多模态语义检索 | 基于 MetaSpore 快速部署 HuggingFace 预训练模型
首先,附上 Github 链接LakeSoul:https://github.com/meta-soul/MetaSpore,可搜索公众号元灵数智,在底部菜单了解我们 - 用户交流获取官方技术交流群二维码,进群与业内大佬进行技术交流。
随着深度学习技术在计算机视觉、自然语言处理、语音理解等领域不断取得创新性突破,越来越多的非结构化数据被机器进行感知、理解和加工。这些进展主要得益于深度学习的强大表征学习能力,通过在海量数据上对深度模型进行预训练,使得模型捕捉到数据内在模式,进而对大量下游任务带来帮助。随着工业界和学术界投入越来越多精力在预训练技术研究上,陆续出现了 HuggingFace 和 Timm 这样的预训练模型分发仓库,预训练大模型红利正在被开源社区以前所未有的速度在释放着。
近年来机器建模和理解的数据形态逐渐从单模态向多模态演进,不同模态之间的语义鸿沟正在消弭,使得跨模态检索落地成为可能。以 OpenAI 的开源工作 CLIP 为例,在 4 亿图文数据集上对图文双塔模型进行预训练,将图像和文本之间的语义衔接了起来,学术界已经有不少研究人员在基于这项技术解决图文生成、检索等多模态问题。回到工业界来看,虽然前沿技术打通了多模态数据之间的语义鸿沟,但依然存在繁复的模型调优、离线数据处理、高性能的线上推理架构设计、异构计算以及在线算法应用落地等多个流程和挑战,这些都阻碍了前沿多模态检索技术的落地和普惠。
北京数元灵科技针对以上技术痛点,对模型训练优化、线上推理、算法实验等多个环节进行抽象统一,形成一套可以快速应用离线预训练模型到线上的解决方案。本文将向大家介绍,如何基于 MetaSpore 技术生态来使用 HuggingFace 社区预训练模型进行线上推理和算法实验,让预训练模型红利更充分释放到工业界、普惠到中小企业的具体业务中,并且我们会给出以文搜文和以文搜图两个多模态检索演示样例供大家参考。
1.多模态语义检索
本文介绍的多模态检索演示样例架构如下:
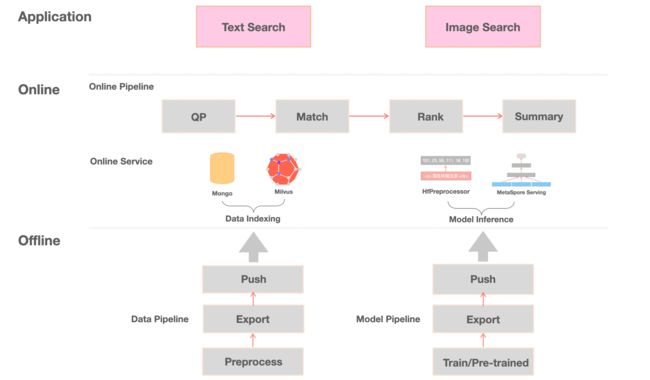
我们的多模态检索系统同时支撑以文搜文和以文搜图应用场景,含有离线处理、模型推理以及在线服务等核心模块:
1.离线处理,含有以文搜文和以文搜图不同应用场景的离线数据处理流程,包括模型调优、模型导出、数据索引建库、数据推送等。
2.模型推理,离线模型训练完毕之后,我们基于 MetaSpore Serving 框架,部署我们的 NLP、CV 大模型,MetaSpore Serving 可以帮助我们方便地进行在线推理、弹性调度、负载均衡,以及在异构环境中进行资源调度。
3.在线服务,我们基于 MetaSpore 在线算法应用框架,打造了一套完整可重用的在线检索服务,包括:前端检索 UI、多模态数据预处理、向量召回和排序算法、AB 实验框架等,同时支撑以文搜文和以文搜图场景,并可低成本迁移到其它应用场景。
一般来说,对于类似的多模态检索问题,HuggingFace 开源社区已经提供了很多优秀的基线模型,工业界的实际优化往往也是以此为起点。我们在以文搜文和以文搜图的线上服务中同样使用了 HuggingFace 社区的预训练模型,其中以文搜文基于我们调优的问答领域语义相似模型,以文搜图基于开箱即用的社区预训练模型。
这些社区开源预训练模型会被导出为通用 ONNX 格式,并载入 MetaSpore Serving 进行在线推理,下文会对模型的导出上线、数据的检索建库以及在线检索算法服务等内容展开详细的介绍。其中模型推理的部分,是标准化的 SAAS 服务,和业务的耦合性较低,感兴趣的读者可以参考我们之前的公众号文章:揭秘!新一代一站式机器学习平台MetaSpore的设计理念。
1.1 离线处理
离线处理主要涉及到上线模型的导出和载入以及文档库的索引建库和推送,大家可以按照下文逐步指引来完成以文搜文和以文搜图检索的离线处理工作,通过这两个样例大家也可以了解离线预训练模型是怎样实现在 MetaSpore Serving 上推理的。
1.1.1 以文搜文
