【Kaggle项目实战记录】一个图片分类项目的步骤和思路分享——以树叶分类为例(用Pytorch)
文章目录
-
- 1 查看原数据
- 2 数据预处理,建立Dataset
-
- 创建数据集Dataset对象
- 预览训练集和验证集
- 3 定义模型、优化器
- 4 设置训练集和测试集
- 5 训练
-
- 设定数据增广方法
- 训练
- 6 保存模型
- 7 验证数据,上传
-
- 预测
- 上传
- 简单的技术点总结
这是一个动手学深度学习中的一个练习项目(树叶分类),通过这个项目,可以学习到从数据预处理、建立数据集、数据增强到模型训练等深度学习项目各个方面的从零开始的经验。
本文就记录一下自己完成这个项目的步骤和思考。用到的都是最基本的技术,初学者都会。
1 查看原数据
先浏览一下原数据长什么样子。
把数据集解压后发现下面一个子文件夹image里存放了共27153张图片,其中标号前18353张图片为训练集,后8800张图片为测试集(测试集没有给label)。
训练集的标签信息在train.csv中,有176类。

 项目的目的是预测后面8800张树叶图片的分类。
项目的目的是预测后面8800张树叶图片的分类。
我们发现图片的信息和label信息没有直接对应起来,最好是一个图片张量对应一个label类才行。
所以这样的数据集需要处理一下才能读入Dataset类中,并且我们最好自己写一个Dataset类。
2 数据预处理,建立Dataset
先导包
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision.datasets import ImageFolder
from torchvision import transforms
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
然后第一个目的是准备建立自己的数据集Dataset类。
我想先使用torchvision.datasets.ImageFolder()方法把image下的图片读入一个临时的Dataset,这样图片数据集就会有现成的了,之后改一下里面的标签即可。这样就可以利用这个临时Dataset做文章建立自己Dataset类。
用ImageFolder读文件会有一个坑,即它会按文件名的字符串排序的顺序读进来(即 1.jpg → 10.jpg → 11.jpg … → 2.jpg …),所以我们先把image文件夹下的文件名重新处理一下。
# 先给文件名称重命名一下,数字不满5位的一律补全0,因为届时用ImageFolder读取是按字符串顺序读取的
# 即 3.jpg → 00003.jpg
import os
path = '../classify-leaves/images'
file_list = os.listdir(path)
for file in file_list:
front, end = file.split('.') # 取得文件名和后缀
front = front.zfill(5) # 文件名补0,5表示补0后名字共5位
new_name = '.'.join([front, end])
# print(new_name)
os.rename(path + '\\' + file, path + '\\' + new_name)
之后就可以读入整个图片数据集了。
# 读取整个临时数据集
data_images = ImageFolder(root='../classify-leaves')
要建立自己的数据集,先需要区分训练集和验证集。
接下来先读取训练集和label:
train_csv = pd.read_csv('../classify-leaves/train.csv')
print(len(train_csv))
train_csv
# 显示:

然后需要把label中的类名转换为类别号,以方便届时读入Dataset:
# 获取某个元素的索引的方法
# 这个class_to_num即作为类别号到类别名称的映射
class_to_num = train_csv.label.unique()
print(np.where(class_to_num == 'quercus_montana')[0][0])
# 将训练集的label对应成类别号
train_csv['class_num'] = train_csv['label'].apply(lambda x: np.where(class_to_num == x)[0][0])
train_csv
# 显示:

