型的预测结果提交网站,得到的结果却是60.2。经过检查之后,我发现原因在于没有在测试时将batchnorm设为测试模式。我们需要使用net.eval()将batchnorm设置为测试模式。修改之后再次提交,得到了94.15的成绩。可以看到迁移学习的效率是非常高的,我们只训练了5个epoch就超过了上一次我们的结果。
之后我采取了另一种训练测率,冻结卷积层的参数,只训练最后的分类器,同样训练5个epoch
finetune_net = torchvision.models.resnet18(pretrained=True)
for param in finetune_net.parameters():
param.require_grad=False
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)
for param in finetune_net.fc.parameters():
param.require_grad=True要注意,我们在更换最后的分类器之前就要冻结所有参数,方法就是把所有参数的require_grad设置为False,之后我们更换分类器,如果先更换了分类器再将参数冻结,那么网络就无法训练。
训练结果如下

可以看到,效果比全部都训练要好。原因在于我们的数据集和预训练的数据集是很类似的,ImageNet中原本就包含猫和狗。如果我们的数据集和预训练的数据集差异较大,那我们采用全部训练的方式会更有效(动手学深度学习中的代码是用迁移学习做热狗分类,因此采用了全部训练的策略)。
我们将这次的模型预测结果提交,得到了97.3的成绩。
感想与问题
深度学习的有效离不开大量数据的支持,而迁移学习使得我们可以利用数据红利在小的目标数据集上应用深度学习。在庞大的数据集上预训练基础模型,再在下游任务中进行微调已经是一个大趋势。
batchnorm的有效性仍有解释上的争议,其有效性的具体原因仍然没有定论。
代码能力还应加强,细心程度还要提高。