传统的文本检索系统基于 BM25 之类的字面匹配算法实现,由于用户表达 query 查询词多种多样,往往会遇到查询词跟文档之间语义鸿沟的问题,比如用户把 “iPhone” 错拼为 “Ihone”、查询词极为长尾 “1~3月龄男婴秋季小尺码包包裤”等,传统文本检索系统会利用拼写纠错、同义词扩展、查询词改写等手段来缓解语义鸿沟问题,但未能从根本上解决这个问题。检索系统只有充分理解了用户查询词和文档的语义,才能够在语义层面满足用户的检索诉求,近年来随着预训练和表征学习技术不断进步,一些商业搜索引擎不断将基于表征学习的语义向量检索方法融入到检索生态中。
语义检索模型
本文介绍的以文搜文是一套完全基于语义向量检索的应用,我们以百科问答数据为基础,构建了一套问答语义检索系统。我们采用了 Sentence-BERT 模型作为语义向量表示模型,该模型通过监督或无监督方式来对双塔 BERT 进行微调,使得模型更适配检索任务,模型结构如下:

以文搜文问答检索在这里使用的是 query-doc 对称双塔模型,也即线上 query 的向量表示和离线 doc 的向量表示共用一个向量表示模型,因此一定要保证离线 doc 建库模型和在线 query 推理模型的一致性。这里使用了我们在开源语义相似数据集上调优的文本表示模型 sbert-chinese-qmc-domain-v1,离线建库时问答数据会被该模型表示为向量,在线检索时也是用该模型来把用户查询 query 表示为向量,这样保证了 query-doc 在同一个语义空间中,用户语义检索诉求可以用向量相似度量计算得到保证。
由于文本表示模型要在线上对 query 进行向量编码,因此我们需要导出该模型,以供在线服务使用。进入问答数据的建库代码目录,参照说明文档将模型导出,在脚本中会利用 Pytorch 的 Tracing 机制来完成导出。模型将被导出到 ./export 目录,导出内容主要有线上推理使用的 ONNX 模型和预处理模型 Tokenizer 以及有关配置文件,导出模型会被下文介绍的线上服务体系载入到 MetaSpore Serving 中进行模型推理(注:由于导出模型会被拷贝到云存储,需要在 env.sh 中配置相关变量)。
文本搜索建库
以文搜文检索基于百万级百科问答数据集来构建检索库,大家需要下载此数据并根据说明文档完成建库,问答数据会被离线模型编码为向量,然后建库数据将被推送到服务组件中。整个建库过程说明如下:
1.预处理,把原始数据转换为较为通用的 jsonline 格式以供建库使用;
2.构建索引,使用跟线上相同的模型 sbert-chinese-qmc-domain-v1 来索引文档(每行一个文档对象);
3.推送倒排和正排,把倒排(向量)和正排(文档字段)数据分别推送到各个组件服务端。
建库数据格式样例如下所示。离线建库完成后,各种数据被推送到对应的服务组件中,比如 Milvus会存储文档的向量表示、 MongoDB会存储文档的摘要信息,这些服务组件会被在线检索算法服务所调用来获取相关数据。
# 预处理
{"id": "0", "question": "人站在地球上为什么没有头朝下的感觉 ", "answer": "地球上重力作用一直是指向球心的,因此
只要头远离球心,人们就回感到头朝上。", "category": ["教育/科学", "理工学科", "地球科学"]}
# Milvus
{"id": 0, "image_emb": [-0.058228425681591034, -0.006109456066042185, -0.005825215484946966,...,-0.04344896227121353, 0.004351312294602394]}
# MongoDB
{"question" : "人站在地球上为什么没有头朝下的感觉 ", "answer" : "地球上重力作用一直是指向球心的,因此
只要头远离球心,人们就回感到头朝上。", "category": ["教育/科学", "理工学科", "地球科学"], "queryid" : "0" }
1.1.2 以文搜图