创建数据集Dataset对象
有了整个图片数据集的信息,又有了训练集的长度和label信息,我们可以构建自己的Dataset了(定制Dataset的方法可参考我这篇文章)。
我打算在这个Dataset中根据需要给出训练集或验证集,另外可以传入数据增强的transform方法。
我把Dataset设计成可以直接传入一整个数据集对象imgs(由之前的ImageFolder方法得到),和其中训练集的标签labels,这样imgs的长度会大于labels,多出来的部分就是验证集,为方便起见,验证集的label自动设为-1。
# 创建数据集对象 —— leaf_dataset
class leaf_dataset(Dataset): # 需要继承Dataset类
def __init__(self, imgs, labels, train=True, transform=None):
"""
传入数据集imgs、标签labels。
imgs多于labels长度的数据自动作为验证集,自动设为“-1”类
Args:
imgs (Dataset): 传入整个图片数据集,由ImageFolder读取
labels (pandas: series): 训练集的标签
train (True or False):是否载入训练集,False则载入验证集
transform:传入transform方法, 不设置则默认为 Resize((224, 224)) + ToTensor()
"""
to_train = len(labels)
to_valid = len(imgs)
if len(imgs) > len(labels): # labels是训练集标签,通常会小于imgs的大小,所以补上验证集的标签
indices1 = range(to_train)
imgs_to_train = torch.utils.data.Subset(imgs, indices1)
indices2 = range(to_train, to_valid)
imgs_to_valid = torch.utils.data.Subset(imgs, indices2)
labels_valid = pd.Series([-1]*(len(imgs) - len(labels))) # 为验证集标上-1类,与训练集样式统一
if train == True:
self.imgs = imgs_to_train
self.labels = labels
else:
self.imgs = imgs_to_valid
self.labels = labels_valid
else: # labels和imgs等长时没有验证集的问题(若imgs长度小于labels,届时Dataloader会抛弃多出来的labels部分)
self.imgs = imgs
self.labels = labels
if transform:
self.transform = transform
else:
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
]) # 如果没设定transform,采取默认的转换操作
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
label = self.labels[idx]
data_in = self.imgs[idx][0] # 届时传入一个ImageFolder对象,需要取[0]获取数据,不要标签
data = self.transform(data_in)
return data, label
预览训练集和验证集
设计完Dataset后,之前ImageFolder读到的临时数据集就是我们的imgs,训练集的标签号则是我们的labels。
imgs = data_images # 总数据集
labels = train_csv.class_num # 训练集标签
print(len(imgs), len(labels))
# 序列不等长,超过labels长度部分作为验证集
得到我们的Leaf_dataset后,可以预览一下效果:
Leaf_dataset_train = leaf_dataset(imgs=imgs, labels=labels, train=True)
print(len(Leaf_dataset_train))
# 传入DataLoader看一下
train_iter = DataLoader(dataset=Leaf_dataset_train, batch_size=128, shuffle=False)
X, y = next(iter(train_iter))
print(X[0].shape, y[0])
# 定义绘图函数 show_images
def show_images(imgs, num_rows, num_cols, scale=2):
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
for i in range(num_rows):
for j in range(num_cols):
axes[i][j].imshow(imgs[i * num_cols + j])
axes[i][j].axes.get_xaxis().set_visible(False)
axes[i][j].axes.get_yaxis().set_visible(False)
return axes
# 展示一下
toshow = [torch.transpose(X[i],0,2) for i in range(16)]
show_images(toshow, 2, 8, scale=2)

看看验证集,这边的valid_iter届时验证并上传时还会用到。
Leaf_dataset_valid = leaf_dataset(imgs=imgs, labels=labels, train=False)
print(len(Leaf_dataset_valid))
# 传入DataLoader看一下
valid_iter = DataLoader(dataset=Leaf_dataset_valid, batch_size=128, shuffle=False)
X, y = next(iter(valid_iter))
print(X[0].shape, y[0])
# 展示一下
toshow = [torch.transpose(X[i],0,2) for i in range(16)]
show_images(toshow, 2, 8, scale=2)

3 定义模型、优化器
我使用常用的Resnet34模型,使用预训练。
直接使用torchvision.models中的模型即可。
需要把模型的最后的输出层的数目改成我们的类别数 len(class_to_num),即176类。
from torchvision import models
pretrained_net = models.resnet34(pretrained=True)
# 使用的torchvision的resnet34预训练模型
# 查看输出层
print(pretrained_net.fc)
# 类别数
print(len(class_to_num))
# 可见此时pretrained_net最后的输出个数等于目标数据集的类别数1000。所以我们应该将最后的fc成修改我们需要的输出类别数 176
pretrained_net.fc = torch.nn.Linear(512, len(class_to_num))
print(pretrained_net.fc)
# 显示:

优化器使用AdamW,学习率0.0001,weight_decay设为0.001。
# 优化器选取
lr = 0.0001
optimizer = torch.optim.AdamW(pretrained_net.parameters(), lr=lr, weight_decay=0.001)
4 设置训练集和测试集
因为原始数据中,提供的测试集其实是验证集,需要提交结果,在线验证准确率。
所以,自己需要对建立的训练集Leaf_dataset再随机分割一下,分成训练集和测试集。
测试集可以数量远小于训练集,只是观察本地训练的效果。
# 在训练集中分出一部分测试集,以方便第一时间查看训练的效果,测试集数量可以很少。
# 随机拆分,设测试集比率ratio:
def to_split(dataset, ratio=0.1):
num = len(dataset)
part1 = int(num * (1 - ratio))
part2 = num - part1
train_set, test_set = torch.utils.data.random_split(dataset, [part1, part2])
return train_set, test_set
train_set, test_set = to_split(Leaf_dataset_train, ratio=0.01) # 测试集比率设0.01
print(len(train_set), len(test_set))
# 显示:

5 训练
设定数据增广方法
我们在leaf_dataset类中已经设置了Resize((224, 224)) + ToTensor()的基础transform方法,需要再设置训练时和 测试/验证 时所用的图像增广的方法。
该方法届时在训练及测试的函数中直接调用。
这里我再训练时只使用了随机水平、垂直翻转,似乎这两个增强方法对训练效果提升最明显。
此外Normalize在训练和测试时固定使用(和预训练模型相关,具体可参考动手学深度学习 图像增广 这一节。)
# 在leaf_dataset类中已经设置了Resize((224, 224)) + ToTensor()的基础transform方法,这里再设置训练时和测试\验证时所用的图像增广的方法。
# 该方法届时在训练及测试时直接调用。
# Normalize:
# 我们在使用预训练模型时,要和预训练时作同样的预处理。
# 如果你使用的是torchvision的models,那就要求: All pre-trained models expect input images normalized in the same way,
# i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224.
# The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225].
# 指定RGB三个通道的均值和方差来将图像通道归一化
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# Dataset中已默认有了 Resize((224, 224)) + ToTensor(),再设RandomHorizontalFlip和预训练模型用的normalize
train_augs = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
normalize
])
# 测试时的增强
test_augs = transforms.Compose([
normalize
])
训练
定义评估准确率和训练函数。函数中会调用之前定义好的数据增广方法。
# 定义train函数,使用GPU训练并评价模型
import time
# 测试集上评估准确率
def evaluate_accuracy(data_iter, net, device=None):
"""评估模型预测正确率"""
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
# 测试集上做数据增强(normalize)
X = test_augs(X)
if isinstance(net, torch.nn.Module):
net.eval() # 将模型net调成 评估模式,这会关闭dropout
# 累加这一个batch数据中判断正确的个数
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 将模型net调回 训练模式
else: # 针对自定义的模型(几乎用不到)
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将 is_training 设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train(train_iter, test_iter, net, loss, optimizer, device, num_epochs):
net = net.to(device)
print('training on ', device)
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
# 训练时使用数据增强
X = train_augs(X)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch+1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
设置好训练集、测试集、损失函数、batch_size、训练轮数,以及模型,开始训练。
def train_fine_tuning(net, optimizer, batch_size=128, num_epochs=20):
train_iter = DataLoader(train_set, batch_size)
test_iter = DataLoader(test_set, batch_size)
loss = torch.nn.CrossEntropyLoss()
train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
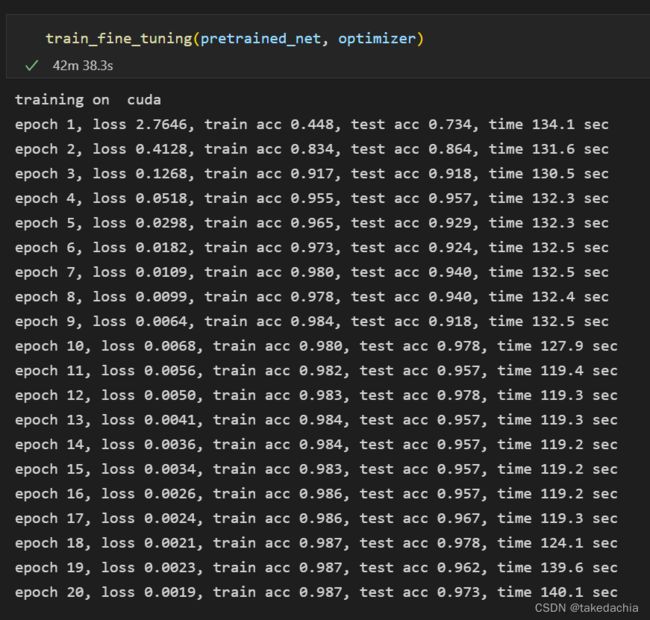
train_fine_tuning(pretrained_net, optimizer)
(我的设备:RTX3060)
6 保存模型
训练好后可以把模型储存到本地,方便重新读取和部署。
# pretrained_net 是 torchvision.models.resnet34() 类
path = 'net.pt'
torch.save(pretrained_net.state_dict(), path)
7 验证数据,上传
预测
我们现在需要在test.csv中预测类别
test_csv = pd.read_csv('../classify-leaves/test.csv')
print(len(test_csv))
test_csv
# 显示:

valid_iter是按顺序读取的验证集,可以查看一下第二张图片是不是对应验证集的第二张图片(18354.jpg,会有90度旋转)
# 查看一下验证集上的第1张图片
X, y = next(iter(valid_iter))
# 查看验证集第1个数据。valid_iter是按原顺序读取的。
plt.imshow(torch.transpose(X[1],0,2))
定义一个预测predict函数,返回一个List,包含了8800个预测的类别号,再将类别号映射为类别名。
# 定义预测函数
def valid_output(valid_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就用net的device
device = list(net.parameters())[0].device
with torch.no_grad():
y_output = []
for X, y in valid_iter:
# 验证集上做数据增强(normalize)
X = X.to(device)
X = test_augs(X)
net.eval() # 将模型net调成评估模式
y_hat = net(X).argmax(dim=1)
y_hat = y_hat.cpu().tolist()
y_output += y_hat
return y_output
output = valid_output(valid_iter, pretrained_net)
print(len(output))
# 输出8800
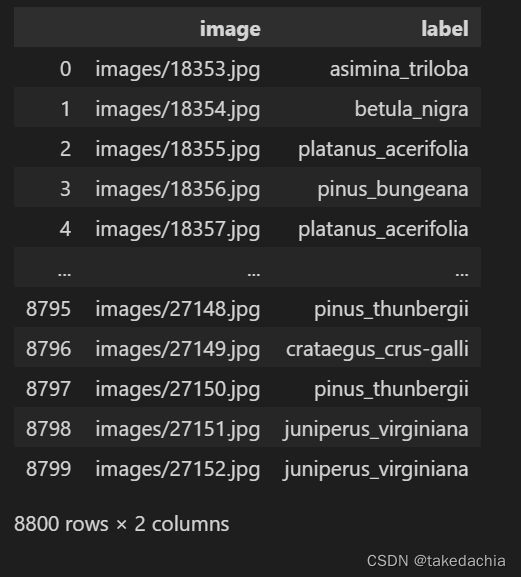
output_label = [class_to_num[i] for i in output] # 将类别号映射为类别名
test_csv['label'] = output_label
test_csv
上传
test_csv.to_csv('test.csv', index=False)
# 将生成的test.csv上传
将csv文件上传到Kaggle即可看成绩了。
我的成绩:

使用最简单的技术也可以达到95%。
简单的技术点总结
将本地的训练集再分成训练集和测试集(很小一部分)进行训练
数据增强:训练集上采用随机垂直、水平翻转
模型:使用表现较好的预训练过的模型,使用Resnet32
优化器:使用AdamW,lr=0.0001,weight_decay=0.001
(本文使用代码也可参考我的Github)