文本和图像对于人类来说很容易把它们的语义关联起来,但对机器来说却较为困难。首先从数据形式上来看,文本是基于字和词的离散 ID 型一维数据,而图像则是连续型的二维或三维数据;还有文本是人类主观的创作,其表达能力极为丰富,含有各种转折、隐喻等表述方式,而图像则是对客观世界的机器表示;总之,要将文本和图像数据之间的语义鸿沟打通远比上述以文搜文要难很多。传统以文搜图检索技术,一般会依赖图片的外部文本描述数据或者近邻检索技术,通过图像关联文本进行检索本质上就是将问题退化为了以文搜文,但这样也会面临诸多问题,比如图片关联文本如何获取、以文搜文本身准确度是否足够高等等。近年深度模型逐渐从单模态向多模态演进,以 OpenAI 的开源工作 CLIP为例,通过互联网上海量的图文数据对模型进行训练,将文本和图像数据映射到同一个语义空间中,使得基于语义向量的以文搜图技术落地成为可能。
CLIP图文模型
本文介绍的以文搜图基于语义向量检索来实现,以 CLIP 预训练模型作为双塔检索架构,由于 CLIP 模型已经在海量图文数据上对双塔的文本和图像侧模型进行了语义对齐训练,使其特别适合以文搜图场景,模型结构如下:

由于图片和文本数据形态不同,以文搜图检索使用了 query-doc 非对称双塔模型,离线建库时需要用到双塔的图像侧模型,线上检索时需要用到双塔的文本侧模型,最终在线检索时文本侧模型编码 query 后会对图像侧模型的建库数据进行查找,而图文之间的语义相关性则由 CLIP 预训练模型得到保证(通过在海量图文数据上预训练,模型能够将图文对在向量空间中不断拉近)。
这里我们需要把文本侧模型导出以供线上 MetaSpore Serving 推理。由于我们检索场景是基于中文的,所以选用了支持中文理解的 CLIP 模型。模型导出的具体操作参见文末说明文档,跟以文搜文类似,导出内容主要有线上推理使用的 ONNX 模型和预处理模型 Tokenizer,MetaSpore Serving 可以通过导出内容来载入模型推理。
图像搜索建库
以文搜图检索使用了 Unsplash Lite 图库数据,需要前往下载该数据并根据说明文档指引完成建库操作。整个建库过程说明如下:
1.预处理,指定图片目录,然后生成一个较为通用的 jsonline 文件供建库使用;
2.构建索引,使用 openai/clip-vit-base-patch32 预训练模型对图库进行索引,输出索引数据每行一个文档对象;
3.推送倒排和正排,把倒排(向量)和正排(文档字段)数据分别推送到各个组件服务端。
同以文搜文类似,离线建库完成后,相关数据会被推送到服务组件,这些服务组件会被在线检索算法服务所调用来获取相关数据。
1.2 在线服务
整套在线服务体系架构图如下:
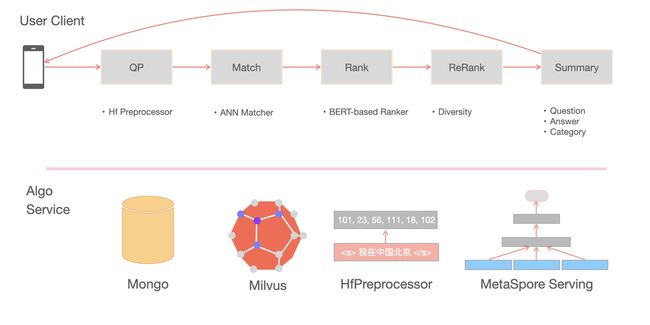
多模态检索线上服务体系,同时支撑以文搜文、以文搜图等应用场景,整套线上服务由以下几部分构成:
1.Query 预处理服务:对预训练模型的预处理逻辑(含文本/图像等)封装,以 gRPC 接口提供服务;
2.检索算法服务:含有 AB 实验切流配置、MetaSpore Serving 调用、向量召回、排序、文档摘要等整个算法处理链路;
3.用户入口服务:提供检索 Web UI 界面,便于用户对检索服务进行调试、问题追查。
从用户请求视角看,以上几个服务从后往前依次形成调用依赖关系,所以要把多模态样例搭建起来,就需要从前往后依次把各个服务先跑起来。当然做这些之前,要记得先把离线的模型导出、上线和建库先搞定哈!接下来我们会依此介绍在线服务体系中的各部分服务,按照下文引导一步一步把整个服务体系搭建起来,更多细节参见文末说明文档。
1.2.1 Query 预处理服务
我们知道深度学习模型一般都是基于张量(Tensor)的运算,不过 NLP/CV 模型往往有一个前置预处理部分,这部分的功能就在于把原始的文本和图片数据转换为深度学习模型可接受的张量形式。比如 NLP 类模型往往有一个前置的 Tokenizer 用来把字符串类型的文本数据转变为离散型的张量数据,还有 CV 类模型也有类似的处理逻辑会通过前置预处理来完成对输入图片的裁剪、缩放、变换等处理。一方面考虑到这部分预处理逻辑跟深度模型的张量推理是解耦的,另一方面深度模型的推理有基于 ONNX 独立的技术体系,所以我们把预处理这部分逻辑拆解了出来。
在这里我们重点针对 HuggingFace NLP/CV 模型的预处理逻辑进行了拆解,目前 NLP 预处理 Tokenizer 已经整合进入了 Query 预处理服务。我们以较为通用的约定进行拆解,用户只需要提供预处理逻辑文件实现载入和预测接口,并导出必要的数据和配置文件,就可以被载入到预处理服务中。后续 CV 预处理逻辑也将以这种方式被集成进来。
目前预处理服务对外提供 gRPC 接口调用,被检索算法服务中的 Query 预处理(QP)模块依赖,用户请求到达检索算法服务后会转发到该服务完成数据预处理,然后再继续后面的处理。关于预处理服务如何启动、离线导出到云存储的预处理模型如何进入服务以及如何调试服务等细节可以参考说明文档。
为了进一步提升模型推理的效率和稳定性,我们正在 MetaSpore Serving 中实现 Python 预处理子模块,可以通过用户指定的 preprocessor.py 提供 gRPC 服务,完成 NLP 中的 Tokenizer 或者 CV 相关的预处理,将请求转成深度模型可处理的 Tensor,然后由 MetaSpore Serving 后续子模块进行模型推理。
这里给出我们在 GitHub 上的代码实现:https://github.com/meta-soul/MetaSpore/compare/add_python_preprocessor
1.2.2 检索算法服务
检索算法服务是整个在线服务体系中的核心,负责实验的分流,预处理、召回、排序等算法链组装以及依赖组件服务的调用等。整个检索算法服务基于 Java Spring 框架开发,同时支持以文搜文和以文搜图多模态检索场景,由于内部进行了较好的抽象和模块化设计,灵活性较高,可以低成本的迁移到类似的应用场景中。
接下来简单地向大家介绍如何配置环境把检索算法服务搭建起来,更多细节参见说明文档:
1.安装依赖组件,使用 maven 来安装 online-serving 组件
2.检索服务配置,拷贝模版配置文件并根据开发/生产环境对里面 MongoDB、Milvus 等配置进行替换。
3.安装配置 Consul,我们通过 Consul 来实时同步检索服务的配置,包括实验的切流、召回参数、排序参数等都可以通过 Consul 实时配置。当前以文搜文和以文搜图应用的配置参数见项目中的配置文件,其中预处理和召回阶段的参数 modelName 就是我们在离线处理中导出的相应模型。
4.启动服务,上述配置完成后可以通过入口脚本来启动检索服务。
服务启动后就可以进行测试啦!举例来说,对于 userId=10 的用户,想要查询 “如何补办身份证”,访问以文搜文检索服务:
curl -H "Content-Type: application/json" -X POST -d '{"query":"如何补办身份证"}' http://localhost:8080/qa/user/10
将得到如下检索结果:
{
"queryModel" : {
"query" : "如何补办身份证"
},
"searchItemModels" : [ [ {
"id" : "823067",
"originalRetrievalScoreMap" : {
"ann_matcher" : 0.9867960810661316
},
"finalRetrievalScore" : 3.9989876453053745,
"originalRankingScoreMap" : {
"dummy" : 3.9989876453053745
},
"finalRankingScore" : 3.9989876453053745,
"score" : 3.9989876453053745,
"summary" : {
"question" : "怎样补办身份证 ",
"answer" : "去户口所在地的公安局办理
",
"category" : [ "生活", "美容/塑身", "化妆" ]
}
}, ...] ]
}
1.2.3 用户入口服务
考虑到检索算法服务是 API 接口形式,较难对问题定位追查,尤其对于以文搜图场景能够直观的展现检索结果便于检索算法的迭代优化。为此我们针对以文搜文和以文搜图检索场景提供了一个轻量的 Web UI 界面,为用户提供了一个搜索输入框和结果展示页面。服务基于 Flask 开发,可以方便的集成其它检索应用,该服务会调用检索算法服务并把返回结果展示到页面中。
服务安装和启动也很方便,启动完成后,前往 http://127.0.0.1:8090 去查看搜索 UI 服务是否运行正常,具体细节参考文末说明文档。
多模态系统演示
当按照上述指引完成离线处理和在线服务环境配置后,我们就可以启动多模态检索服务啦!
可以点击链接下滑至末尾查看视频教程
多模态语义检索 | 基于 MetaSpore 快速部署 HuggingFace 预训练模型 (qq.com)
2.1 以文搜文—百科问答
我们进入到以文搜文应用的入口,来探究一下问答语义检索系统,输入 “给宝宝起名字”,检索返回前 3 个结果都是关于给宝宝起名字相关的问答内容:

再让我们把检索词加强一下,添加一个性别属性的约束,改为 “给男孩子宝宝起名字” 来查询一下,检索结果可以看到有男性宝宝起名字有关的内容:

我们在继续对检索词添加一个属相约束,改为 “给男孩子宝宝起名字,属牛”,可以看到返回第一条结果就是关于牛年男宝宝起名字的内容:

在上述示例中,我们围绕“给宝宝起名字”这个主题,不断对检索词添加约束,检索诉求越来越精确,语义检索系统都能够返回相关内容。
2.2 以文搜图—图库检索
我们再进入以文搜图应用的入口,先来输入 “猫” ,可以看到返回结果前 3 位都是猫:
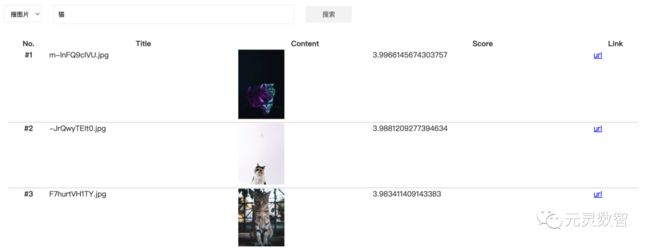
如果我们给“猫”加一个颜色约束,来检索 “黑猫” 的话,可以看到确实返回结果是黑色的猫:

我们进一步对检索词加强约束,改为 “黑猫在床上”,返回结果中含有黑色猫爬在床上的图片:

在上述示例中,我们对猫进行了颜色以及场景修饰后,依然可以通过以文搜图系统找到相关图片。
结束语
前沿预训练技术打通不同模态之间的语义鸿沟,而 HuggingFace 社区又极大的降低开发人员使用预训练模型的成本,再结合我们提供的 MetaSpore 线上推理和线上微服务的技术生态,预训练模型不再停留于离线的浅尝辄止,而是可以真正实现从前沿技术到工业场景的端到端落地,充分释放预训练大模型的红利!未来我们会不断完善优化 MetaSpore 技术生态:
1.更自动化、更广泛的接入 HuggingFace 社区生态,近期我们会发布一套通用模型上线机制,使得 HuggingFace 生态接入更为方便,同时后续会把预处理服务集成到在线服务中;
2.多模态检索离线算法优化,针对多模态检索场景,我们会持续迭代优化离线算法组件,包含文本召回/排序模型,图文召回/排序模型等,提升检索算法的精度和效率。
本文中相关的代码、参考文档,请访问链接:http://github.com/meta-soul/MetaSpore/blob/main/demo/multimodal/online/README-CN.md
部分图片来源:
https://github.com/openai/CLIP/raw/main/CLIP.png
https://www.sbert.net/examples/training/sts/README.html
官方资料
GitHub:
LakeSou: https://github.com/meta-soul/LakeSoul
MetaSpore: https://github.com/meta-soul/MetaSpore
官网:元灵数智-云原生一站式数据智能平台-北京数元灵科技有限公司 (dmetasoul.com)
官方交流群:微信群:关注公众号,点击“了解我们-用户交流”或扫描下方二维码

Slack:https://join.slack.com/t/dmetasoul-user/shared_invite/zt-1681xagg3-4YouyW0Y4wfhPnvji~OwFg